
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- semi supervised learnin 가정
- CoMatch
- 백준 알고리즘
- UnderstandingDeepLearning
- 최린컴퓨터구조
- simclrv2
- Meta Pseudo Labels
- GAN
- CycleGAN
- 컴퓨터구조
- CGAN
- dcgan
- Entropy Minimization
- tent paper
- shrinkmatch
- cifar100-c
- ConMatch
- remixmatch paper
- mocov3
- shrinkmatch paper
- 딥러닝손실함수
- WGAN
- adamatch paper
- SSL
- Pseudo Label
- BYOL
- conjugate pseudo label paper
- dann paper
- Pix2Pix
- mme paper
- Today
- Total
Hello Data
비전공생의 CVT(2023) 논문 리뷰 본문
이번 ICLR 2023에 억셉된 논문이고 풀 제목은 Contrastive Vision Transformer for self-supervised out-of-distribution detection이다. 기존 Contrastive Learning을 활용한 OOD detection문제에서는 CNN을 사용하였는데 해당 논문에서는 ViT를 사용하여 더 좋은 성능을 냈다는 것이 novelty이다.
https://openreview.net/pdf?id=UAmH4nDH4l
Introduction
OOD detection에서의 주 해결점은 당연히 기존 DNN이 다른 domain을 만날 때의 잘 인식하지 못한다는 것을 해결하는 것이다(모르면 모른다고 하는게 인간이지만, AI는 어떻게든 답을 말한다).이런 문제는 자율주행, 의료 쪽에서 크게 발생할 수 있다. OOD 데이터는 ID데이터와 비교해서는 outlier로 취급받는데, 해당 이미지의 distributionally shift가 있다고 판단된다. 이러한 distributionally shift는 semantic shift / covariate shift라고 생각되는 것이다. 이러한 OOD 데이터의 space는 거의 infinite 하기 때문에 OOD 데이터셋에 대한 representative 를 만드는 것은 사실 불가능하다고 할 수 있다. 따라서 이러한 것을 해결하는 것이 OOD detection task를 SSL을 활용해 해결하려는 것이다.
기존의 Contrastive Learning을 활용해 OOD를 접근한 방법(SSD, CSI)등은 ResNet을 backbone으로 사용하였는데, 저자는 최근 ViT가 CNN의 성능을 뛰어넘었다는 것을 언급하면서 ID, OOD 데이터를 구분하는데 도움이 될 거라 판단한다. 해당 논문에서 제기하는 contributions은 다음과 같다.
1. ViT를 backbone으로 사용, SOTA달성
2. ensemble module사용
3. ViT, CNN에 대한 ablation experiment수행
Related Work
Contrastive Learning은 SSL에서 아주 큰 성공을 거둔 방법 중 하나이다. 강한 inductive bias를 가지고 있으며(증강된 이미지는 원본 이미지와 same image이다) 이를 바탕으로 SimCLR, MoCi, SwAV 등 좋은 논문들이 작성되었다. 해당 논문들은Contrastive Learning의 collapse를 막기 위해 각각의 다른 방법들이 사용되었는데, BYOL의 asymmetric network, SimCLR의 negative sample, MoCo의 memory queue등이 있다. 그리고 해당 방법들은 모두 CNN으로 수행된다. 그러나 ViT기반의 모델들이 classification, detection, segmentation등 여러 분야에서 CNN을 앞서고 있다. 따라서 저자는 이러한 훌륭함이 attention module이 visual representation 을 잘 추출한다고 판단한다.
그리고 지금까지의 OOD detection에 대한 접근방식들을 소개하는데 총 4가지가 있다. classfication based, density based, distance based, reconstruction based방법들이 있다. Classification based 방법은 softmax 분류기를 통한 방법으로 ID데이터에 비해 OOD데이터의 softmax score가 낮은 것을 고려해 threshold를 정해 OOD를 분류하는 방법이다. 그러나 OOD데이터에도 높은 score를 부여할 수 있기다는 단점이 있다. density based방법은 ID의 확률분포와 OOD의 분포를 low density area에 위치하도록 하는 방법이다(해당 방법은 잘 이해못했다. 그러나 예시로 generative model이 나오는데 아마 GAN을 활용해 ID와 비슷한 OOD를 만드는, neary by not too nearby를 수행하는 것이 아닌가 생각이 된다). distance based 방법은 id 간의 거리보다 ID - OOD간의 거리가 클 것이라는 가정을 활용해 다양한 거리 지표를 활용하는 것이다.
Methodology
저자가 제시하는 구조는 다음과 같다.

여기서 x이미지 한개에 대해 총 4개의 증강된 이미지가 들어가 처음에는 좀 헷갈렸는데 아마 SimCLR에서 수행됐던 것처럼 cross로 증강을 적용한 것이라 생각된다. 구조는 크게 2가지로 구분된다. Contrative Loss를 산출하는 framework, score 를 내뱉는 OOD score function이 있다. 위에 나와있다시피 마할라노비스 거리 함수를 사용한다. 그리고 contrastive loss를 수행하기 위해 2개의 network 가 존재하는데, online network(파란색), target network(회색)이 있다. online network에는 정상적으로 loss에 대한 gradient 가 흐르고 해당 gradient 에 대해 moving average를 수행하는 것이 target network이다. 해당 방법을 수행하는 이유에 대해서는 BYOL에서 사용한 이유와 같은데 collapse를 막기 위한 것이라고 할 수 있다. 추가로 해당 backbone에 대해서 똑같이 CNN으로 바꾸어 전체 framework를 사용할 수 있다고 한다. 추가적으로 memory queue가 활용되었는데 저자가 말하길 본인의 computing power가 부족하여 큰 batch size를 사용할 수 없었기 때문에 memory queue를 사용했다고 언급한다. 그리고 오른쪽 ensemble module같은 경우 online network를 통한 2개의 feature들에 대해서 거리를 계산하는데 이거는 어떤 이유와 원리로 사용하였는지 잘 이해는 안갔는데 이에 대해서 추가로 설명한다.

해당 부분이 score function을 나타내는 부분이다. 잘 보면 새로운 input x에 대한 2개의 feature에 대해 ensemble을 한 후 기존 training set의 cluster과의 거리를 계산하는 것이라고 보여진다. 그러면 기존 training set에 대한 cluster는 어떻게 계산하는지 잘 안나와있고 fine tuning에 사용하는건가? 라는 생각도 들고 좀 헷갈린다.
손실함수는 다음과 같다.
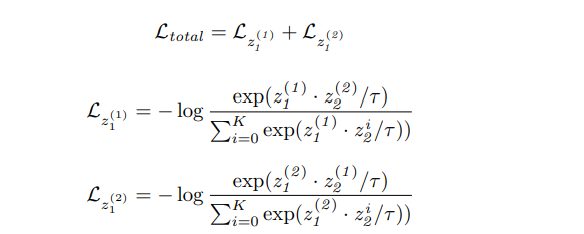
여기서 각각의 손실함수에 포함된 infoNCE loss에서 z^i_1,2가 있는데 memory queue 2개를 의미하며 i는 queue안에 들어있는 K개의 데이터를 의미한다.
그리고 score function을 구하는 법에 대해서도 언급하는데, 우선 training후라고 말한다. 그러니 우선 기존 label없는 데이터로 contrastive learning을 훈련한 다음에 ood, id 2개의 데이터셋에 대해 distance를 계산한다.
Experiment
아래는 결과이다.

그리고 cifar 10을 id로 하고 나머지를 ood로 했을 때의 시각화 결과이다.

꽤 훌륭한 거 같다.개인적으로는 novelty는 그냥 ViT를 사용하였다 밖에 없어서 아쉬웠고 경험적으로 결과가 좋았다는 것이 또 아쉬웠다.



