
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- tent paper
- BYOL
- UnderstandingDeepLearning
- CGAN
- 최린컴퓨터구조
- Entropy Minimization
- mocov3
- dann paper
- conjugate pseudo label paper
- cifar100-c
- CycleGAN
- mme paper
- SSL
- Pseudo Label
- Pix2Pix
- CoMatch
- Meta Pseudo Labels
- 컴퓨터구조
- ConMatch
- simclrv2
- remixmatch paper
- WGAN
- 백준 알고리즘
- 딥러닝손실함수
- shrinkmatch
- shrinkmatch paper
- GAN
- dcgan
- adamatch paper
- semi supervised learnin 가정
- Today
- Total
Hello Computer Vision
비전공생의 Multi-Task Curriculum Framework for Open-set Semi-Supervised Learning 본문
비전공생의 Multi-Task Curriculum Framework for Open-set Semi-Supervised Learning
지웅쓰 2023. 12. 9. 18:12이번에 Multitask 관련하여 ood를 보던 와중에 발견한 논문! CVPR에서 발표된 2020년 논문이다.
https://arxiv.org/pdf/2007.11330.pdf
Introduction
기존 딥러닝 모델들의 단점들을 말하면서 OOD를 제시하는 것이 아닌 semi supervised learning의 효율성을 언급하면서 unlabeled 데이터 안에 OOD 데이터가 있을 수 있다는 가능성을 언급한다. 여기서 SSL backbone으로 사용하는 방법은 MixMatch이다. 해당 저자들은 "Joint optimization framework for learning with noisy labels" 해당 논문에서 착안하여 방법론을 고안하는데 labeled 데이터들은 OOD score를 모두 0, unlabeled 데이터들의 OOD score를 모두 1로 훈련을 진행하고 unlabeled 데이터안에 있는 ID데이터들의 score에 대해서 추가로 조정하는 방법을 택한다. 해당 논문의 contribution은 다음과 같다.
1. Propose a novel experimental setting and training methodology for openset SSL
2. Propose a multi-task curriculum learning framework that detects OOD samples by alternate optimization and classifies ID samples by applying SSL according to the results of OOD detection
3. Evaluate our method across several open-set SSL tasks and outperforms state-of-the-art by a considerable margin. Our approach successfully eliminates the effect of OOD samples in the unlabeled data
여기서의 SSL은 semi supervised 이고, openset 은 OOD 라고 바꿔도 이해하는데 무리없을 거 같다!
Method
표기는 논문에 정확하게 나와있다. Unlabeled 데이터는 ID, OOD데이터가 섞여있다. 첫번째로 labeled, unlabeled 데이터에 대하여 pseudo label을 0, 1을 각각 부여하며 이는 OOD score를 나타낸다. 그러나 " Joint optimization framework for learning with noisy labels" 해당 논문을 언급하면서 high learning rate에서 DNN은 noisy label로 훈련된 것을 memorize하지 않는다고 한다. 이러한 결과를 활용해 저자는 Curriculum learning을 활용하는데, 이는 낮은 난이도부터 시작해서 점차 난이도를 올리는 학습방법이라고 한다. 따라서 처음에는 0,1로 단순하게 훈련하고 나중에는 조금 더 corrected pseudo label로 훈련한다는 것을 알 수 있다.

우선 OOD detection을 수행하는 알고리즘은 다음과 같다. 표기가 살짝 헷갈릴 수 있지만 해당 알고리즘에 대한 작동방식이 다시 써져있다. 처음에 딥러닝 파라미터인 $\theat$ 를 업데이트하는데 사용되는 데이터들은 0, 1로 이루어진 pseudo label들이다(쉬운 난이도). 업데이트 된 $\theta$는 freeze한 상태에서 Loss를 최소화할 수 있는 OOD score를 조정한다. 이에 대한 추가설명으로는 Loss는 전체 unlabeled 데이터의 pseudo label의 평균과 predicted OOD score가 같다면 최소가 된다고 한다.
위가 OOD detection을 위한 알고리즘이고 이제는 SSL을 위한 알고리즘이 추가로 있다. 해당 Loss는 Cross entropy loss로 이루어져 있고, labeled 데이터와 unlabeled 데이터의 차이를 최소화하는 것으로 이루어져있다. 전체적으로 살펴보면 다음과 같다.


여기서 생길 수 있는 문제가 있다. SSL을 수행하면서 OOD가 있다면 성능이 떨어진다는 것이다. 따라서 저자는 일정 OOD score top %를 sampling해 SSL에 활용한다.
Result

baseline은 Mixmatch이고, accuracy를 나타낸다.
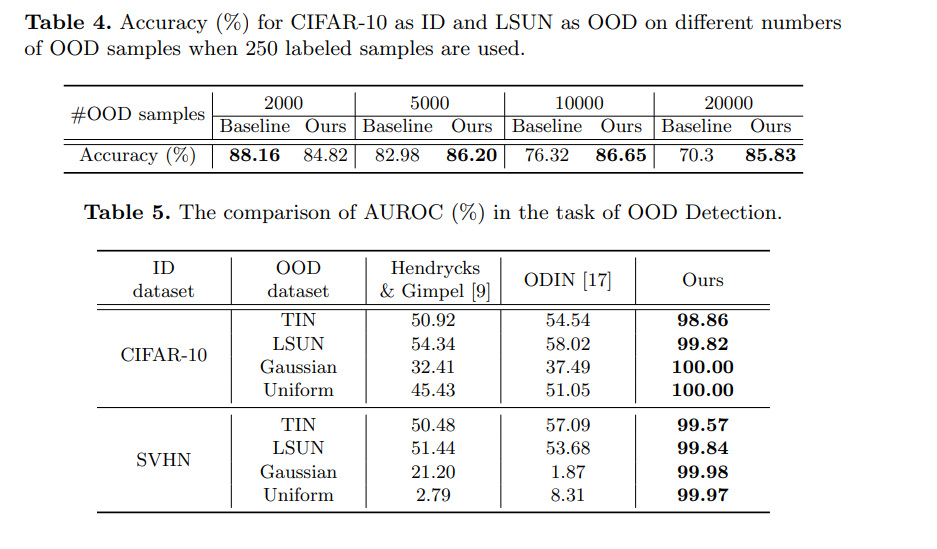
그러나 생길 수 있는 문제점으로는 unlabeled 데이터 안에 OOD 가 많이 없다면 기존보다 성능이 떨어진다는 단점을 언급했고 이에 대해 threshold에 대한 중요성을 말한다. 또한 OOD score를 산출하는 것에 대해 단순히 DNN의 extractor에 의존하는데 ID, OOD간의 feature차이를 이용하면 더 좋은 score를 얻지 않을까 생각한다.
'Out of Distribution' 카테고리의 다른 글
| 비전공생의 GradOrth(2023) 논문 리뷰 (0) | 2023.12.12 |
|---|---|
| 비전공생의 On the Importance of gradients for detecting distributiomal shifts in the wild(2021) 논문리뷰 (0) | 2023.12.10 |
| 비전공생의 SSD: A Unified framework for Self supervised outlier detection(2021) 논문 리뷰 (1) | 2023.11.15 |
| 비전공생의 CVT(2023) 논문 리뷰 (0) | 2023.11.15 |
| 비전공생의 Unsupervised Out-of-Distribution Detection by Maximum Classifier Discrepancy (0) | 2023.09.29 |



