
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- conjugate pseudo label paper
- CycleGAN
- shrinkmatch paper
- CoMatch
- semi supervised learnin 가정
- dann paper
- adamatch paper
- Pix2Pix
- WGAN
- cifar100-c
- tent paper
- mme paper
- dcgan
- 백준 알고리즘
- GAN
- Meta Pseudo Labels
- 딥러닝손실함수
- UnderstandingDeepLearning
- 컴퓨터구조
- BYOL
- mocov3
- ConMatch
- Entropy Minimization
- simclrv2
- shrinkmatch
- Pseudo Label
- CGAN
- SSL
- 최린컴퓨터구조
- remixmatch paper
- Today
- Total
Hello Data
비전공생의 Faster R-CNN2016 논문 리뷰 본문
어제 읽은 Fast R-CNN에 이은 Faster R-CNN 논문 리뷰이다.
https://arxiv.org/pdf/1506.01497.pdf
Fast R-CNN과 같이 자세하게 하나하나 파고드는 것 보다는 핵심 구조 위주로 이해하려고 노력하였다.
Introduction
최근의 R-CNN과 Selective Search 로 인해 detection분야에서 많은 발전이 있었다고 한다. 그리고 Fast R-CNN은 near real timewhenignoringregionproposal 에 가까운 시간이라고 한다. 그러나 여전히 region proposal 부분에서 computational bottleneck이 존재한다고 한다.
하나의 문제점이라고 하면 region proposal은 CPU에서 수행된다는 것이다. 그래서 한가지 해결책으로 이를 GPU에서 수행하면 되는 것이지만 그렇게 한다며 sharing computation을 하지 못한다고 한다정확하게이해못했지만기존의FastR−CNN방법을사용한다면속도가느리다고만이해하였다.아마이부분에대한개인적인생각은selectivesearch를따로수행해야하기때문이라고생각한다.
따라서 이 논문에서는 RPN이라는 새로운 network를 소개하는데 fully convolutional network로 구성되어 있고, 같은 CNN이기 때문에 sharing convolution 및 추가적인 computing cost가 적다고 한다.

CNN을 활용한 각각의 region proposal방법들이다. 해당 논문에서는 c방법을 선택하고 있으며 이는 뒤에서 따로 설명한다.
Faster R-CNN
Faster R-CNN의 구조는 위 이미지와 같다. 첫번째로 이미지를 Network에 넣어 feature map들을 생성, 두번째 map들을 classifierFastR−CNN의분류기 및 RPN에 넣는다. RPN에 들어간 map들은 다양하게 sliding window 방식으로 anchor 들을 생성한다. 그리고 이렇게 각 슬라이딩 윈도우 마다 생성된 anchor box들을 분류기에 넣는 것이다.
RPN에서 anchor box들을 제안하는 것을 구체화한 이미지이다. 각 슬라이딩 윈도우3x3마다 k개의 anchor box들을 생성하는데 여기서 k는 9개이다. H x W 에서 각 grid의 중점마다 anchor box 9개가 생기는 것이니 총 개수는 H x W x k9 개의 anchor box가 생성되는 것이다. 그리고 논문에서 각 sliding window를 256 dimension으로 변환하고 2개의 layerclassification,regression 설명이 있는데 이 부분은 정확하게 이해를 못하겠다. 그러나 아마 학습을 위한 장치이지 않을까 싶다. 그리고 이러한 구조의 장점은 sharing features하다는 것이라고 한다.
이러한 RPN의 방식은 translation invariant 한 특징을 가지고 있다고 한다. 해당 특징은 같은 물체가 이미지의 다른 곳으로 이동하더라도 똑같이 예측할 수 있다는 것이다.
H x W x k 개의 anchor box중에서 label하는 조건이 몇가지 있는데, 첫번째는 gt 값과 IoU값이 가장 큰 anchor box, 두번째는 IoU가 0.7보다 큰 anchor box이다. 따라서 하나의 gt값에도 여러개의 anchor들이 positive label을 부여받을 수 있다. 그리고 0.3보다 낮다면 negative label을 부여한다고 한다. RPN을 학습할 때는 negative label들이 훨씬 많기 때문에 SGD를 사용해 256개의 label들을 골라 128개는 positive, 128개는 negative를 선정해 훈련시킨다 한다.
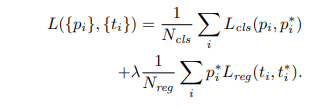
여기서 i는 sampling 된 mini batch의 index이고 pi는 뽑힌 anchor box의 probability이다. p*i는 gt label인데 regression loss를 보면 해당 값이 0이면object가아니라면 regression loss를 발생시키지 않는다.
Faster R-CNN의 구조는 RPN을 Fast R-CNN분류기에 추가한 것이다. 따라서 이 RPN과 Fast R-CNN 두 network를 sharing 하는 것이 필요하다고 하는데 따라서 저자들은 번갈아서 훈련하는 alternating training 방법을 택했다고 한다. 해당 방법은 RPN 을 한번 훈련하고, Fast R-CNN을 훈련하는 이렇게 번갈아서 훈련했다고 한다.
Result
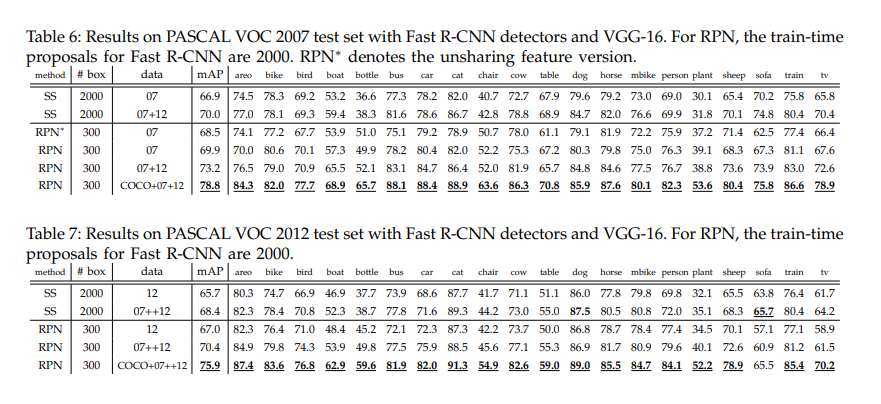
논문에서는 결과와 이 에 detail 들이 추가로 기술되어 있다.
Fast R-CNN에 RPN만 추가되어 읽는데는 무리없었고 재밌었지만 중간에 256 차원으로 변환한다거나 이러한 detail적인 부분은 완벽하게 이해하기는 힘들었다.
References
https://ganghee-lee.tistory.com/37
'객체 탐지' 카테고리의 다른 글
| 비전공생의 Fast R-CNN2015 논문 리뷰 0 | 2023.07.10 |
|---|---|
| Region proposal 공부해보기slidingwindow,selectivesearch 0 | 2023.02.20 |

