
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- conjugate pseudo label paper
- CGAN
- CoMatch
- Meta Pseudo Labels
- Pix2Pix
- mme paper
- Pseudo Label
- simclrv2
- Entropy Minimization
- tent paper
- UnderstandingDeepLearning
- 최린컴퓨터구조
- WGAN
- cifar100-c
- SSL
- mocov3
- GAN
- shrinkmatch
- dcgan
- semi supervised learnin 가정
- 컴퓨터구조
- shrinkmatch paper
- BYOL
- 백준 알고리즘
- CycleGAN
- ConMatch
- 딥러닝손실함수
- remixmatch paper
- adamatch paper
- dann paper
- Today
- Total
Hello Data
APE(2020) 논문리뷰 본문
논문의 풀 제목은 Attract, Perturb and Explore: Learning a Feature Alignment Network for semi-supervised Domain Adaption이다. 저자의 github에서 APE로 되어있기에 이렇게 표기했다.
https://arxiv.org/pdf/2007.09375.pdf
Introduction
이 논문에서는 기존 UDA, SSDA 방식들의 문제점을 지적하는데, source distribution을 사용하여 분류하는 방식을 배우는 과정에서 target distribution에서 source와 비슷한 이미지를 attract할 수 있다고 한다. 이 부분은 당연할 수 있지만 반대로 생각한다면 그렇지 못한 feature들이 대부분일 것이고 이것을 줄이는 것이 inter-domain discrepany라고 할 수 있다(보통 aligning 이란 표현을 많이 사용하는 거 같다).
SSDA setting 에서는 약간의 labeled target data가 있는데 이러한 데이터는 align할 수 있지만 여전히 unlabeled 데이터에 대해서는 unalign한다고 한다. 이러한 것을 target domain내에서도 discrepancy가 일어난다고 하며 intra-discrepancy라고 계속 표현된다. 따라서 논문에서는 이러한 unalign 된 target data들을 맞추는 것이 목적이며 달성하기 위해 수행하는 방법이 attraction, perturbation, exploration이란 방법이다. 지금까지는 intra discrepancy 를 다루는 방법들이 많이 다루어지지 않았다고 하며 이를 집중한다.
Intra-domain Discrepancy
intra domain discrepancy 란 distribution 내 subdistribution간의 차이라고 할 수 있다(사실 target distribution도 iid로 어느 한 분포에서 샘플링됐으므로 unaligned 된 feature들은 outlier라고 쉽게 생각할 수도 있다. 그러나 여기서는 outlier라고 취급하지 않고 이러한 데이터들도 최대한 source distribution에 맞게 align할려고 노력한다).
하나의 domain 내의 데이터들은 데이터들간의 큰 상관관계가 있으므로 intra target domain discrepancy향상에는 큰 도움이 되지 않으며 오히려 악화시킬 수 있다. 그리고 target domain내의 labeled 데이터를 활용하는 것 역시 label 데이터는 결국 true 값이 있으므로 source space에 aligned 될 것이지만 이러한 것이 unaligned unlabeled 를 잘 align하는 것을 보장하지 않는다.

intra domain discrepancy 에 대한 시각화이다. 빨간색은 source data이고 파란색은 target data이다. 위 a, b이미지만 설명해보면, a는 UDA 를 적용하고 b는 SSDA를 적용했을 때, 적은 수의 label target data를 사용하더라도 neighbor들을 attract하고, aligned, unaligned distribution들을 seperate할 수 있다고 한다.
기존의 UDA방법으로는 SSDa에 적용할 수 없다고 하는데, domain adaptation의 목적이라면 target domain, source domain간의 차이를 줄이는 것인데 대부분의 error는 이러한 unaligned target subdistribution으로부터 온다고 한다(약간 다른 주제이긴한데 semi supervised 논문에서는 entropy minimization을 사용하기 보다는 pseudo label을 생성하는데, 만약 entropy minimization을 사용한다면 고차원에서의 target subdistribution들이 부정확하게 분류할 가능성이 크기 때문에 잘 사용하지 않나 싶다). 따라서 결국 SSDA의 목적은 이러한 unaligned intra subdistribution을 어떻게 잘 줄이느냐에 달려있다고 한다.
Method

전체 프레임워크이고 그림만 보면 어지럽다.. 우선 labeled 데이터에 대해서는 cross entropy를 수행한다(오른쪽 아래그림). p는 각 클래스에 대한 prototype(벡터)이며, 각 클래스마다 존재하니 K개의 prototype이 있다.
Attraction
attraction 목적은 unaligned target subdistribution을 aligned target subdistribution 으로 align하는 것이다(UDA 보다 SSDA가 이러한 것이 더 중요할 거 같다). 따라서 이를 위해 distribution차이를 measure 하는 것인데, 적은 수의 labeled target 데이터들을 사용해 intra domain discrepancy를 줄이는 것은 쉽지 않다고 말한다. 그런데 위에 언급한 것처럼 labeled target data는 이미 source distribution에 aligned 됐을 가능성이 높은데 따라서 source data도 활용해 discrepancy를 줄일 수 있다. 이를 줄이는 measure 로는 MMD(Maximum Mean Discrepancy)를 사용하며 이를 합리적으로 계산하기 위해 kernel function을 사용한다.
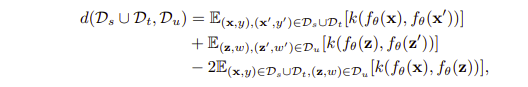
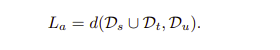
총 3개의 거리를 측정하는데 결국 세번째 term에 있는 거리를 줄이는 것이 목적이라고 할 수 있다. kernel 함수가 적용된 것을 확인할 수 있다.
Perturbation
기존의 UDA 방식은 adversarial 방식으로 훈련하는데 이는 모델이 source, tagret인지 구분 못하도록 하는 것이다. 그러나 이 방식은 효율적이지 못하다고 하는데, 그 이유는 계속 설명한 것처럼 labeled target 데이터들은 source쪽으로 aligned 될 것이지만 그렇지 않은 unlabeled target 데이터들은 seperated 되기 때문에 unaligned 된 target 데이터들과 aligned 된 target 데이터들에 대해 같이 perturbation을 주는 것은 좋지 않다고 말한다(매우 합리적인 주장같다). 따라서 논문에서는 aligned, unaligned 된 target 데이터들에 대해 intermediate region 으로 이동시키기 위해 perturbation을 준다고 말하며 위에서 언급한 class prototype역시 이동시킨다고 한다. 이러한 perturbation을 주는 방법으로는 정확하게 이해는 하지 못했지만 aligned target feature의 high entropy방향으로 이동하고 prototype과 먼 feature에 대해서는 prototype쪽으로 이동시키는 방향으로 perturbation을 준다고 한다.
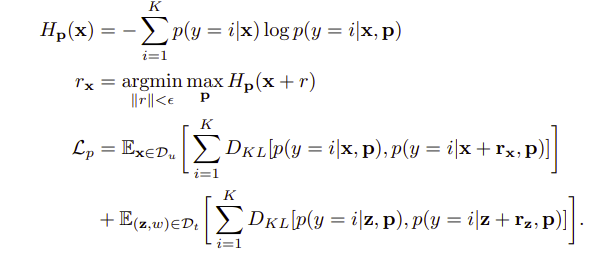
수식을 살펴보면 위에는 Entropy가 정의되어 있고, r은 perturbation이며, perturbation이 추가된 이미지와 그렇지 않은 이미지간의 kl divergence를 수행하는 것을 알 수 있다.
Exploration
기존의 수행했던 attraction방법은 target subdistribution들을 align하는 것이 목적이고, prototype을 직접적으로 modulate 하지 않는다고 한다. 따라서 exploration은 target 값들에 대해 일정 threshold보다 낮은 데이터들을 고른 후 align시키는 방법이다. 뭔가 attraction, perturbation에서는 분포를 맞추고, 이동시키고 exploration에서는 이러한 데이터들에 대해 마지막에 align시키는 방식같다.
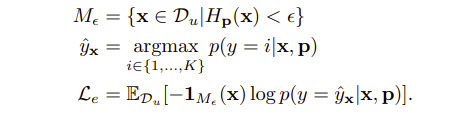
최종 loss는 위의 4개 loss를 모두 가중합한다.
Result
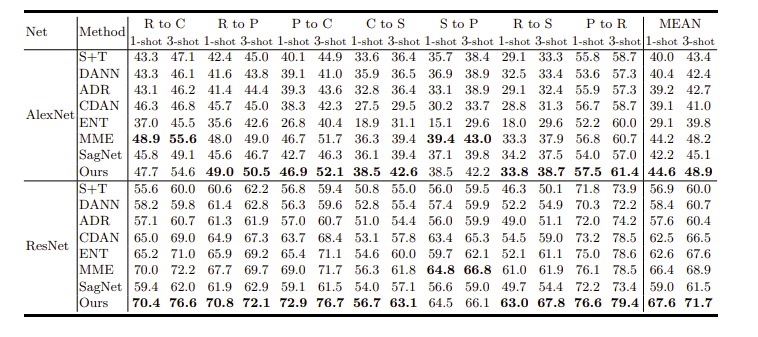
DomainNet에 대한 정확도이다.
'Domain Adaptation' 카테고리의 다른 글
| MME(2019) 논문리뷰 (0) | 2024.03.12 |
|---|---|
| DANN(2016) 논문리뷰 (0) | 2024.03.12 |

