
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- ConMatch
- remixmatch paper
- WGAN
- Entropy Minimization
- cifar100-c
- adamatch paper
- 컴퓨터구조
- UnderstandingDeepLearning
- SSL
- 딥러닝손실함수
- CGAN
- shrinkmatch
- CycleGAN
- GAN
- semi supervised learnin 가정
- Pix2Pix
- CoMatch
- mocov3
- simclrv2
- BYOL
- tent paper
- shrinkmatch paper
- Meta Pseudo Labels
- conjugate pseudo label paper
- 최린컴퓨터구조
- 백준 알고리즘
- Pseudo Label
- mme paper
- dann paper
- dcgan
- Today
- Total
Hello Data
[머신러닝] Boosting이란? 본문
출처 : https://www.youtube.com/watch?v=GciPwN2cde4
이전 학교에서 데이터사이언스 과목을 들을 때 XGboost나 Gradient Boosting에 대해 가벼운 내용이 나왔던 걸로 기억한다.
Boosting이란?
그리고 이 기법들은 공통으로 Boosting이란 단어가 들어가있다.
boost라는 용어의 뜻은 격려, 증가 라는 뜻을 가지고 있다.(카트라이더에서의 부스터 생각하면 편하다)
여러 개의 모델을 순차적으로 구축하여 최종적으로 합친다는 것이 부스팅의 핵심 아이디어이다. 여러개의 모델을 합친다는 점에서 앙상블이고
큰 특징이라면 모델들을 여러개만들고 한번에 합치는 것이 아닌 순차적으로 구축한다는 것이 핵심이다.
순차적으로 구축하는만큼 그 전 단계에서의 모델의 단점을 보완하면서 모델이 점차 강해지는 것이 특징이다.
이러한 방법을 사용한 모델들이 여러개 있는데 몇개만 소개해보자면 AdaBoost(Adaptive Boosting)과 gradient Boosting이 있는데 이번에는 AdaBoost만 알아보려고한다.
AdaBoost이란?
Training error가 큰 관측치의 선택확률(가중치)를 높이고 training error가 낮은 관측치의 선택확률 낮춘다. --> 오분류된 관측치에 보다 집중
이렇게 조정된 가중치 기반으로 다음 단계에서 사용될 trainign dataset 구성 (순차적)
초기 가중치는 각 데이터마다 같은 가중치를 가지며 훈련을 순차적으로 거듭할 수록 틀린 데이터에 대해서 추가 가중치를 부여한다.
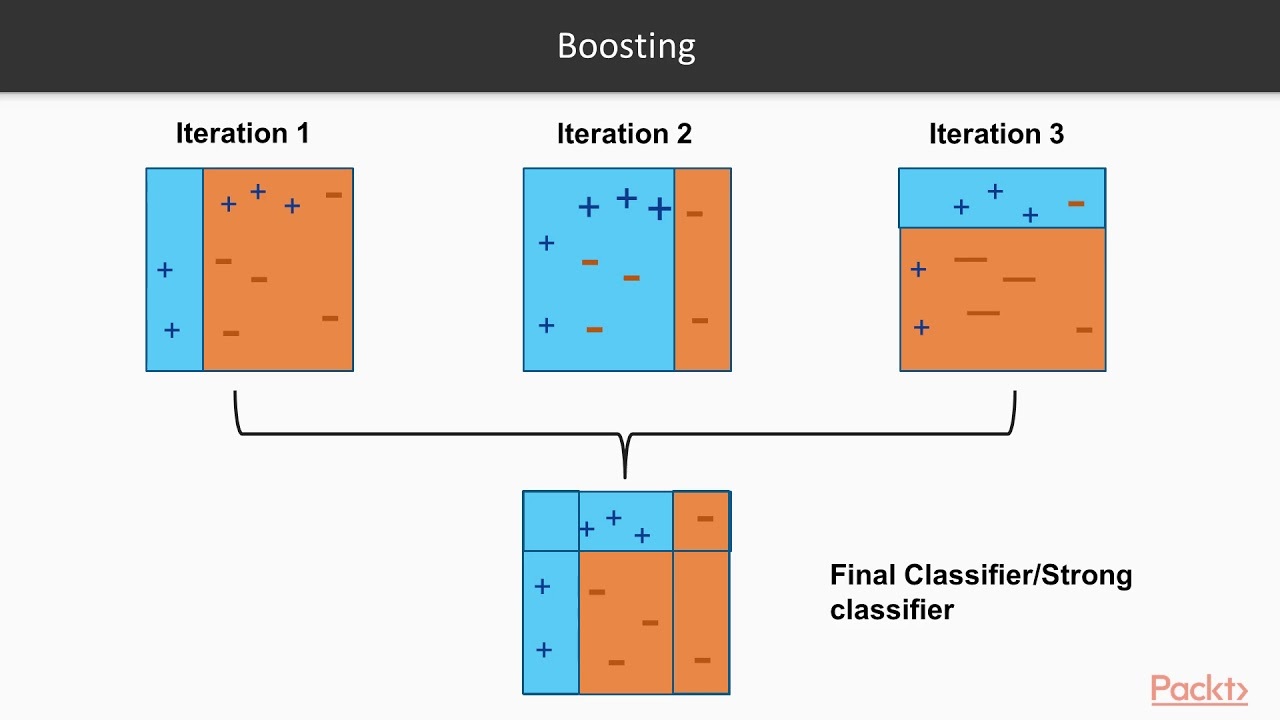
위 이미지의 데이터는 '+' 5개, '-' 5개로 구성되어있음을 알 수 있고 가중치는 각각이 0.1을 부여받는다.
첫번째 훈련에서 오 분류된 '+'3개는 가중치가 0.1보다 더 부여되는 것이다.
그리고 추가된 가중치를 이용해 두번째 훈련을 수행하고 이번에 오분류된 '-' 3개 데이터의 가중치가 추가된다.(정분류된 가중치는 그대로이다.)
그리고 이렇게 순차적으로 만들어진 모델 결과들을 합쳐(뒤에 모델일 수록 성능이 좋으므로 추가 모델에 대한 가중치를 부여한다.)
최종적인 모델을 만드는 것이다.(각 데이터에 대한 가중치를 갱신하는 과정과 모델 가중치를 구하는 과정은 생략하였습니다.)
이전에 알아보았던 Bagging과 Boosting 모두 여러 모델을 활용하지만 가장 큰 차이점이라 한다면
Bagging 같은 경우 병렬적으로 모델을 수행해 결과를 알지만 Boosting경우 순차적으로 모델을 강화시켜 결과를 출력하는 것이 차이점이다.(Parallel vs Sequential)
'머신러닝' 카테고리의 다른 글
| [머신러닝] XGBoost 에 대한 이해 (0) | 2023.02.14 |
|---|---|
| [머신러닝] Gradient Boost 공부해보기 (GBM) (0) | 2023.02.05 |
| [머신러닝]KFold, StratifiedKFold에 대한 이해 (0) | 2023.01.28 |
| [머신러닝]랜덤 포레스트(Random Forest)에 대한 이해, 파이썬 코드 (0) | 2023.01.28 |
| [머신러닝] bootstrap, bagging이란? (0) | 2023.01.28 |



