
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- CycleGAN
- GAN
- CGAN
- 딥러닝손실함수
- semi supervised learnin 가정
- Meta Pseudo Labels
- shrinkmatch
- Pseudo Label
- cifar100-c
- mme paper
- UnderstandingDeepLearning
- simclrv2
- BYOL
- adamatch paper
- 최린컴퓨터구조
- Pix2Pix
- conjugate pseudo label paper
- tent paper
- 컴퓨터구조
- WGAN
- SSL
- remixmatch paper
- CoMatch
- 백준 알고리즘
- ConMatch
- mocov3
- shrinkmatch paper
- Entropy Minimization
- dcgan
- dann paper
- Today
- Total
Hello Data
비전공생의 LSGAN(Least Squares Generative Adversarial Networks, 2017) 논문 리뷰 본문
비전공생의 LSGAN(Least Squares Generative Adversarial Networks, 2017) 논문 리뷰
지웅쓰 2022. 11. 2. 22:14지난 CGAN에 이은 LSGAN의 논문 리뷰입니다.
CGAN도 코드를 빨리 구현해야하는데.. 학교과제에다 논문도 읽고, 컴퓨터구조 강의도 따로 듣다보니
너무 정신이 없네요.. 저의 발전을 위해서라도 논문 리딩이 끝나면 빠르게 구현해보도록 하겠습니다.
이 논문의 핵심이라면 기존의 손실함수를 Binary Cross Entropy를 사용했다면(Sigmoid Cross Entropy)
제목에서부터 알 수 있듯이 Least Square 함수를 손실함수로 사용하는 것이 가장 큰 특징입니다.
바로 한번 따라가보겠습니다.
1. Inroduction
GAN이 unsupervised learning 에서 좋은 성능을 내었다고 칭찬하면서 시작합니다.
그리고 단점을 말하는데요, 지금까지 많은 논문에서도 지적했던 것처럼 stability를 지적합니다.
이러한 단점에 대해서는 많은 논문들이 gradient vanishing 문제를 발생시키는
sigmoid cross entropy loss function이라고 하는데요, 어떤 점이 문제인지 한번 보겠습니다.

파란색 선이 real image와 fake image를 가르는 decision boundary라고 하는데요,
밑 부분을 real image라고 판단, 윗 부분을 fake image라고 판단한 것입니다.
(일단 decision boundry를 이해하기 쉽게 일부러 이렇게 만든건가 싶습니다?)
그리고 선 아래에 있는 분홍색 점들은 fake image이지만 discriminator가 real image라고 판단한 것인데요,
여기서 문제를 지적합니다. GAN에서 목표는 $p_{data} = p_{g}$ 입니다. 그렇기 때문에 generator가 생성한 이미지는
decision boundary근처에서 형성되어야 하는데 결국 핑크색 점들은 우리가 원하지 않은 결과(blurry)인데
generator의 목적은 discriminator를 속이는 것이 목적이기 때문에 학습에 하나도 도움이 되지 않습니다.
이러한 문제점들을 지적하면서 이 논문에서는 직관적이고 간단하지만 강력한 방법을 추천합니다.
문제점이라고 지적받은 손실함수를 Least Square함수(논문의 핵심)로 대체하는 것이죠.(세번째 이미지의 주황선)
이렇게 바꾸게 된다면 0,1 (fake or real)기준으로 손실을 update하는 것이 아닌 주황선과의 distance를
계산하여 손실을 계산하는 것이 논문의 핵심이다.
그리고 GAN에서의 원초적인 목적은 $p_{data} = p_{g}$하는 것이었고 이를 달성하게 위해
JS divergence를 최소화 하는 것이었다면 LSGAN은 JS divergence가 아닌
Pearson $\chi^2$ divergence를 최소화하는 것을 목표로 한답니다.
결과적으로 LSGAN을 사용하여 SOTA의 이미지보다 high quality의 이미지를 생성했다고 합니다.
2. Related work
GAN에 대한 문제를 지적하는데요

왼쪽이 GAN이 사용하고 있는 Sigmoid cross entropy이고 오른쪽이 LSGAN이 사용한 Least Square손실함수인데요,
왼쪽의 gradient를 살펴보면 x축이 2일 때부터 거의 flat해짐을 알 수 있고 학습이 잘 되지 않을 거 같습니다.
오른쪽의 gradient를 살펴보면 1에서만 flat해짐을 알 수 있고 그 외 부분에서는 gradient훨씬 월등함을 알 수 있습니다.
또한 이전 연구에서 나온 Wassertein distance도 GAN에서 사용한 JS divergence보다 훌륭하다고 말합니다.
(wGAN도 빠른 시일 내에 논문리뷰를 할 생각입니다)
3.Method
GAN에서는 Gaussian distribution($p_z(z)$) 에서 sampling 한 z 를 data space인 $G(z;\theta_z)$ mapping하고
D를 통해 classifying 하는 것이 목적이라고 하는데요, 이를 목적을 수식으로 나타내면 다음과 같습니다.
(sampling을 하고 mapping한다는 개념은 정말 어려운 거 같습니다.. 제 개인적인 이해를 써보면 정규분포에서 나온 벡터를 훈련된 generator 에 입히고 잘 학습된 generator는 기존의 $p_{data}$과 비슷한 space공간을 가지고 있을 것이며 이 공간에 들어온 벡터를 적절히 mapping한다 라고 이해를 하였습니다.)
$$min_{G} max_{D} V(D,G) = E_{x~p_{data}}(x) [logD(x)] + E_{z~p_{z}}(z) [log(1-D(G(z))]$$
GAN은 이러한 목적을 이루기 위해 sigmoid cross entropy를 선택했는데요, 이는 gradient vanishing 문제를 일으켰고
학습이 잘 되지않는 단점을 가진다고 합니다. 따라서 LSGAN의 목적함수를 이제 살펴보겠습니다.
$$min_{D}V_{LSGAN}(D,G) = \frac{1}{2}E_{x-p_{data}}(x) [logD(x)-b]^2 + \frac{1}{2}E_{z~p_{z}}(z) [log(D(G(z)-a)]^2$$
$$min_{G} V_{LSGAN}(G) = \frac{1}{2}E_{z-p_{z}}(z) [log(D(G(z)-c)]^2$$
a : fake data label
b : real data label
c : value that G wants D to believe for fake data
LSGAN의 장점은 기존 GAN이 가지고 있던 문제점을 해결하는데 있다.
discriminator를 속이는데 성공하였지만 decision boundary멀리 있던 이미지에 대한 손실함수를 발생시킬 수 있고 gradient를 더 많이 발생시킬 수 있으며, 학습과정에서 훨씬 더 stable한 결과를 보여주었다고 합니다.
이제 한번 다시 수식으로 돌아가봅시다.
$$min_{D}V_{LSGAN}(D) = \frac{1}{2}E_{x-p_{data}}(x) [logD(x)-b]^2 + \frac{1}{2}E_{z~p_{z}}(z) [log(D(G(z)-a)]^2$$
$$min_{G} V_{LSGAN}(G) = \frac{1}{2}E_{x-p_{data}}(x) [logD(x)-c]^2 +\frac{1}{2}E_{z-p_{z}}(z) [log(D(G(z)-c)]^2 $$
단순히 위 식에서 약간의 변형을 한 것인데 추가한 부분이 G에 대한 부분에서 D를 추가한 것이기 때문에 최종결과에는 변화가 없다고 합니다. 그리고 G가 fix된 상태에서의 optimal $D^*$는 다음와 같습니다.
$$D^*(x) = \frac{bp_{data}(x)+ap_g(x)}{p_{data}(x) + p_{g}(x)}$$
(이 값에 대해서는 https://jaejunyoo.blogspot.com/2017/01/generative-adversarial-nets-2.html 참고하였습니다)

이러한 약간의 식 변형을 한 후 $b-c = 1, b-a = 2$ 라는 가정, 세팅해준다면
$$2C(G) = \int_{\chi}\frac{(2p_{g}(x) - (p_{d}(x) + p_{g}(x))^2}{p_{d}(x) + p_{g}(x)}$$
이러한 결과가 도출되고 이는 $Pearson\chi^2 divergence$라고 합니다.(신기하네요..)
그래서 b-c = 1, b-a = 2값을 만족시키는 값들을 a,b,c에 부여해보자면
$$min_{D}V_{LSGAN}(D,G) = \frac{1}{2}E_{x-p_{data}}(x) [logD(x)-1]^2 + \frac{1}{2}E_{z~p_{z}}(z) [log(D(G(z)+1)]^2$$
$$min_{G} V_{LSGAN}(G) = \frac{1}{2}E_{z-p_{z}}(z) [log(D(G(z))]^2$$
(a = -1, b = 1, c = 0)
물론 여기서 다른 값을 주어 식을 조금 변형될 수 있지만 결과는 비슷하다고 합니다.
구조에 대해서는 다음 이미지와 같은데요,
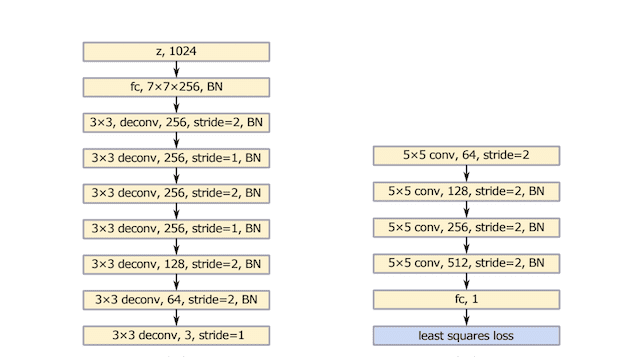
왼쪽이 generator 이고 오른쪽이 discriminator입니다. VGG모델에 기반으로 했다고 합니다.
그리고 또 다른 구조도 설명하는데 이는 중국 한자를 구분하기 위한 구조인데 class개수에 맞게 추가한 것이 특징입니다.
클래스에 대한 정보는 one-hot vector로 주려고 했으나 사용할 중국 한자 데이터셋이 3,780 개의 class로 분류되어 있어
너무 비효율적이다 생각해 linear mapping 해서 넣었다고 합니다.(아마 임베딩 벡터인 거 같습니다)

$$min_{D}V_{LSGAN}(D,G) = \frac{1}{2}E_{x-p_{data}}(x) [logD(x|\Phi(y))-1]^2 + \frac{1}{2}E_{z~p_{z}}(z) [log(D(G(z)|\Phi(y))]^2$$
$$min_{G} V_{LSGAN}(G) = \frac{1}{2}E_{z-p_{z}}(z) [log(D(G(z)|\Phi(y)-1)]^2$$
중국 한자를 구별하기 위한 목적함수는 기존의 식에서 조건 label이 추가된 것이 특징입니다.
4. Experiments

결과를 한번 비교해보자면 해상도는 물론 LSGAN의 이미지가 훨씬 깔끔하고 선명함을 알 수 있다.

다양한 이미지를 휼륭하게 생성함을 확인할 수 있다.
LSGAN의 장점이라면 stability라고 하는데요, GAN과 한번 비교해보겠습니다.

요약하자면 Adam으로 하는 것보다 RMSProp으로 최적화 해주는게 더 결과가 좋았다고 합니다.
마지막으로 3,780개의 클래스를 가진 한자를 훈련시킨 결과입니다.

결과가 아주 훌륭함을 알 수 있습니다.(CGAN처럼 임베딩 벡터를 노이즈 벡터 옆에 붙여서 훈련)
느낀 점
태초부터 논문을 천천히 읽어가니까 vanila GAN부터 시작하여 문제점을 하나씩 보완하는 것이 눈에 띄네요
이번논문 아이디어 너무 좋았고 성능도 좋아서 코드도 지금 돌려보고 있는데 결과 나오면 바로 올리도록 하겠습니다.
다음은 아마 InfoGAN 논문 리뷰를 할 생각입니다.
틀린 점 지적해주시면 감사하겠습니다.



