
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- CoMatch
- shrinkmatch paper
- mocov3
- semi supervised learnin 가정
- 컴퓨터구조
- CycleGAN
- 백준 알고리즘
- mme paper
- Entropy Minimization
- ConMatch
- conjugate pseudo label paper
- tent paper
- Pseudo Label
- UnderstandingDeepLearning
- WGAN
- shrinkmatch
- Pix2Pix
- 최린컴퓨터구조
- 딥러닝손실함수
- cifar100-c
- adamatch paper
- CGAN
- dann paper
- Meta Pseudo Labels
- dcgan
- GAN
- BYOL
- remixmatch paper
- SSL
- simclrv2
- Today
- Total
Hello Computer Vision
비전공생의 FlatMatch(2023) 논문리뷰 본문
해당 논문은 2023 NIPS 에 억셉된 논문이고 풀 제목은 FlatMatch: Bridging Labeled Data and Unlabeled with Cross-Sharpness for Semi-Supervised Learning이다.
https://arxiv.org/pdf/2310.16412.pdf
Introduction
기존 SSL의 효율성과 방법들을 소개한다.
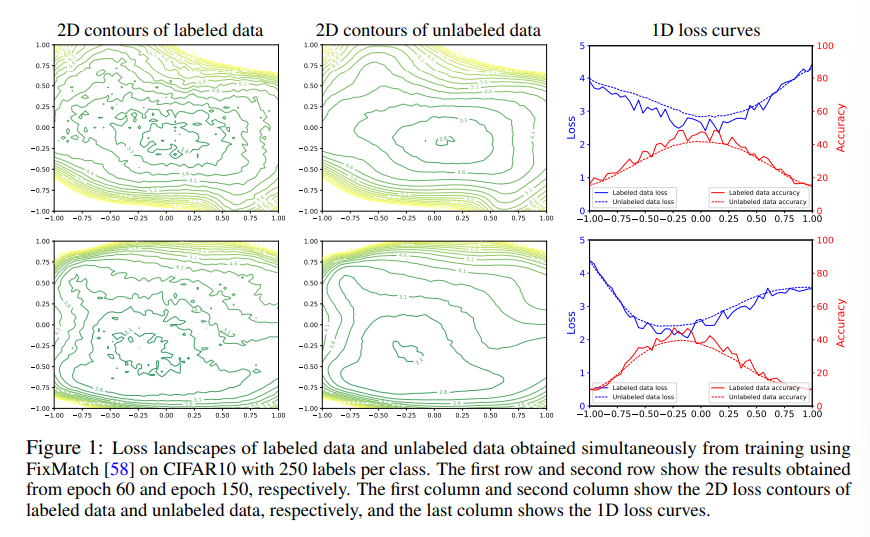
위 figure를 보여주면서 문제점을 언급하는데 labeled data의 loss landscape같은 경우 굉장히 sharp 하지만 unlabeled data의 loss landscape은 굉장히 flat하다고 한다. 이것을 저자가 해석하기를 다음과 같다.
The learning on scarce labeled data convergences faster with lower errors than on unlabeled data, but it is vulnerable to perturbations and has an unstable loss curvature which rapidly increases as parameters slightly vary. Therefore, the abundant unlabeled data are leveraged so that SSL models are fitted to a wider space, thus producing a flatter loss landscape and generalizing better than labeled data
한번 풀어서 보자면 labeled data의 loss landscape가 sharp하므로 더 낮은 loss를 찾을 수 있지만 perturbation에 민감하다고 하며 반대로 unlabeled 데이터는 generalization을 잘 할 수 있다고 한다. 따라서 cross-sharpness 를 활용하여 unlabeled데이터의 generalization을 가져오려고 한다. 해당 논문에서 말하는 contribution은 다음과 같다.
1. We identify a generalization mismatch of SSL due to the disconnection between labeled data and unlabeled data, which leads to two critical flaws that remain to be solved
2. We propose FlatMatch which addresses these problems by penalizing a novel cross-sharpness that helps improve the generalization performance of SSL
3. We reduce the computational cost of FlatMatch by designing an efficient implementation
4. Extensive experiments are conducted to fully validate the performance of FlatMatch, which achieves state-of-the-art results in several scenarios
Related Works
기존의 SSL방식들을 언급하면서도 OOD 에 대해서도 언급한다. 그러나 해당 논문에서의 세팅은 OOD를 고려하지 않고 labeled, unlabeled data 간의 connection에 집중했다고 한다.
Preliminary: Improving Generalization via Penalizing Sharpness
본격적으로 시작하기 전에 SAM optimizer를 언급한다. SAM 논문은 이전에 읽고 리뷰한 적이 있으니 도움이 될 거 같다.https://keepgoingrunner.tistory.com/177
비전공생의 SAM(2021) 논문 리뷰
논문의 풀 제목은 Sharpness-Aware minimization for efficient improving generalization이다. https://openreview.net/pdf?id=6Tm1mposlrM Introduction 많은 머신러닝 모델들이 general하게 훈련되어야 하지만 사실은 오버피팅 된다
keepgoingrunner.tistory.com
결과적으로 요약하자면 해당 optimizer는 flat minima를 찾는 optimizer이다(그 이유에 대해서는 loss landscape에서 sharp minima를 찾는 것보다 flat minima를 찾는 것이 일반화를 더 잘한다고 한다). 해당 논문에서는 epsilon을 주어 기존 파라미터의 loss에서의 sharpness를 계산하고 flatminima를 찾는다.
FlatMatch: Semi-Supervised Learning with Cross-Sharpness
기존의 SSL(semi)의 loss를 살펴보자면 다음과 같다.

labeled data에 대해서는 supervised loss를 적용하고 unlabeled 데이터에 대해서는 pseudo label, consistency를 적용하여 loss를 구성하는 것을 알 수 있다. 쉽게 알 수 있듯이 labeled, unlabeled 데이터들 간의 connection이 있지 않다.

FlatMatch의 구조를 시각화한 것이다. supervised loss는 기존의 SSL방법처럼 사용되며 여기서 loss의 최대값을 구하여 SAM 의 epsilon처럼 구하게 된다. 여기서 조금 헷갈릴 수 있는 부분이 $\theta$가 2개 있다고 각각의 독립적인 encoder가 아니라 epsilon을 더해준 것이 새로운 $\theta$ 가 된다.요약하자면 기존의 SSL에서는 encoder에서 unlabeled 데이터에 대해 단순히 Cross Entropy(or KL divergence)를 적용했다면, 해당 FlatMatch에서는 epsilon이 적용되기 전의 encoder에서ㅏ unlabeled data를 통과시킨 값과 epsilon을 적용한 후 unlabeled 데이터를 통과시킨 값의 cross entropy를 구하는 것을 알 수 있다. 이에 대해 저자는 labeled data, unlabeled 데이터를 disconnecting 하는 것은 sub-optimal일 뿐이기 때문에 SSL방법은 두 데이터를 연결해 labeled data에 있지 않은 정보들을 unlabeled data에서 얻어야한다고 말한다.

알고리즘을 보면 위와 같다.
Result


한계점으로는 어느 정도의 labeled 데이터가 있어야 한다고 말한다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 FlexMatch(2021) 논문리뷰 (1) | 2023.12.17 |
|---|---|
| 비전공생의 Dash(2021) 논문리뷰 (0) | 2023.12.15 |
| 비전공생의 Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation(2023) 논문리뷰 (1) | 2023.12.11 |
| 비전공생의 Supervised Contrastive Learning(2021) 논문 리뷰 (1) | 2023.11.21 |
| 비전공생의 Realistic Evaluation of Deep Semi-supervised Learning algorithms(2018) 논문리뷰 (0) | 2023.11.21 |



