
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- mme paper
- CycleGAN
- Entropy Minimization
- Pseudo Label
- semi supervised learnin 가정
- shrinkmatch paper
- 컴퓨터구조
- CoMatch
- CGAN
- 딥러닝손실함수
- 최린컴퓨터구조
- BYOL
- ConMatch
- remixmatch paper
- tent paper
- 백준 알고리즘
- Pix2Pix
- WGAN
- dcgan
- conjugate pseudo label paper
- mocov3
- Meta Pseudo Labels
- cifar100-c
- simclrv2
- adamatch paper
- SSL
- dann paper
- UnderstandingDeepLearning
- GAN
- shrinkmatch
- Today
- Total
Hello Data
비전공생의 CycleGAN(Cycle-Consistent Adersarial Networks, 2017)논문 리뷰 본문
논문의 full 제목은 "Unpaired Image to Image Translation using Cycle-Consistent Adversarial Networks)이다.
이번에 스터디에서 캐글에서 열고 있는 대회에 참여하기 위해 CycleGAN을 공부하기로 했고
논문을 읽게되었다. 수식이 다른 논문에 비해 많이 나오지 않아서 어렵지는 않았지만 여러 논문들을
참고한 것이 읽으면서 느껴졌다. 기존의 논문리딩처럼 처음부터 읽어보겠습니다.
Introduction
모네는 본인의 눈에 보이는 것을 화풍에 담았습니다.
과연 모네가 지금 우리세계의 풍경을 본다면 어떻게 담아낼 수 있을까요?
이러한 궁금증으로 시작합니다.
본 논문에서의 목표는 하나의 이미지의 특징을 다른 이미지로 옮기는 것이라고 합니다.
(capturing special characteristics of one image collections and figuring out how these characteristics could be translated)
기존의 연구들과 방법들은 paired dataset 을 이용했다고 합니다.
너무나도 당연하게 이러한 방법들은 비싸며 더욱 stylish한 작품일수록 pair한 작품을 고르기 어렵습니다.

저자들은 unpaired domains 사이에서도 어떠한 관계가 있다고 가정을 하며 이러한 관계를 찾으려고 노력합니다.
(각 도메인들의 manifold가 있을 것이며 공통된 부분을 찾으려고 노력하는 거 같습니다)
생성기 $G : X → Y$ 을 하려고 노력하고 만들어진 $\hat{Y} $이미지는 $Y$도메인에서 나온 이미지와 같을 것입니다.
그러나 이러한 방법으로는 각각의 x - y 매핑을 할 수 없다고 합니다.
(G를 통해 A → B 를 매핑하였는데 C → B 이렇게 매핑되는 결과가 나올 수 있다는 뜻 같습니다. 한마디로 mode collape)
따라서 이러한 문제점을 해결하기 위해 "cycle consistent"(핵심)를 사용한다고 합니다.
2개의 생성기 $ G : X → Y , F : Y → X$ 를 훈련을 한 후
$ F(G(X)) ≒ X , G(F(Y)) ≒ Y $ 가 될 수 있도록 훈련합니다. 2개의 생성기 G, F는 역함수 관계라고 합니다.

전체적인 구조는 다음과 같습니다.
(a)에서는 adversarial loss를 나타내고 (b), (c)에서는 cycle consistent loss를 시각화 하였습니다.
(a)에서의 $D_{Y}$ 는 G를 훈련시키는 분류기이며 $D_{X}$는 F를 훈련시키는 분류기이다.
Related work
GAN: 여러분야에서 많은 발전을 이루었다고 합니다.
Image to Image translation : 지금까지 많은 방법들이 고안되었다고 합니다.(참조된 논문들도 하나씩 리뷰할 생각입니다)
지금까지의 많은 연구들은 paired dataset을 이용하여 수행되었다면 저자들은 unpaired dataset이라고 합니다.
Unpaired image to image translation: CoGAN도 이러한 것을 수행하였고 조금 더 효율적으로 수행하기 위해
class label space, image pixel space, image feature space등을 써서 목적을 달성하려한 연구들이 진행되었다고 합니다.
Neural Style Transfer: 우리에게는 Style Transfer 라고 잘 알려져있는 논문은 gram matrix를 이용하여
style, content 를 뽑아내고 새로운 이미지에 대해 이러한 것을 씌우는 것이었다면 이 논문은 두개의 이미지들 사이에서
매핑하는 것이기 때문에 다르다고 말합니다. 겉보기에는 스타일을 변형시키는 것이니 같다고 생각할 수 있지만
여기서는 2개의 domains사이에서의 correspondence를 발견하여 입히는 것이라고 합니다.
Formulation
전체적인 손실함수는 2가지로 이루어져 있습니다.
Adversarial loss, cycle consistency loss
Adversarial Loss
$$L_{GAN}(G, D_{Y}, X, Y) = E_{y ~ p_{data}(y)} [log D_{Y}(y)] + E_{x~p_{data}(x)}[log(1-D_{Y}(G(x))]$$
G생성기와 Dy 분류기에 대한 손실함수만을 나타내었으며 F와 Dx에 대한 손실함수도 이와 같습니다.
(뒤에서 CycleGAN 은 다르게 adversarial loss를 정의함을 알 수 있습니다)
Cycle consistency Loss
$$L_{cyc}(G, F) = E_{x~ p_{data}(x)} [ ||F(G(x)) - x||_{1} ] + E_{y~ p_{data}(y)} [ ||G(F(x)) - y||_{1} ]$$
이렇게 되돌아오는 cycle loss 를 쓸 때는 L1 loss를 사용한다고 합니다.(아마 성능 부분에서
L2 loss보다 성능이 좋았던 거 같습니다)
이러한 손실 함수 2개를 합쳐본다면
$$L(G, F, D_{X}, D_{Y}) = L_{GAN}(G, D_{Y}, X, Y) + L_{GAN}(F, D_{X}, Y, X) + \lambda L_{cyc}(G, F)$$
여기서 $\lambda$는 각 상황에 맞게 다르게 준다고 합니다.
여기서 cycle loss를 본다면 아마 오토인코더를 생각하기 쉽습니다. $G ·F: Y → Y$
구조상으로는 비슷하지만 각각의 구조들은(G, F)는 또 다른 internal structure를 가지고있기 때문에
(아마 manifold 를 나타내는 표현 같습니다) 기존의 오토인코더가 기존 input이미지를 보존하는 것이 목적이었다면
cycle loss의 궁극적인 목적은 보존하는 것이 아닌 다른 domain으로의 mapping이기 때문에 다르다고 할 수 있습니다.
Implementation
위에서 CycleGAN의 손실함수를 알아보았는데요, 지금까지의 GAN에서의 Adversarial Loss는
생성기 G가 만든 이미지가 실제이미지와 얼마나 다른지 확률값을 내뱉고 이에 대해 로그를 취하는
BCE를 적용하였는데 CycleGAN에서는 LSGAN에서 사용되었던 Least Square Loss를 사용하였습니다.
(손실값에 대해 로그를 취하지 않고 제곱을 취해줌, LSGAN의 특징 : 여기)
그래서 생성기 G의 손실함수는 아래 식을 최소화하는 것이며
$$E_{x~p_{data}(x)}[D(G(x)) -1)^{2}]$$
분류기 D의 손실함수는 아래 식을 역시 최소화하는 것입니다.
$$E_{y~p_{data}(y)}[D(y)-1^{2} ] + E_{x~p_{data}(x)}[D(G(x))^{2}]$$
그리고 기존 GAN 분류기에서는 전체적인 이미지에 대해서 확률값을 내뱉었다면 (feature 값 1)
여기서는 PatchGAN을 사용해 70x70에 대해 확률값을 내뱉는다 합니다.
이 부분에 대해 이해를 해보자면 우리는 분류기가 이미지를 받는다면
이에 대한 채널을 늘리다가 결국 마지막에는 1x1 값을 내뱉고 sigmoid를 활용해 확률값을 이용했습니다.
그렇다면 이 값은 전체이미지에 대한 값이라고 볼 수 있습니다.(왜냐하면 값이 1개니까)
이와 다르게 받은 이미지에 대해 10x10 값을 받는다는 것은 무엇을 의미할까요?
전체 이미지에 대해서 10x10 공간으로 나눈 부분들에 대한 확률이라고 볼 수 있습니다.
이에 대한 장점으로는 일단 적은 수의 파라미터로 학습이 가능했다고 합니다.
(추가적인 생각으로는 image to image translation과정에서는 (ex.말 -> 얼룩말) 세세한 mapping이
중요하다고 생각하는데 이에 대해 부분적으로 확률값을 주어 제어한다는건 성능이 더 좋을 거 같습니다)
그리고 모델에 진동을 줄이기위해(reduce model oscillation, 아마 stable 이랑 비슷한 의미라 생각합니다)
latent generator로 분류기로 훈련하는 것이 아닌 using a history of generated images 를 이용해서
훈련을 진행했다고 합니다.
이 부분에 대해서는 생성자가 방금 만든 따근따근 이미지로 바로 훈련하는 것이 아닌 그 전에 만든
50개의 이미지를 buffer로 두어 업데이트 하였다고 합니다. 효과는 좋았다고 하고 뭔가 직관적으로는
효과가 있을 거 같긴한데 구체적으로 어떻게 코드로 구현하는지는 잘 떠오르지 않습니다..
$\lambda$값은 10으로 두고, batch size : 1, 학습률은 0.0002로 두었다고 합니다. 처음 100epoch까지는
동일한 학습률을 적용하고 그 이후 100epoch에는 linearly decay를 사용하여 0에 다다르게 하였다고 합니다.
Results
평가 방법과 데이터셋 같은 경우 pix2pix의 방식을 그대로 따랐다고 합니다.

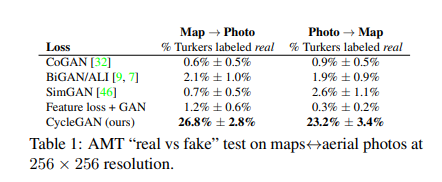
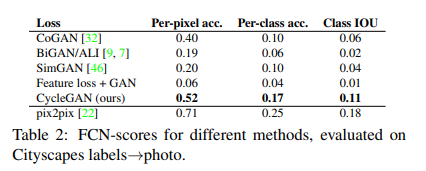
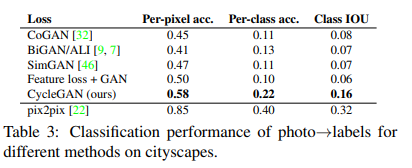
AMT의 경우 사람들을 불러서 어떤 것이 real인지 fake인지 구분하도록 한 지표입니다.
두번째와 세번째 같은 경우 상한점은 pix2pix로 두고 살펴보았을 때 그외의 baseline들의 모델들보다
좋은 지표를 나타냈다고 합니다. (아무래도 이 시점까지는 paired한 방법인 pix2pixd의 성능이 좋았던 거 같습니다)
그리고 이미지를 translate해주는 과정에서 색깔을 더 잘 보존해주기 위해서는 추가적인 loss인
identity loss가도움이 된다고 하는데요, 한번 살펴보자면
$$L_{identity}(G, F) = E_{y~p_{data}(y)} [||G(y) - y)_{1}|| + E_{x~p_{data}(x)} [||F(x) - x)_{1}||$$
각각의 생성기 G, F에 cycle loss반대로 y, x를 넣어준 것이 특징입니다.

input과 비교했을 때 색깔이 보존되었음을 확인할 수 있습니다.

이러한 이미지들을 제외하고도 여러 이미지들을 논문에서 확인할 수 있습니다.
느낀 점
논문을 읽으면서 크게 어렵지는 않았고 직관적인 cycle loss가 오히려 재밌다고 느껴졌습니다.
수식도 크게 들어가지않았던 점이 논문을 수월하게 읽었던 한가지 요인같습니다.
제가 느끼는 것이 style transfer 와 image to image translation이 비슷할 수 있지만
다른 분야라는 것입니다. 그래서 조금 더 많은 논문과 공부를 해보고 이 두 분야의 차이점을 명확히 알고 싶습니다.
참조 논문들을 일단 다운받아놓은 상태인데요, 방학이 되면 하나씩 다 읽고 리뷰해보겠습니다.
'Generative' 카테고리의 다른 글
| U-Net(U-Net: Convolutional Networks for Biomedical Image Segmentation, 2015) 논문 리뷰 (0) | 2022.11.23 |
|---|---|
| 비전공생의 CycleGAN(Cycle consistent GAN, 2017)코드 구현 (0) | 2022.11.20 |
| 비전공생의 WGAN(Wasserstein GAN, 2017) 코드 구현 (0) | 2022.11.16 |
| 비전공생의 WGAN(Wasserstein GAN, 2017) 에 대한 간단한 이해 (0) | 2022.11.11 |
| 비전공생의 InfoGAN(Information Maximizing Generative Adversarial Nets, 2016) 논문 리뷰 (0) | 2022.11.07 |



