
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 컴퓨터구조
- CGAN
- adamatch paper
- CycleGAN
- Pix2Pix
- semi supervised learnin 가정
- Pseudo Label
- SSL
- cifar100-c
- simclrv2
- remixmatch paper
- tent paper
- shrinkmatch
- WGAN
- shrinkmatch paper
- dann paper
- conjugate pseudo label paper
- 딥러닝손실함수
- Entropy Minimization
- 백준 알고리즘
- mme paper
- UnderstandingDeepLearning
- mocov3
- BYOL
- ConMatch
- GAN
- Meta Pseudo Labels
- dcgan
- 최린컴퓨터구조
- CoMatch
- Today
- Total
Hello Computer Vision
Train/Valid/Test 데이터에 대해 자세히 알아보기 본문
딥러닝 배울 때부터 많은 강의에서 오버피팅을 방지하는 방법으로는 데이터셋을 단순히 Training / Test 데이터 셋으로 나누는 것이 아니라 Train / Valid / Test 데이터 셋으로 나누는 것이라고 한다. 사실 그때는 그냥 그런갑다 하고 배웠는데 지금은 조금 제대로 알고 넘어가야한다고 생각해 정리해보려고 한다. 여러 글들을 보고 제 개인적인 이해 입니다.
Train data
가장 간단하다. 모델을 훈련하기 위해 사용되는 데이터이다. 데이터셋에서 80%의 데이터를 모델에 훈련하는데 사용한다. 그러나 Training 정확도와 에러가 이상적이더라도 실제 환경에서 성능이 잘 나올 확신은 없기 때문에 이를 잘 일반화하는 것이 중요하다.
Test data
훈련에 필요한 80% 데이터를 제외한 20%가 Test에 보통 쓰인다. 이러한 Test데이터는 실제 학습에 아무런 영향이 없다.
Valid data
그리고 검증 셋이다. 이 valid 데이터는 Training 의 일부를 맡고 있으며 일반적으로 전체 데이터를 1로 보았을 때 6:2:2 의 비율을 가지고 있다. 검증 데이터셋은 Training data의 일부이지만 학습에는 전혀 이용되지 않는다.
Valid 사용 이유
이제 본격적인 궁금증을 해소해볼 시간이다. 일반적으로 밑의 이미지처럼 나누는데 왜 이렇게 나누는 걸까?
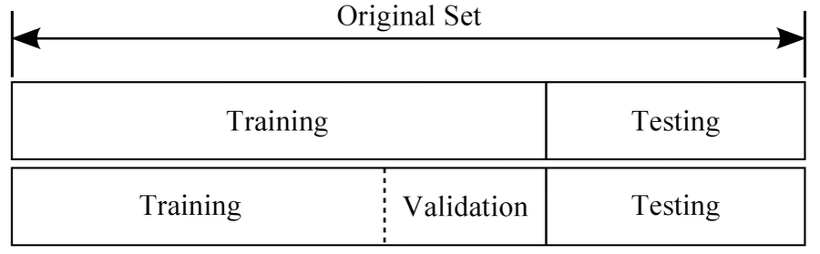
1) Training / Test 나눈 경우
앞에서 이야기 했던 것처럼 Train 데이터는 모델을 훈련시키기 위해 사용되는 용도이며 Test데이터는 실제 세상에서도 내 모델이 잘 작동할지 시험하는 용도이다. 예를 들어 training acc : 90%, test acc : 45%가 나왔다고 해보자. 그렇다면 모델의 성능은 형편없는 것이며 Test acc를 올리기 위해 여러 하이퍼 파라미터를 고쳐본 결과 test acc가 90%가 나왔다고 쳐보자. 그러나 이것은 잘못된 과정이다. 우리는 실제 세계에서의 데이터들을 잘 맞추기 위해 Test데이터를 활용하는 것이지 Test acc를 올리는 것이 목적이 아니기 때문이다. 그런데 목적을 까먹고 test acc를 올리는 것에 집착하게 된다면 우리가 가장 우려하는 Test 데이터에 오버피팅 되는 현상이 일어나는 것이다.
2) Training / Valid / Test 나눈 경우
위에서 설명한 것처럼 Training / Test 이렇게 나눈다면 우리가 실제로 만들고자 하는 이상적인 모델을 만들 수 없다. 그렇다면 Training / Valid / Test 나눈 경우 어떻게 학습이 진행될까?
사실 훈련과정은 Training / Test 나눈 경우와 똑같이 진행된다. 그러나 다른 점이라고 한다면 Training / Test를 이용한 한번의 학습이 이번에는 Training / Valid 를 이용해 여러번 진행된다는 것이다. 우선 우리는 Test 데이터는 우리 모델이 실제의 unseen 데이터에 얼마나 잘 적응하는지 알아보는 것이기 때문에 학습에 이용되지 않으며 이러한 Test acc를 올리기 위해 노력하는 것은 되려 Test 데이터에 오버피팅 되는 것이라 말했다. Valid 데이터 역시 학습에 이용되지 않으나 우리는 valid acc를 올리는데 노력할 것이다. 이러한 과정에 있어서 Training / Valid 데이터 셋은 계속 사용되지만 Test 데이터는 끝까지 사용되지 않는다. 여기서의 Test 데이터는 완전 마지막의 모델 성능을 위한 도구이기 때문이다.
그러나 여기서는 중요한 가정들이 필요하다.
1. Test set은 실제 세계의 데이터들을 잘 대표해야한다.
2. Validation set은 Test set 을 잘 대표해야 한다.
이러한 가정들인 것이다. 잘 대표한다는 것은 분포가 같다고 쉽게 생각할 수 있다. 그러나 잘 대표한다는 것은 어렵기 때문에 이렇게 Cross validation이라는 방법을 이용하기도 하는데 밑의 그림과 같다.
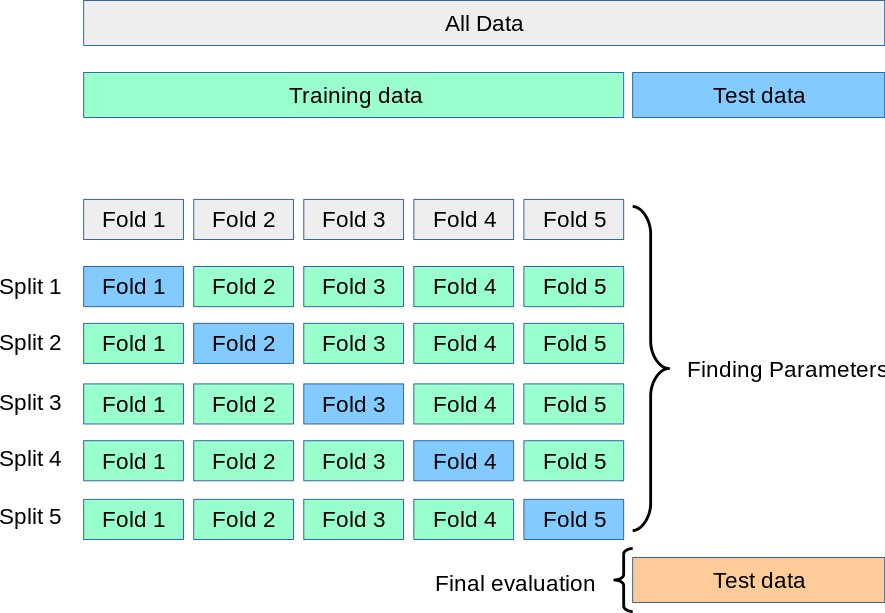
파란색 상자가 valid set이며 초록색이 training 데이터라고 할 수 있으며 이렇게 잘게 쪼개고 모두다 학습에 이용된다(valid는 학습에 이용되지 않고 기록에만 이용된다)
결론
나만의 이해를 위해 조금 두서 없이 써봤는데 다시 한번 이러한 방법에 대해 요약해보자면
Valid 데이터를 이용하는 것은 나의 모델이 실제 세계의 데이터를 잘 반영하는지 실험하는 것이라고 할 수 있다. 물론 이 과정에서 여러 파라미터를 변경해볼 수 있다. 그리고 최종적으로 test 데이터를 이용해 내 모델의 성능을 체크해본다.
Reference
https://www.youtube.com/watch?v=GtLe9Z2No28
'딥러닝' 카테고리의 다른 글
| torch.triplet margin distance loss 살펴보기 (0) | 2023.05.04 |
|---|---|
| Positional Encoding 공부해보기 (0) | 2023.04.04 |
| Zero shot learning에 대해 공부해보기 (0) | 2023.04.02 |
| CNN의 Inductive Bias (0) | 2023.03.23 |
| CNN 에서의 subsampling (0) | 2023.03.09 |



