
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- adamatch paper
- dcgan
- shrinkmatch paper
- GAN
- CGAN
- shrinkmatch
- dann paper
- CoMatch
- BYOL
- Pix2Pix
- Entropy Minimization
- conjugate pseudo label paper
- tent paper
- CycleGAN
- SSL
- 백준 알고리즘
- Pseudo Label
- 딥러닝손실함수
- cifar100-c
- UnderstandingDeepLearning
- remixmatch paper
- simclrv2
- WGAN
- Meta Pseudo Labels
- mme paper
- ConMatch
- 컴퓨터구조
- 최린컴퓨터구조
- mocov3
- semi supervised learnin 가정
- Today
- Total
Hello Data
비전공생의 CGAN(Conditional Generative Adversarial Network, 2014)코드 구현 본문
지난번 CGAN논문 리뷰에 이어서 코드로 한번 구현해보겠습니다.
https://keepgoingrunner.tistory.com/12
비전공생의 CGAN(Conditional Generative Adversarial Nets, 2014) 논문 리뷰
지난번 DCGAN에 이어서 이번에는 cGAN이다. DCGAN도 그렇고 기존의 vanila GAN도 그렇고 데이터셋을 학습한 후 다른 조건 없이 분포르 학습한 후 이미지를 생성했다면은 이 cGAN은 정답라벨을 줘서 원하
keepgoingrunner.tistory.com
전체코드는 해당 github에서 볼 수 있습니다.
https://github.com/JiWoongCho1/Gernerative-Model_Paper_Review/blob/main/cGAN.ipynb
GitHub - JiWoongCho1/Gernerative-Model_Paper_Review: 생성모델 논문 review 및 코드 구현입니다.
생성모델 논문 review 및 코드 구현입니다. Contribute to JiWoongCho1/Gernerative-Model_Paper_Review development by creating an account on GitHub.
github.com
1.라이브러리
import torchvision
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import torch.optim as optim
import time
import os
from torchvision.transforms.functional import to_pil_image
%matplotlib inline2. 데이터셋(MNIST)
dataset = datasets.MNIST('./data', train = True, transform = trans, download = True) #MNIST데이터셋 활용3. 데이터셋 전처리
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
]) #transforms 활용하여 전처리파이토치의 transforms.Compose활용하여 텐서로 변환, 0.5로 정규화
img, label = dataset.data, dataset.targets
print(img.shape)
print(label.shape) #60000개의 데이터
img, label = dataset.data, dataset.targets
print(img.shape)
print(label.shape) #60000개의 데이터
torch.Size([60000, 28, 28])
torch.Size([60000])
torch.Size([60000, 1, 28, 28])28x28크기의 총 60,000개의 이미지
trainloader = DataLoader(dataset, batch_size = 64, shuffle = True)
data, img = iter(trainloader).next()
data.size()Dataloader 설정
def img_show(img):
plt.figure(figsize = (10, 10))
plt.imshow(torchvision.utils.make_grid(img, normalize = True).permute(1,2,0)) # H, W, C로 변경
plt.show()
for data, label in trainloader:
img_show(data)
break

우리 모두 알지만 그래도 시각화 해보기
4. Generator 정의
class Generator(nn.Module):
def __init__(self, num_classes, num_noise, input_size):
super(Generator, self).__init__()
self.num_classes = num_classes
self.num_noise = num_noise
self.input_size = input_size
self.label_emb = nn.Embedding(num_embeddings = self.num_classes, embedding_dim = self.num_classes)
#Embedding 을 통해 각 label은 고유벡터를 가지게된다.
self.gen = nn.Sequential(
nn.Linear(self.num_noise + self.num_classes, 128),nn.LeakyReLU(0.2), #128개의 입력을 받게된다.
nn.Linear(128, 256), nn.BatchNorm1d(256), nn.LeakyReLU(0.2),
nn.Linear(256, 512), nn.BatchNorm1d(512), nn.LeakyReLU(0.2),
nn.Linear(512, 1024), nn.BatchNorm1d(1024), nn.LeakyReLU(0.2),
nn.Linear(1024, np.prod(self.input_size)),#10개의 고유벡터와 100개의노이즈 벡터로부터 이미지 생성
nn.Tanh()#여기서 고유벡터를 통해 학습에 대해 이정표를 준다고 할 수 있다.
)
def forward(self, noise, labels):
gan_input = torch.cat((self.label_emb(labels), noise), -1) #입력 받은노이즈와 라벨(고유벡터)을 같이 합쳐준다.
x = self.gen(gan_input)
x = x.view(x.size(0), *self.input_size) #입력을 튜플로 받으므로 *필요
return x여기서는 클래스에 대해서 nn.Embedding을 활용해주었지만 MNIST같은 경우 분류 클래스가 10개밖에 되지 않기 때문에
one-hot vector를 추가해줘도 무방하다.(3,780개의 한자를 훈련시킬 때는 아마 Embedding이겠지?)
np.prod함수는 받은 인자값들을 다 곱한다. 여기서는 nn.Linear(1028, (28*28)) 과 같다.
forward 부분에서 노이즈와 임베딩 벡터를 합쳐준 것을 확인할 수 있다.
check_x = torch.randn(16, 100) # 노이즈
label = torch.randint(0, 10, (16,))
model_gen = Generator(10, 100, (1, 28, 28))
out_gen = model_gen(check_x, label)
print(out_gen.shape) #이미지가 B * C * H * W 로 잘 나온 것을 확인generator를 정의한 후 임의의 노이즈와 벡터를 만들어 잘 만들어지는지 확인한다.
5. Discriminator 정의
class Discriminator(nn.Module):
def __init__(self, num_classes, input_size):
super(Discriminator, self).__init__()
self.num_classes = num_classes
self.input_size = input_size
self.label_embedding = nn.Embedding(num_embeddings = self.num_classes, embedding_dim = self.num_classes)
self.dis = nn.Sequential(
nn.Linear(self.num_classes + np.prod(self.input_size), 512), nn.LeakyReLU(0.2),
nn.Linear(512, 512), nn.Dropout(0.4), nn.LeakyReLU(0.2), #마찬가지로 고유벡터와 이미지를 input으로 받는다.
nn.Linear(512, 512), nn.Dropout(0.4), nn.LeakyReLU(0.2),
nn.Linear(512, 1), nn.Sigmoid())
#0~1의 결과값을 output으로 뱉는다.
def forward(self, img, labels):
dis_input = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels)), -1)
x = self.dis(dis_input)
return xGenerator에서 받은 벡터의 크기만큼 input으로 받는다.
마지막 내뱉은 값은 sigmoid(확률값)이다.
check_x = torch.rand(16, 1, 28, 28)
label = torch.randint(0, 10, (16,))
model_dis = Discriminator(10, (1, 28, 28))
out_dis = model_dis(check_x, label)
print(out_dis.shape) #배치사이즈와 각 0~1의 값을 가지는 벡터를 output으로 내보낸다.6.가중치 초기화
def initialize_weights(model):
classname = model.__class__.__name__
# fc layer
if classname.find('Linear') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
nn.init.constant_(model.bias.data, 0)
print('FC layer 가중치 초기화')
# batchnorm
elif classname.find('BatchNorm') != -1:
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
print('Batch layer 가중치 초기화')
# 가중치 초기화 적용
model_gen.apply(initialize_weights);
model_dis.apply(initialize_weights);
FC layer 가중치 초기화
FC layer 가중치 초기화
Batch layer 가중치 초기화
FC layer 가중치 초기화
Batch layer 가중치 초기화
FC layer 가중치 초기화
Batch layer 가중치 초기화
FC layer 가중치 초기화
FC layer 가중치 초기화
FC layer 가중치 초기화
FC layer 가중치 초기화
FC layer 가중치 초기화원활한 학습을 위해 가중치를 초기화해준다.
7. 모델 정의 및 훈련
loss_func = nn.BCELoss()
optim_gen = optim.Adam(model_gen.parameters(), lr = 2e-4, betas = (0.5, 0.999))
optim_dis = optim.Adam(model_dis.parameters(), lr = 2e-4, betas = (0.5, 0.999))
num_epochs = 100
loss_history = {'gen' : [], 'dis' : []}이진분류 손실함수, 최적화 함수는 Adam 을 사용해준다.
100회의 훈련횟수를 사용한다.
batch_count = 0
model_dis.train()
model_gen.train()
for epoch in range(num_epochs):
for img, label in trainloader:
num_batch = img.shape[0]
label_real = torch.Tensor(num_batch, 1).fill_(1.0)
label_fake = torch.Tensor(num_batch, 1).fill_(0.0)
#Generator
model_gen.zero_grad()
noise = torch.rand(num_batch, 100) #노이즈 생성
gen_label = torch.randint(0,10, (num_batch,)) # 0~9까지의 batch만큼의 라벨 생성
# fake 이미지 생성
out_gen = model_gen(noise, gen_label)
# fake 이미지 판별
out_dis = model_dis(out_gen, gen_label)
loss_gen = loss_func(out_dis, label_real)
loss_gen.backward()
optim_gen.step()
#Discriminator
model_dis.zero_grad()
#real 이미지 판별
out_dis = model_dis(img, label)
loss_real = loss_func(out_dis, label_real)
#fake 이미지 판별
out_dis = model_dis(out_gen.detach(), gen_label) #discriminator를 훈련하므로 generator는 훈련 x
loss_fake = loss_func(out_dis, label_fake)
loss_dis = (loss_real + loss_fake) / 2
loss_dis.backward()
optim_dis.step()
loss_history['gen'].append(loss_gen.item())
loss_history['dis'].append(loss_dis.item())
batch_count += 1
if batch_count % 1000 == 0:
print(f'Epoch : {epoch} G_loss : {loss_gen.item():.3f}, D_loss : {loss_dis.item():.3f}' )
Epoch : 1 G_loss : 1.595, D_loss : 0.746
Epoch : 2 G_loss : 1.433, D_loss : 0.656
Epoch : 3 G_loss : 0.974, D_loss : 0.534
Epoch : 4 G_loss : 1.109, D_loss : 0.455
Epoch : 5 G_loss : 1.079, D_loss : 0.562
Epoch : 6 G_loss : 1.482, D_loss : 0.482
Epoch : 7 G_loss : 1.527, D_loss : 0.384
Epoch : 8 G_loss : 1.756, D_loss : 0.537
Epoch : 9 G_loss : 1.291, D_loss : 0.409
Epoch : 10 G_loss : 0.920, D_loss : 0.442
Epoch : 11 G_loss : 2.733, D_loss : 0.629
Epoch : 12 G_loss : 1.035, D_loss : 0.519
Epoch : 13 G_loss : 1.887, D_loss : 0.512
Epoch : 14 G_loss : 2.053, D_loss : 0.295
Epoch : 15 G_loss : 1.336, D_loss : 0.371
Epoch : 17 G_loss : 1.726, D_loss : 0.342
Epoch : 18 G_loss : 1.573, D_loss : 0.352
Epoch : 19 G_loss : 1.578, D_loss : 0.269
Epoch : 20 G_loss : 1.938, D_loss : 0.402
Epoch : 21 G_loss : 2.195, D_loss : 0.297
Epoch : 22 G_loss : 2.061, D_loss : 0.223
Epoch : 23 G_loss : 2.372, D_loss : 0.323
Epoch : 24 G_loss : 2.104, D_loss : 0.390
Epoch : 25 G_loss : 1.566, D_loss : 0.309
Epoch : 26 G_loss : 1.667, D_loss : 0.262
Epoch : 27 G_loss : 1.665, D_loss : 0.369
Epoch : 28 G_loss : 1.871, D_loss : 0.255
Epoch : 29 G_loss : 1.886, D_loss : 0.185
Epoch : 30 G_loss : 2.251, D_loss : 0.341
Epoch : 31 G_loss : 1.993, D_loss : 0.225
Epoch : 33 G_loss : 1.853, D_loss : 0.258
Epoch : 34 G_loss : 4.416, D_loss : 0.495
Epoch : 35 G_loss : 3.422, D_loss : 0.656
Epoch : 36 G_loss : 2.086, D_loss : 0.286
Epoch : 37 G_loss : 2.987, D_loss : 0.333
Epoch : 38 G_loss : 2.807, D_loss : 0.202
Epoch : 39 G_loss : 3.164, D_loss : 0.258
Epoch : 40 G_loss : 1.993, D_loss : 0.436
Epoch : 41 G_loss : 1.999, D_loss : 0.302
Epoch : 42 G_loss : 4.399, D_loss : 0.226
Epoch : 43 G_loss : 2.092, D_loss : 0.285
Epoch : 44 G_loss : 2.938, D_loss : 0.206
Epoch : 45 G_loss : 2.244, D_loss : 0.291
Epoch : 46 G_loss : 2.375, D_loss : 0.251
Epoch : 47 G_loss : 1.699, D_loss : 0.357
Epoch : 49 G_loss : 3.212, D_loss : 0.292
Epoch : 50 G_loss : 3.396, D_loss : 0.210
Epoch : 51 G_loss : 1.592, D_loss : 0.419
Epoch : 52 G_loss : 3.780, D_loss : 0.282
Epoch : 53 G_loss : 2.575, D_loss : 0.334
Epoch : 54 G_loss : 2.196, D_loss : 0.258
Epoch : 55 G_loss : 2.306, D_loss : 0.271
Epoch : 56 G_loss : 1.695, D_loss : 0.306
Epoch : 57 G_loss : 1.977, D_loss : 0.328
Epoch : 58 G_loss : 2.475, D_loss : 0.193
Epoch : 59 G_loss : 3.413, D_loss : 0.278
Epoch : 60 G_loss : 2.063, D_loss : 0.336
Epoch : 61 G_loss : 2.809, D_loss : 0.214
Epoch : 62 G_loss : 2.508, D_loss : 0.236
Epoch : 63 G_loss : 1.882, D_loss : 0.283
Epoch : 65 G_loss : 2.712, D_loss : 0.390
Epoch : 66 G_loss : 2.638, D_loss : 0.317
Epoch : 67 G_loss : 1.641, D_loss : 0.240
Epoch : 68 G_loss : 2.439, D_loss : 0.263
Epoch : 69 G_loss : 2.680, D_loss : 0.177
Epoch : 70 G_loss : 1.711, D_loss : 0.269
Epoch : 71 G_loss : 1.943, D_loss : 0.436
Epoch : 72 G_loss : 2.098, D_loss : 0.288
Epoch : 73 G_loss : 1.689, D_loss : 0.370
Epoch : 74 G_loss : 2.484, D_loss : 0.288
Epoch : 75 G_loss : 3.610, D_loss : 0.191
Epoch : 76 G_loss : 2.502, D_loss : 0.297
Epoch : 77 G_loss : 1.967, D_loss : 0.331
Epoch : 78 G_loss : 2.011, D_loss : 0.349
Epoch : 79 G_loss : 2.344, D_loss : 0.400
Epoch : 81 G_loss : 1.688, D_loss : 0.361
Epoch : 82 G_loss : 2.234, D_loss : 0.443
Epoch : 83 G_loss : 4.058, D_loss : 0.453
Epoch : 84 G_loss : 2.704, D_loss : 0.245
Epoch : 85 G_loss : 1.687, D_loss : 0.439
Epoch : 86 G_loss : 3.073, D_loss : 0.243
Epoch : 87 G_loss : 2.299, D_loss : 0.280
Epoch : 88 G_loss : 2.019, D_loss : 0.391
Epoch : 89 G_loss : 2.610, D_loss : 0.225
Epoch : 90 G_loss : 2.534, D_loss : 0.333
Epoch : 91 G_loss : 2.821, D_loss : 0.247
Epoch : 92 G_loss : 1.946, D_loss : 0.301
Epoch : 93 G_loss : 2.680, D_loss : 0.227
Epoch : 94 G_loss : 2.657, D_loss : 0.275
Epoch : 95 G_loss : 2.189, D_loss : 0.287
Epoch : 97 G_loss : 2.295, D_loss : 0.280
Epoch : 98 G_loss : 2.950, D_loss : 0.418
Epoch : 99 G_loss : 2.445, D_loss : 0.251
plt.figure(figsize=(10,5))
plt.title('Loss Progress')
plt.plot(loss_history['gen'], label='Gen. Loss')
plt.plot(loss_history['dis'], label='Dis. Loss')
plt.xlabel('batch count')
plt.ylabel('Loss')
plt.legend()
plt.show()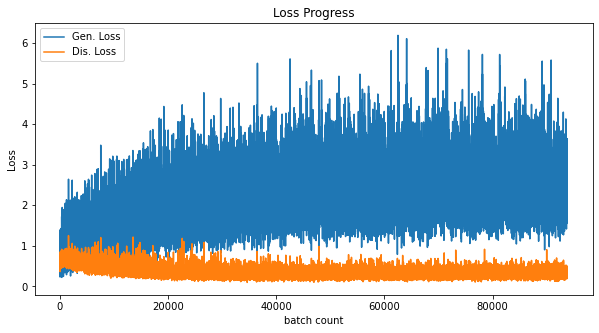
훈련 그래프를 한번 그려본다. Generator의 학습이 원활하게 되지 않음을 알 수 있다.
# evalutaion mode
model_gen.eval()
# fake image 생성
with torch.no_grad():
fixed_noise = torch.randn(16, 100)
label = torch.randint(0,10,(16,))
img_fake = model_gen(fixed_noise, label).detach().cpu()
print(img_fake.shape)torch.Size([16, 1, 28, 28])
plt.figure(figsize=(10,10))
for ii in range(16):
plt.subplot(4,4,ii+1)
plt.imshow(to_pil_image(img_fake[ii]))
plt.axis('off')
data = [1,2,3,4,5]
fixed_noise = torch.randn(5, 100)
label = torch.LongTensor(data)
img_fake = model_gen(fixed_noise, label).detach().cpu()
plt.figure(figsize=(10,10))
for ii in range(5):
plt.subplot(1,5,ii+1)
plt.imshow(to_pil_image(img_fake[ii]))
plt.axis('off')
이렇게 조건을 주고 시각화를 해본다면 어느 정도 이미지를 잘 만듦을 알 수 있다.
이렇게 MNIST데이터셋에 대해서 10개의 조건을 줄 때는 사실 별 감흥이 없었는데
이미지에 대해 하나씩 클래스를 주고 몇백개의 클래스 및 이미지를 훈련시킨 논문의 결과들을 보니
신기하였다. 한자 3,780개도 잘 훈련되었다고 하니 궁금하신 분은 논문을 보면 될 거 같습니다.
틀린 점 지적해주신다면 감사하겠습니다.



