
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- semi supervised learnin 가정
- dcgan
- CoMatch
- GAN
- shrinkmatch paper
- WGAN
- Pseudo Label
- Entropy Minimization
- CGAN
- ConMatch
- 컴퓨터구조
- mme paper
- adamatch paper
- cifar100-c
- Meta Pseudo Labels
- UnderstandingDeepLearning
- 딥러닝손실함수
- conjugate pseudo label paper
- 최린컴퓨터구조
- remixmatch paper
- mocov3
- SSL
- 백준 알고리즘
- simclrv2
- tent paper
- shrinkmatch
- dann paper
- CycleGAN
- BYOL
- Pix2Pix
- Today
- Total
Hello Data
[머신러닝] XGBoost 에 대한 이해 본문
참고 영상 : 유튜브영상
지난번 Gradient Boost 에 이은 이번에는 XGBoost이다.
XGBoost는 다시 말하면 기본적으로 Gradient Boost이다. 그렇지만 기존 방법과 차별화된 점은 더 많은 데이터 수용 가능하며
이를 빠르게, 병렬처리하는 과정을 나타낸 것이 XGBoost라고 할 수 있다.(여기서 X는 Extreme을 뜻한다)
나온 배경
기존 의사결정나무같이 Exact greedy 알고리즘의 장점이라고 하면 모든 해를 다 탐구하기 때문에 항상 정확한 해를 찾을 수 있다.
단점이라고 한다면 분산처리를 할 수 없으며 모든 데이터가 메모리에 들어가지 않는다면 문제가 생긴다.
이러한 주된 문제점들을 해결하기 위해서 XGBoost는 어떠한 방법을 사용할까?
바로 bucket을 이용하는 것이다.
조금 더 자세히 설명해보자면 기존 gradient boosting의 경우 모든 데이터의 gradient를 계산하였다면
XGBoost의 경우 일정 데이터수만큼 그룹으로 나누어(bucket) 각각의 gradient를 따로따로 진행하는 것이다.
이렇게 진행한다면 일단 일일이 gradient를 계산하는 것보다는 연산량이 줄어들 뿐더러 분산처리가 가능하다는 장점이 있다.
물론 이것은 approximation하는 것이기 때문에 exact greedy방법보다는 성능이 떨어지는 경우도 있지만 이것의 장점이라고 한다면
아무래도 비슷한 성능을 냄과 동시에 많은 데이터를 수용할 수 있다는 점에 있다.
또한 이렇게 split을 계속하는 과정에서는 Global variant vs Local variant 로 나눌지 방법이 나뉘어 지는데
global variant경우 트리가 깊어질 수록 탐색해야하는 그룹의 수(bucket)이 줄어들며
local variant 경우 트리가 깊어질 수록 그룹 안에 있는 변수의 수가 줄어든다.

여기서 eps나타내는 것은 1/eps가 총 분할 수라고 보면 된다.
성능을 확인해보자면 global variant - eps 0.05, local variant -eps 0.3 으로 잡았을 때 기존의 greedy알고리즘과
성능이 비슷하다는 것을 확인할 수 있다. 주목할 부분은 global variant로 잡을 때는 더 많이 split해야 성능이 나오는 것을 확인할 수 있다.
XGBoost의 또 다른 장점은 무엇이 있을까?
결측치에 대해서 효율적으로 다룬다.
우리가 실험적으로 하는 데이터셋에는 결측치가 거의 존재하지 않지만 실생활 데이터들을 살펴보면 결측치가 상당히 많다.
그렇기 때문에 이를 어떻게 다루는가도 상당히 중요한데 이 XGBoost에서는 결측치가 있다면 학습을 통해 default direction을 찾아내
이 방향으로 보내버림으로써 효율적으로 다룬다.
이 외에도 메모리 관련해서 장점들이 많다고는 하지만 하드웨어적인 부분은 넘어가겠습니다.
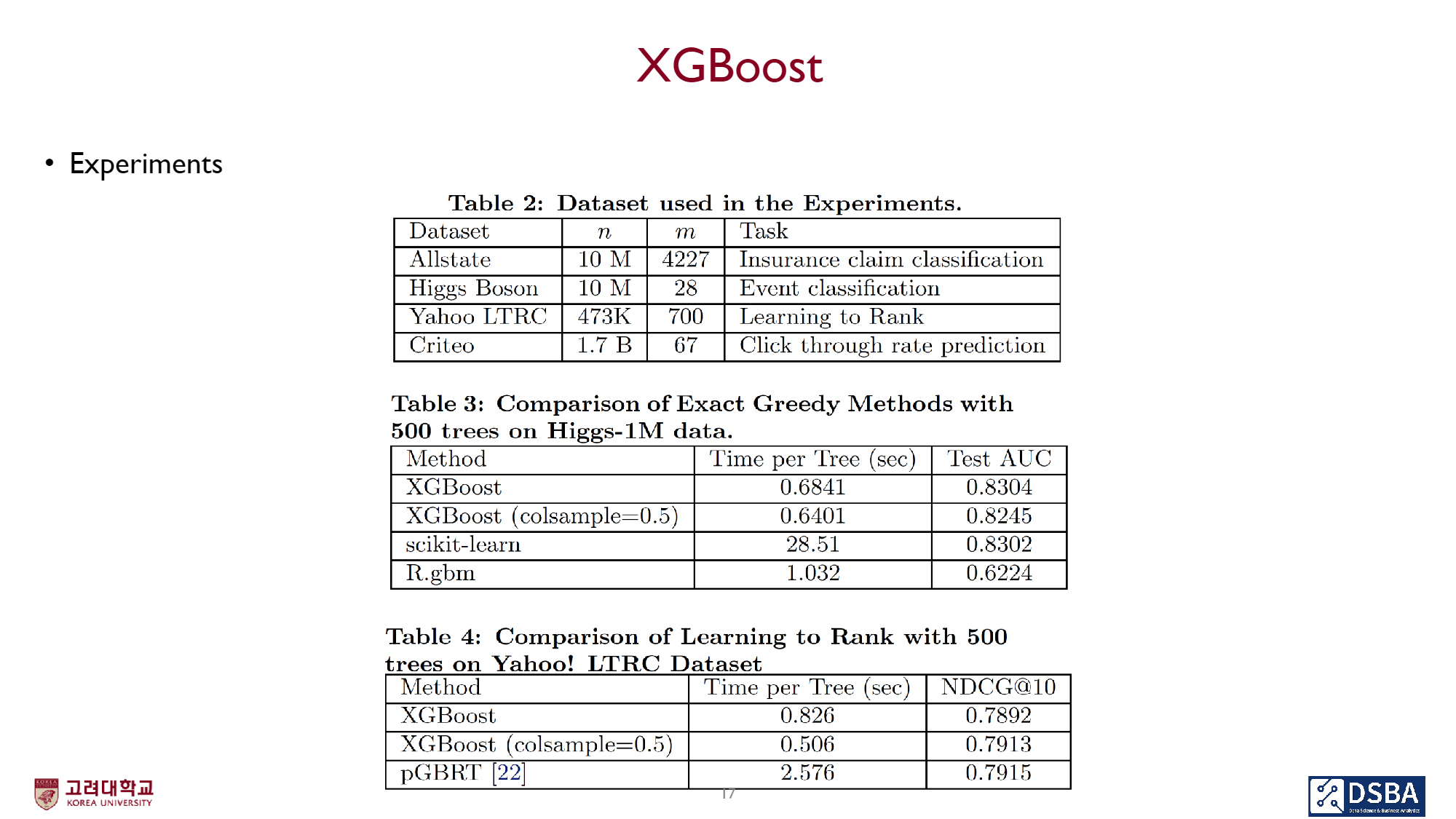
결과를 한번 살펴보자면 줄어드는 시간에 비해 성능은 비슷하게 나옴을 확인할 수 있다. 이는 이 알고리즘의 효율성이 좋다는 것을 나타낸다.
'머신러닝' 카테고리의 다른 글
| 머신 러닝 공부 (0) | 2023.09.09 |
|---|---|
| batch size 와 mini-batch size의 차이점 (0) | 2023.04.11 |
| [머신러닝] Gradient Boost 공부해보기 (GBM) (0) | 2023.02.05 |
| [머신러닝] Boosting이란? (0) | 2023.01.28 |
| [머신러닝]KFold, StratifiedKFold에 대한 이해 (0) | 2023.01.28 |

