
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- mocov3
- 컴퓨터구조
- 백준 알고리즘
- Entropy Minimization
- BYOL
- CoMatch
- CycleGAN
- SSL
- simclrv2
- Pseudo Label
- mme paper
- WGAN
- dann paper
- UnderstandingDeepLearning
- ConMatch
- CGAN
- dcgan
- remixmatch paper
- tent paper
- shrinkmatch
- Meta Pseudo Labels
- GAN
- Pix2Pix
- cifar100-c
- conjugate pseudo label paper
- shrinkmatch paper
- adamatch paper
- 최린컴퓨터구조
- 딥러닝손실함수
- semi supervised learnin 가정
- Today
- Total
Hello Data
비전공생의 Whitening for Self-Supervised Representation Learning2021 논문리뷰 본문
비전공생의 Whitening for Self-Supervised Representation Learning2021 논문리뷰
지웅쓰 2023. 12. 19. 23:01해당 논문은 ICLR 2021 에 억셉된 논문으로 기존의 Contrastive loss 대신 쓸 수 있는 loss를 제시하는 논문이다.
https://arxiv.org/pdf/2007.06346.pdf
Introduction
최근의 Self-Supervised learningSSL 의 성공에 대해서 언급하면서 이에 대한 단점도 언급한다. Contrastive learning을 수행하려면 많은 수의 negative 데이터들이 필요하거나, 2개의 네트워크를 사용하는 등의 여러가지 방법들이 고안되어왔다. 저자는 따라서 새로운 SSL loss function을 제시한다물론기본적으로증강을통한invariance특징을사용하는것은동일하다. 이 논문에서는 whitening transformation(https://arxiv.org/pdf/1806.00420.pdf 논문에서 소개되었다) 을 통해 spherical distribution안에서 데이터들을 clustering 하는 것이며 이를 위해 MSE loss 를 사용한다. 이러한 과정을 통해 일반적으로 contrastive loss를 사용하면 나오는 representation collapse 현상이 없다고 말하낟. 이 논문의 contribution 은 다음과 같다.
1. We propose a new SSL loss function, Whitening MSE W−MSE. W-MSE constrains the batch samples to lie in a spherical distribution and it is an alternative to positive-negative instance contrasting methods.
2. Our loss does not need a large number of negatives, thus we can include more positives in the current batch. We indeed demonstrate that multiple positive pairs extracted from one image improve the performance.
3. We empirically show that our W-MSE loss outperforms the commonly adopted contrastive loss and it is competitive with respect to state-of-the-art SSL methods.
The Whitening MSE Loss

전체적인 프레임워크를 보면은 위 figure와 같다.
거리는 MSE Loss를 사용하여 clustering하며, 각 vector들은 l2 norm을 통해 정규화된다.
추가로 여기서는 anchor이미지에 대해 1개의 positive sample을 만드는 것이 아닌 여러개의 sample을 사용한다여기서는2,6개로실험을진행했는데결과는6개의positivepair를생성했을때가가장좋다.
encoder를 통해 나온 각 이미지의 representation vector들은 이 논문의 핵심이라고 할 수 있는 whitening transformation을 수행한다. 여기서 μ, W 는 배치 안에서의 vector들의 평균과 공분산이다. 공분산은 다음과 같이 구해진다.
이러한 과정을 통해 정규화 된 vector들을 z라고 하며 loss는 다음과 같이 구해진다.
정규화를 통해 거리를 구하는 것에 대하여 저자는 positive data들이여기서는6개 다른 데이터들간은 밀어낼 수 있다고 한다. 이것에 대한 근거로는 아래 2개의 수식을 만족해야하기 때문이라고 한다.
아래 공분산에 대해서 한번 설명해보자면, cov(zi,zi) 의 공분산행렬이 단위행렬인 것인 것은 너무나도 당연하다. 그렇다면 cov(zi,zj)가 똑같다는 것은 증강을 해도 invariance하다는 특징을 활용한 것으로 보이며 이를 한번 해석해보자면 2개의 z가 10차원의 벡터라고 한다면, zi,zj 두개의 벡터의 각각의 원소에 대한 공분산이 1이라는 것이며 그 외의 원소는 공분산이 0, 즉 아무런 관계가 없다는 것을 뜻한다. 이 공분산을 왜 사용한 것에 대해서 한번 다시 생각해보자면, positive 데이터만 사용할 경우의 loss를 줄이기 위해 모델이 0벡터만을 내뱉는 representation collapse를 방지하기 위해서인데 만약 0벡터만 뱉어버린다면 위에서 언급한 공분산에 대한 제약이 깨져버린다그렇다면공분산행렬이단위행렬이되야한다는제약이있어야하지않나..?.
추가적으로 배치 간의 공분산행렬, 평균 편차가 상당히 크다고 한다. 따라서 이를 보완하기 위해 Batch slicing 이라는 technique을 사용한다. 이는 배치 전체에 대해서 한번에 transformation 을 하는 것이 아니라 배치 안에서도 sub-batch로 쪼개서 각각의 sub-batch간의 transformation을 수행하는 것을 말한다.
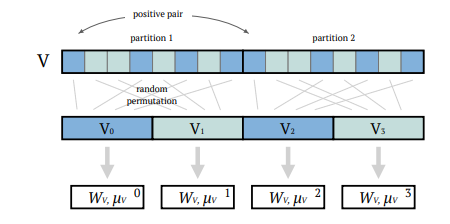
sub-batch안에서는 positive 이미지는anchor 각각 1개씩만 존재하며, sub-batch상태에서 permutation으로 한번 섞어준 후각sub−batch간의섞이는건똑같다 sub-batch안에서 일정크기로 잘라 이 안에서 평균과 공분산행렬을 구해준다. 여기서 sub-batch안에서 또 슬라이싱 하는 것에 대해서는 추가로 d라는 하이퍼 파라미터가 있는데 dd−1 / 2 라는 공식을 통해 추가적인 positive 이미지들을 만들어내게 되는 것이다.
Result
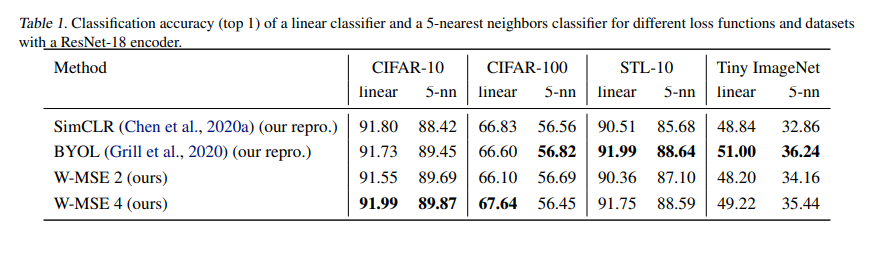
결과는 더 좋은 것도 있고 안 좋은 점도 있는데 경쟁력 있다는 것이 유의미한 거 같다.
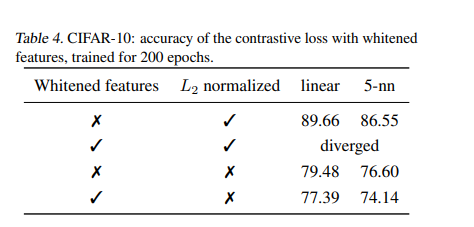
추가적으로 해당 whitening 변환을 contrastive loss에 사용한다면 성능이 더 하락한다고 한다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| Semi Supervised Learning에서 Pseudo label의 정확성 0 | 2023.12.29 |
|---|---|
| semi supervised learning준지도학습에 사용되는 가정 및 방법 0 | 2023.12.25 |
| 비전공생의 FreeMatch2023 논문리뷰 1 | 2023.12.18 |
| 비전공생의 FlexMatch2021 논문리뷰 1 | 2023.12.17 |
| 비전공생의 Dash2021 논문리뷰 0 | 2023.12.15 |


