
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- CycleGAN
- dcgan
- shrinkmatch
- 최린컴퓨터구조
- Meta Pseudo Labels
- remixmatch paper
- adamatch paper
- Pix2Pix
- 컴퓨터구조
- dann paper
- GAN
- cifar100-c
- semi supervised learnin 가정
- Entropy Minimization
- 딥러닝손실함수
- UnderstandingDeepLearning
- Pseudo Label
- ConMatch
- 백준 알고리즘
- BYOL
- CoMatch
- shrinkmatch paper
- conjugate pseudo label paper
- WGAN
- SSL
- simclrv2
- tent paper
- mocov3
- mme paper
- CGAN
- Today
- Total
Hello Computer Vision
비전공생의 Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation(2023) 논문리뷰 본문
비전공생의 Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation(2023) 논문리뷰
지웅쓰 2023. 12. 11. 12:32이번 NIPS 2023에 억셉된 따끈따끈 논문이다.
https://openreview.net/pdf?id=A6PRwRjI8V
Introduction
많이 사용되는 Semi supervised learning(SSL)은 다수의 unlabeled 데이터와 소수의 labeled 데이터를 사용하는 훈련 방식이다. 그러나 기존의 SSL에서의 unlabeled 데이터들은 labeled 데이터와 분포가 같을 것이라고 가정하고 사용되고 있지만 실제로는 이러한 가정이 빗나가며 이를 간과한채 훈련한다면 모델의 성능이 떨어진다고 언급한다. 따라서 다른 분포에 있는 unlabeled데이터에 대해 잘 활용하는 것이 중요하다고 한다. 따라서 저자는 FDM-SSL(Feature distribution Mismatch - SSL)에 집중하며 SSFA(Self Supervised Feature Adaption) 간단하고도 효율적인 구조를 제시한다. 해당 구조는 labeled, unlabeled 데이터를 기존의 SSL 방식처럼 활용하면서도 unseen distribution에 대해서도 잘 대처할 수 있다고 하며 이러한 mismatch distribution unlabeled 데이터들은 robust model을 훈련하는데 많은 도움이 된다고 한다.
Method
unlabeled 데이터 들이 distribution 이 다를 수 있기 때문에 기존의 SSL방식은 사용할 수 없다. 구조를 먼저 살펴보면 다음과 같다.

2개의 module로 구성되어 있고 uw는 weak aug이 적용된 unlabeled, us는 strong aug가 적용된 unlabeled 데이터이다.. 먼저 SSL module을 살펴보면 공유하는 encoder g가 있으며 head가 2개가 있는 것을 볼 수 있는데 각각의 head는 auxiliary task, supervised task+unsupervised task를 담당한다. 먼저 supervised task는 일반적인 cross entropy를 활용하여 훈련하며 unsupervised task는 cross-entropy 혹은 mse 를 사용한다고 한다(여기서 unsupervised loss가 돌아가는 방식에 대하여 자세히 설명이 안나와있고 단순히 pseudo label loss라고 언급하며 fixmatch, remixmatch 에서의 사용되는 unsupervised loss가 아니라는 것만 언급한다. 그러나 뒷 부분에 조금 더 언급되면서 나온다.). auxiliary task는 다음과 같이 구성되며 encoder를 추가적으로 훈련시키는데 "Test-Time Training with Masked Autoencoders " 해당 논문을 언급하면서 auxiliary task가 main task를 indirectly 하게 optimizing 할 수 있다고 한다.
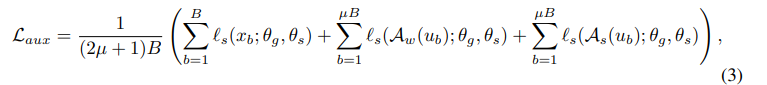
여기서 $l_{s}$는 self supervised loss를 말하는데 뭐인지 언급을 안한다. MAE를 사용하는건지, CL을 사용하는건지... appendix자체도 없어서 약간 답답하다..(아마 Self supervised loss가 사용된 곳이 auxiliary task이고, 해당 방법을 사용한 이유가 Test-Time Training with Masked Autoencoders 해당 논문에서 Auxiliary task가 도움이 된다고 언급하면서 사용하는 것이니 아마 MAE를 사용하지 않았나 싶다)
이렇게 SSL module은 3가지 loss로 구성되어 있으며 각각의 relative weights를 주어 구성한다. 이제 이 논문의 핵심이라고 할 수 있는 Feature Adaptation module이다. 기존 SSL에서는 pseudo label을 생성하는데 있어 directly use the classifier하며 이 방법은 inaccurate하다고 한다. 이러한 문제점을 해결하기 위한 Module이 Feature Adaption module이며 더욱 정확한 pseudo label을 생성하기 위해 노력한다(즉, SSL module에서 unsupervised loss를 더 정확하게 산출하기 위해 노력한다). 따라서 훈련과정에서 SSL module을 먼저 수행하는 것이 아닌 FA module을 먼저 수행한다.
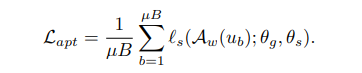
자세히 살펴보면 조금 이상할 수 있다. 위의 구조를 보면 FA module에서는$ \theta^{'}$ 이 있는데 수식에서는 $ \theta$가 있기 때문이다. 이 부분에 대해서 언급하기를 Here $ \theta$ is updated to $ \theta^{'}$ = argmin $L_{apt}$ 그 외로 언급되지 않는데 정확히 어떻게 연결되는지 모르겠다. 이렇게 한번 self supervised learning을 통해 update된 parameter를 활용해 pseudo label을 생성한다.
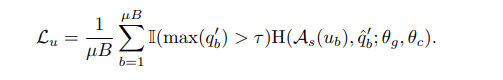
Result

결과는 SOTA니까 억셉이 됐겠지만 FA에서 사용된 self supervised 방법에 대하여 언급되어있지 않고 distribution shift 문제점에 대하여 대처했다기 보다는 추가적으로 학습방법을 늘렸기 때문에 더 좋은 결과가 나오지 않았나 생각을 한다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Dash(2021) 논문리뷰 (0) | 2023.12.15 |
|---|---|
| 비전공생의 FlatMatch(2023) 논문리뷰 (1) | 2023.12.12 |
| 비전공생의 Supervised Contrastive Learning(2021) 논문 리뷰 (1) | 2023.11.21 |
| 비전공생의 Realistic Evaluation of Deep Semi-supervised Learning algorithms(2018) 논문리뷰 (0) | 2023.11.21 |
| 비전공생의 MoCo v3(2021) 논문리뷰 (0) | 2023.11.14 |



