
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- ConMatch
- WGAN
- dann paper
- tent paper
- dcgan
- mocov3
- Meta Pseudo Labels
- CGAN
- 최린컴퓨터구조
- Entropy Minimization
- simclrv2
- adamatch paper
- Pseudo Label
- conjugate pseudo label paper
- GAN
- 백준 알고리즘
- CoMatch
- BYOL
- Pix2Pix
- 딥러닝손실함수
- CycleGAN
- cifar100-c
- UnderstandingDeepLearning
- shrinkmatch paper
- remixmatch paper
- SSL
- shrinkmatch
- semi supervised learnin 가정
- 컴퓨터구조
- mme paper
- Today
- Total
Hello Data
비전공생의 Fast R-CNN(2015) 논문 리뷰 본문
논문 링크는 다음과 같다. https://arxiv.org/pdf/1504.08083.pdf
semantic segmentation을 공부하다가 instance segmentation도 공부해보려고 하는데 이를 수행하려면 Detection이랑 같이 수행해야 되는 것을 확인했다. 아무래도 semantic 은 같은 사람이라면 똑같은 클래스로 처리하지만, instance는 각 물체를 하나하나 찾은 후 다른 클래스로 처리해야하니 이러한 물체들을 찾는 작업들을 detection 을 통해 bounding box로 마킹하는 방법을 수행하더라. 그래서 R-CNN 부터 천천히 읽어봐야하지만 조금 서두르고 싶어서 Fast R-CNN 부터 공부해본다. 사실 지난번에 공부해본적 있지만 기억이 잘 안나 다시 공부하고 이번에는 기록으로 남기려고 한다.
Introduction
detection task는 많은 어려움이 있다고 한다. 우선 물체가 있을 것 같은 많은 후보지(Region of Interest)를 선정해야 하며 이것들 중에 정확하게 하는 것들을 추려내야한다. 이 논문에서 말하는 R-CNN의 단점들은 다음과 같다.
1. Training a multi stage pipeline
R-CNN의 구조를 보면 이미지에서 RoI를 뽑고 이를 각각 다 pooling하고 또 SVM까지 수행하는 것을 보았다. 이런 것이 아무래도 시간이 오래걸리는 것이다.
2. Training is expensive in space and time
위에 말했던 것이랑 일맥상통한다.
3. Object detection is slow
이러한 단점들의 요인들은 우선 각 RoI에 대하여 sharing computation 없이 CNN을 수행함에 나오는 단점들이라고 한다(+SVM). 해당 논문에서 말하는 contribution은 다음과 같다.
1. Higher detection quality than R-CNN, SPPnet
2. Training is single stage, using a multi task loss
3. Training can update all network layers
4. No disk storage is required for feature caching
RoI pooling
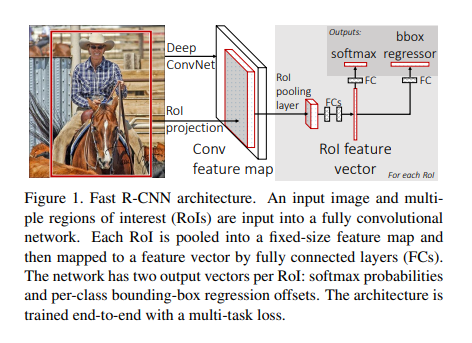
Fast R-CNN의 전체적인 구조는 다음과 같다. Network(VGG16)는 이미지를 받아 일정수준의 sub sampling을 거쳐 feature map을 만들어낸다.그리고 원본 이미지에 대하여 selective 알고리즘을 통해 region proposals을 얻는다. 해당 원본 이미지에서 뽑은 region of proposals 들은 줄어든 feature map 크기에 맞춰 projection시킨다. 그리고 논문의 핵심인 RoI pooling을 통해 고정된 feature vector를 얻는 것이다. 해당 논문에서 마지막 pooling에 의하여 줄어든 크기는 7x7이다. 이건 다른 블로그에서 얻은 설명인데, 각 region proposal 별로 7x7x512의 feature map을 얻고, 이를 flatten 후 fc layer의 입력값으로 들어간다고 한다.
Multi task Loss
해당 고정된 크기의 vectors들은 2개의 fc layer를 통해 loss가 계산되는데,
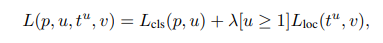
첫번째는 해당 region 이 K+1 개의 softmax classifier로 들어가며, 두번째로는 bounding box의 값을 계산하는 loss term이다. 만약 region이 배경일 경우 위치에 대한 loss는 발생하지 않는다. classifier loss는 log loss이며 bounding box loss는 L1 loss이다.
Minibatch Sampling
R-CNN에서는 region proposals 들이 서로 다른 이미지에서 추출되고, 이로 인해 학습시 연산을 공유할 수 없다고 하는데, 따라서 논문의 저자는 SGD mini batch 를 사용해 N개의 이미지를 추출하고 R개의 region proposal을 추출한다고 할 때 R/N 개의 regino proposals을 sampling했다고 한다. 이를 통해 foward, backward 시 연산과 메모리를 공유했다고 하는데 이를 정확히 이해하려고 노력했지만 그냥 그런갑다 하고 넘어갔다.
Truncated SVD for faster detection
여기서는 추가로 truncated SVD가 사용되는데, 모든 region 들에 대해 classification하면 상당히 많은 연산량이 든다고 한다. 따라서 이러한 fully connected layer에 대하여 SVD를 사용하면 연산량을 줄이면서 많은 연산량을 줄일 수 있다고 한다. 자세한 설명: https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-20-%ED%8A%B9%EC%9D%B4%EA%B0%92-%EB%B6%84%ED%95%B4Singular-Value-Decomposition
머신러닝 - 20. 특이값 분해(SVD)
이번 장에서는 특이값 분해(SVD)에 대해 알아보겠습니다. 고유값 분해에 대해 알고 있어야 특이값 분해를 이해할 수 있습니다. 고유값 분해를 잘 모르시는 분은 이전 장을 참고해주시기 바랍니다
bkshin.tistory.com
Result
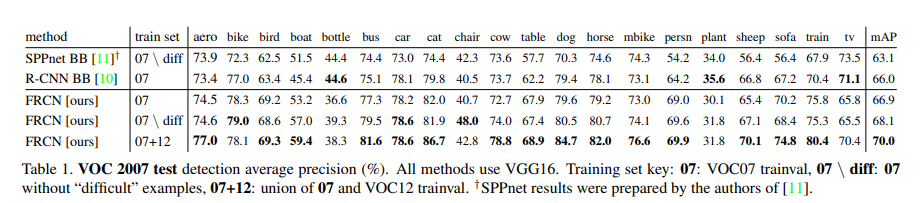
VOC 2007, 2010 에 대한 데이터 성능 표이다.
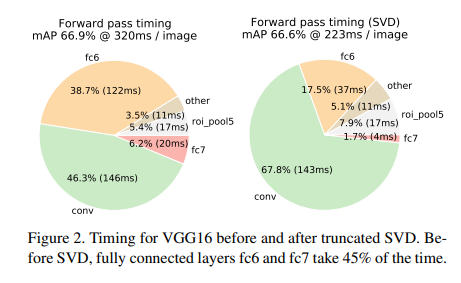
위이미지는 SVD를 사용했을 때 줄어드는 시간을 확인할 수 있다. fc6 layer가 잡아먹는 시간을 보면 된다.
어렴풋이 기억도 나지만 다시 보길 잘했다는 생각이 든다. 아마 빠른 속도로 Faster R-CNN, Mask R-CNN, YOLO등을 볼 예정이다.
References
'객체 탐지' 카테고리의 다른 글
| 비전공생의 Faster R-CNN(2016) 논문 리뷰 (0) | 2023.07.11 |
|---|---|
| Region proposal 공부해보기(sliding window, selective search) (0) | 2023.02.20 |

