
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- UnderstandingDeepLearning
- adamatch paper
- CoMatch
- Meta Pseudo Labels
- dcgan
- SSL
- Pseudo Label
- dann paper
- mme paper
- Entropy Minimization
- BYOL
- cifar100-c
- GAN
- WGAN
- ConMatch
- 최린컴퓨터구조
- Pix2Pix
- 백준 알고리즘
- shrinkmatch
- mocov3
- simclrv2
- CycleGAN
- tent paper
- conjugate pseudo label paper
- 딥러닝손실함수
- 컴퓨터구조
- semi supervised learnin 가정
- remixmatch paper
- shrinkmatch paper
- CGAN
- Today
- Total
Hello Data
비전공생의 Mean teacher semi supervised learning (2018) 논문 리뷰 본문
비전공생의 Mean teacher semi supervised learning (2018) 논문 리뷰
지웅쓰 2023. 6. 11. 23:16https://arxiv.org/pdf/1703.01780.pdf
논문의 풀 제목은 'Mean teachers are better role models: Weight averaged consistency targets improve semi supervised deep learning results' 이다. Mean teacher 방법론의 원조 논문 같아서 한번 읽어보려고 한다.
Introduction
딥러닝 모델들은 많은 파라미터를 필요로 하는데 이는 over-fitting 이 되는 원인이라고 한다. 따라서 regularization method를 통해 이를 방지하는 것이 좋다고 서두에 말한다. ex) dropout, noise
그러나 noise를 추가하는 것은 semi supervised learning을 목표로 두지 않는다고 한다(이거 무슨뜻인지 모르겠다.. 원문은 the noise regularization by itself does not aid in semi supervised learnig 근데 코드를 보면 noise를 추가하는 코드들이 있다. 개인적인 생각으로는 noise를 추가하는 방법이 semi supervised learning에만 국한되는 방법이 아니니 비교할 수 있는 다른 방법을 찾은 과정이 있지 않았을 까 생각을 한다). 그래서 저자들은 consistency loss 라는 방법을 선택하는데 이는 뒤에서 설명이 나온다.
target quality(target quality는 각 task마다 달라질 수 있지만 해당 논문에서는 각 class대한 확률분포를 말하는 것 같다) 를 높이는 방법은 여러가지가 있다. 첫번째는 perturbation을 하는 것이다(이 논문에서만 보면 잘 이해할 수 없는데 다른 논문에서 perturbation은 noise를 말한다). 원문에서 barely applying additive or multiplicative noise대신 perturbation을 해야 한다고 하니 노이즈 부분을 추가하는데 것에서 조금 신경을 썻다는 거 같다.
train_transformation = data.TransformTwice(transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1),
transforms.ToTensor(),
transforms.Normalize(**channel_stats)
]))논문 코드에서 사용한 코드이다. 그리고 두번째로는 student model을 카피하는 것이 아닌 teacher model을 잘 선택해야 한다고 한다. 이 뜻은 같은 구조의 teacher model에 대해 gradient 를 복사하는 것이 아니라 EMA를 수행해야 한다는 말과 일맥상통하는 거 같다(이 부분만 보면은 이해가 잘 안가지만 논문 전체의 내용을 보면 이러한 뜻을 가지고 있는 거 같다).
저자들의 목적은 teacher model을 student model 로부터 잘 만드는 것에 있다. 따라서 저자들은 이를 위해 consistency cost, classification cost를 정의해서 이를 수행하려고 한다.
Mean teacher

전체적인 구조는 위와 같다. 설명해보자면 labeled data가 들어오면다면 데이터에 대한 확률 분포를 구하고, 이를 기존의 classification loss와 teacher model과 student model의 consistency loss를 계산한다. consistency loss는 가장 간단하게 두 분포의 차를 구하는 KL divergence를 사용할 수 있지만 MSE 가 성능이 더 좋았다고 한다.

여기서 f가 구분이 안되어있는데 아마 구조가 같아서 따로 구분을 하지 않은 거 같지만 실제로는 같은 것이 아닌 student model, teacher model로 다르며 각각에 적용되는 이미지 또한 다르다. 그리고 teacher model에 대해서는 gradient 가 흐르지 않으며 student model에서 발생되는 gradient 에 대해서 상대적으로 추가된다.

여기서 알파는 적절한 값을 찾아야하는 hyperparameter이다. 0을 주면 student model 의 gradient를 똑같이 받는 것이다. 실험에서는 0.99를 ramp-up phase까지 주고(뭔지는 모르겠다) 나머지 training 동안에는 0.999를 주었다고 한다. 이렇게 준 이유에 대해서는 student 는 굉장히 빠르게 학습하고 좋아지며 (따라서 0.99로 0.999보다 많은 양을 teacher 에게 주는 듯 하다, 더 적은 값이 teacher에게 많은 gradient를 준다) 이렇게 해야 teacher는 부정확한 결과를 잊는다고 한다.
추가적으로 consistency loss는 분류학습에서 필요하지 않은 proxy task라고 하며 특히 학습 초반에 그러하다고 한다 (당연하게도 초반 2개의 network는 부정확할 텐데 이를 비슷하게 만드는 것은 좋지 않을 듯하다). 그리고 최근 SSL 방법들은 labeled 데이터에 대해서는 classification 만 수행하고 unlabeled 데이터에 대해서 PL 을 생성해 consistency를 수행했는데 이 논문은 framework를 보면 label 데이터에 대해서도 consistency를 수행하는데 이 부분에 대해서 고민한 흔적이 보인다. 그래서 여기서는 1개의 데이터에 대해서 1개의 output을 활용해 classification, consistency 두 곳에서 활용하는 것이 아니라 2개의 output을 만들어 loss를 발생시킨다고 한다.
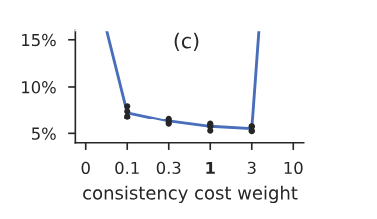
consistency loss에 대한 가중치는 따로 scheduling을 하지 않고 1로 준다. 최근 논문들은 consistency loss에 대해서 CE 를 사용하는데 여기서는 MSE를 사용한다. 여기서 MSE를 사용하는 이유에 대해서는 논리적인 이유보다는 성능의 이유라고 설명하는데, 아마 여기서는 따로 Pseudo label을 생성하지 않고 output에 대해 바로 consistency loss를 생성하기 때문에 그렇지 않나 생각을 한다. 최근 논문들은 1개의 이미지에서 나온 2개의 view 에서 Pseudo label을 생성하기 때문에 CE를 사용하지 않나 생각을 한다.
Conclusion
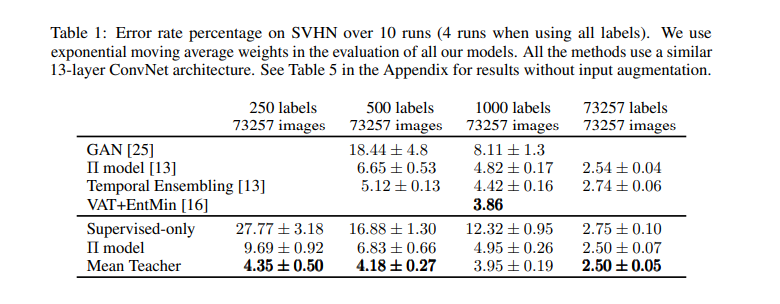
데이터 셋의 label을 일부 제거하고 실험했을 때 error rate가 가장 낮은 것을 확인할 수 있는데 unlabeled 된 데이터의 비율이 많을 수록 더 성능이 상대적으로 좋은 것을 알 수 있다.
그리고 backbone network를 기본 CNN으로 설정했지만 ResNet을 활용했을 때 결과가 더 좋았다고 한다.
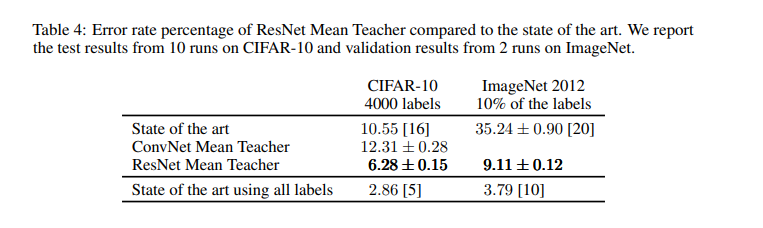
해당 논문에서 실험한 데이터들은 CIFAR10, SVHN 데이터셋인데, 모두 label이 있는 데이터셋인데 어떻게 unlabeld 처리를 했을지 궁금해서 코드들을 한번 살펴보았다.
def relabel_dataset(dataset, labels):
unlabeled_idxs = []
for idx in range(len(dataset.imgs)):
path, _ = dataset.imgs[idx]
filename = os.path.basename(path)
if filename in labels:
label_idx = dataset.class_to_idx[labels[filename]]
dataset.imgs[idx] = path, label_idx
del labels[filename]
else:
dataset.imgs[idx] = path, NO_LABEL
unlabeled_idxs.append(idx)
if len(labels) != 0:
message = "List of unlabeled contains {} unknown files: {}, ..."
some_missing = ', '.join(list(labels.keys())[:5])
raise LookupError(message.format(len(labels), some_missing))
labeled_idxs = sorted(set(range(len(dataset.imgs))) - set(unlabeled_idxs))
return labeled_idxs, unlabeled_idxs여기서 labels는 label data를 위한 사전 같은데 해당 코드에서는 None으로 정의되어있다. 이러한 작업을 통해서 unlabeled image index를 넣어주는 작업을 해준다. 근데 보기만해서는 정확히 이해가 되지는 않는다.
추가적으로 Mean teacher방식은 on-line learning이 좋다고 한다. 이것을 설명해보자면 기존에 만들었던 모델에 대해 새로운 관측치를 고려하여 바로바로 업데이트 할 수 있다는 것이다. 예시로 들자면 주식 차트를 예상하는 모델이면 실시간으로 학습할 수 있다는 것이다. 반대 개념인 offline learning은 정적인 데이터셋에서 훈련한다는 것을 의미한다.
이해될 듯 하면서도 정확히 잘 개념은 잡히지 않는다..
Online learning v/s offline learning : The pros & cons
An important change in the global school system was brought about by the Covid-19 pandemic. Lockdown regulations caused physical schools to close, which made online learning the new standard. Although...
timesofindia.indiatimes.com
해당 설명을 읽어보면 될 거 같다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Adversarial Learning for semi supervised semantic segmentation 코드 살펴보기 (0) | 2023.06.25 |
|---|---|
| 비전공생의 Pseudo label(2013)논문 리뷰 (0) | 2023.06.25 |
| 비전공생의 Adversarial Learning for Semi supervised Semantic Segmentation(2018)논문 리뷰 (0) | 2023.06.08 |
| 비전공생의 Medical Image Segmentation Using deep learning: Survey(2021) 논문 리뷰 (2) | 2023.06.06 |
| 비전공생의 SimMIM(2021)논문 리뷰 (0) | 2023.05.28 |


