
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- conjugate pseudo label paper
- ConMatch
- 최린컴퓨터구조
- CycleGAN
- Pix2Pix
- mocov3
- GAN
- shrinkmatch
- SSL
- mme paper
- CGAN
- Entropy Minimization
- Pseudo Label
- remixmatch paper
- 컴퓨터구조
- BYOL
- tent paper
- dcgan
- adamatch paper
- dann paper
- 딥러닝손실함수
- 백준 알고리즘
- UnderstandingDeepLearning
- shrinkmatch paper
- cifar100-c
- WGAN
- semi supervised learnin 가정
- Meta Pseudo Labels
- CoMatch
- simclrv2
- Today
- Total
Hello Computer Vision
비전공생의 FlexMatch(2021) 논문리뷰 본문
해당 논문은 NIPS 2021년에 억셉된 논문이고 풀 제목은 FlexMatch: Boosting semi-Supervised Learning with Curriculum Pseudo labeling이다. FixMatch에서 사용된 fix threshold에 대하여 adpative 하게 바꿔주는 것이 특징이다.
https://arxiv.org/pdf/2110.08263.pdf
Introduction
SSL 에서 자주 사용되는 기법은 pseudo labeling과 consistency regularization이고 FixMatch는 이러한 방법을 사용해 SOTA를 달성했다. 그러나 threshold를 fix시키는 방법은 학습 초기 단계에서 많은 unlabeled 데이터를 반영할 수 없다고 한다. 따라서 이 논문에서는 Curriculum Pseudo Labeling방법을 사용하는데, 학습상태를 고려하는 것이 특징이다. key contribution은 다음과 같다.
1. We propose Curriculum Pseudo Labeling (CPL), a curriculum learning approach of dynamically leveraging unlabeled data for SSL. It is almost cost-free and can be easily integrated to other SSL methods.
2. CPL significantly boosts the accuracy and convergence performance of several popular SSL algorithms on common benchmarks. Specifically, FlexMatch, the integration of FixMatch and CPL, achieves state-of-the-art results.
3. We open-source TorchSSL, a unified PyTorch-based semi-supervised learning codebase for the fair study of SSL algorithms. TorchSSL includes implementations of popular SSL algorithms and their corresponding training strategies, and is easy to use or customize.
Background
기본적으로 많이 사용되는 Consistency regularization, 초기에는 l2 loss 로 많이 사용되었다고 한다.

조금 더 변형된 형태로는 cross entropy, threshold와 같이 사용되었다.

FlexMatch
우선 flexible하게 threshold를 변경한다는 것 자체가 curriculum learning방식으로 진행된다고 볼 수 있다. 고정되고 높은 threshold를 처음부터 사용한다면 훈련 초기 unlabeled 데이터들을 많이 활용하지 못할 것이며 혹은 어느 한 class 에만 데이터가 많이 사용되어 훈련이 잘 안될 수도 있다. 따라서 learning status에 따라 threshold를 적용하는 방법을 간단하게 나타내면 다음과 같이 나타낼 수 있다.

t는 시점을 뜻하며 c는 class를 뜻하고 $a_{t}(c)$는 validation set에서의 정확도를 나타낸다. 해당 방법은 간단하고 직관적이지만 에포크마다 validation set을 수행해야하는데, training set에서 labeled 데이터가 기본적으로 부족한데 valid 까지 수행하는 것이 cost expensive하며, 훈련시간도 많이 든다고 한다. 따라서 저자가 제시하는 CPL(Curriculum Pseudo Labeling)은 이러한 단점이 없다고 한다.
다음은 learning status를 구하는 과정이다.

보면 unlabeled 데이터 N개에 대해서 class별로 몇개씩 threshold를 넘고, 그 넘은 값의 argmax값이 실제 정답과 같은지를 calculate 하고 있다. 그런데 이해할 수 없는 점은 여기서 unlabeled 데이터는 어떤 class에 속하는지 모르는데 어떻게 이것을 수행하는지는 잘 모르겠다.. 어쨌든 이러한 과정을 통해 class마다 n을 구하는 과정이다(각 class는 balance한 것이 가정이다).
--> 수정. 여기서 indicator function으로 둘러쌓여있어서 오해했는데 여기서 오른쪽 term 은 무조건 1이되는 function이다. 그 이유는 무조건 argmax값이 어떠한 class c에 속하기 때문이다. 따라서 다시한번 이해해보자면 모델이 어떻게 훈련되냐에 따라 총 1000개의 unlabeled데이터에 대해 강아지만 1000개로 분류될 수 있다.
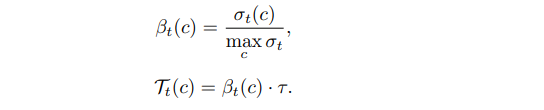
이렇게 구한 각각 class에 대한 sigma에 대하여 가장 큰 sigma로 정규화를 시켜주며 $\beta$는 0~1값을 가지게된다. 따라서 T의 값은 기존에 정한 threshold보다 낮은 값으로 설정이 되며 이런 T는 unsupervised loss에서 사용된다.

supervised loss는 cross entropy를 사용한다.
추가로 위에서 언급한 $\beta$의 경우, 초반 각 클래스에 해당하는 $\sigma$ 값들은 다 작게 나올 것이며 not be reliable이라고 표현한다. 따라서 다음과 같은 과정을 거친다. 여기서는 warm up threshold로 표현한다. 밑의 threshold가 사용되는 경우는, 사용되지 않는 unlabeled 데이터의 수가 가장 많이 사용되는 class의 unlabeled 데이터보다 많을 경우 수행된다.

각각의 $\sigma$ 값이 낮다면 전체 N에서 모든 값들을 빼준 값이 더 클 것이므로 더욱 낮은 threshold를 사용하게 된다.

위는 알고리즘표이다. 초기에 unlabeled 데이터에 대해 모두 -1로 마킹하고, 각클래스마다 $\sigma$ 를 계산하는데 여기서 초기 threshold를 못넘은 데이터는 계속 -1로 남아있는데 이건 unused의 의미이다. 만약 이 unused 데이터가 일정크기보다 많다면 warm up threshold, 아니라면 그냥 threshold를 사용한다. 말로는 조금 헷갈릴 수 있는데 논문을 차근히 보면 어렵지는 않다. 즉 훈련 초기에는 warm up이 사용될 것이고 훈련이 진행될 수록 사용되지 않을 것이다. 이 논문에서 제시되는 Threshold같은 경우 앞에서 정의한 알고리즘대로 $\beta$값에 따라 달라진다. 그러나 이 값은 linear 하므로 beta값에 굉장히 민감하고 민감하다는 것은 학습초반에 따라서 저자는 non linear function인 M을 적용해 덜 민감하도록 한다.
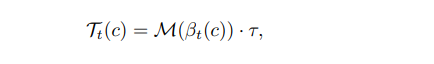
여기서 M는 x/ (2 - x) 이며 x는 (0,1] 이므로 한번더 작은 값으로 scaling 된다. 여기서 x는 논문에서는 자세히 설명이 안나와있는데 코드를 보면 (각각의 class 맞춘 개수) / max( class 맞춘 개수) 이다. 즉 max class는 1을 뱉을 것이고 나머지는 더 낮아진다고 볼 수 있다.
Result

'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Whitening for Self-Supervised Representation Learning(2021) 논문리뷰 (1) | 2023.12.19 |
|---|---|
| 비전공생의 FreeMatch(2023) 논문리뷰 (1) | 2023.12.18 |
| 비전공생의 Dash(2021) 논문리뷰 (0) | 2023.12.15 |
| 비전공생의 FlatMatch(2023) 논문리뷰 (1) | 2023.12.12 |
| 비전공생의 Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation(2023) 논문리뷰 (1) | 2023.12.11 |



