
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Pix2Pix
- remixmatch paper
- adamatch paper
- 딥러닝손실함수
- CoMatch
- mme paper
- dann paper
- conjugate pseudo label paper
- ConMatch
- cifar100-c
- semi supervised learnin 가정
- Meta Pseudo Labels
- SSL
- shrinkmatch paper
- 컴퓨터구조
- CycleGAN
- mocov3
- simclrv2
- GAN
- UnderstandingDeepLearning
- 최린컴퓨터구조
- 백준 알고리즘
- tent paper
- WGAN
- dcgan
- BYOL
- CGAN
- shrinkmatch
- Entropy Minimization
- Pseudo Label
- Today
- Total
Hello Computer Vision
비전공생의 Pseudo label(2013)논문 리뷰 본문
이번에 읽어볼 논문의 풀제목은 Pseudo label: The simple and efficient semi supervised learning method for deep neural networks 이다.
논문이 아카이브에 등록되지 않은 거 같다..
Introduction
2013에 씌여진 논문인 만큼 신경망 학습이 굉장히 좋은 결과를 내었다는 것을 소개한다. 또한 이러한 결과들은 2가지 phase에 따라 성능이 올라갔다고 하는데
1. unsupervised pre-training
2. fine tuining with labels
이러한 방식이었다고 한다. 이 논문에서는 굉장히 간단한 semi supervised learning method를 사용하는데 바로 pseudo labeling이다. 이 방법은 labeled data, unlabeled data 둘 다 사용한다. 추가로 Denoising autoencoder 와 Dropout을 같이 사용할 경우 성능이 좋앗다고 한다.
이러한 방법은 Entropy Regularization에 잘 맞는다고 한다. 자세한 설명은 뒤에서 나온다.
(논문 끝에서는 결국 논문에서 제시한 방법이 Entropy Regularization의 일종이라고 한다)
이러한 방법들을 통해 MNIST dataset에서 좋은 성능을 거두었다고 한다.
Pseudo label method
해당 method는 간단하다. unlabeld 데이터에 대해서 모델이 뱉은 분포가 있을텐데 가장 높은 값이 해당 데이터의 label이 되는 것이다.
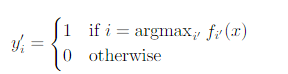
수식으로 나타내면 다음과 같다. 그리고 결국 해당 모델의 loss term은 아래와 같은데, labeled data, unlabeled data의 loss를 합한 것이다.

여기서 alpha(t)가 나오는데 이건 실험적으로 찾아야하는 하이퍼파라미터이다. 너무 높으면 모델이 labeled data에 의해 훈련이 진행될 것이고, 그 반대의 경우도 문제가 생긴다. 저자들은 epoch에 따라 해당 값을 annealing한다.

여기서 T1 = 100, T2 = 600 , alpha(f)는 3을 주었다(task마다 다르게 준다).
Why could Pseudo label work?
방법만 보면 굉장히 단순하고 무식해보이는데 왜 성능이 나올까? 우선 기본적인 clustering assumption 에 따르면 decision boundary 는 low density 한 곳에 위치한다.
위의 가정을 활용해서 Entropy Regularization을 활용한다. 우선 이 해당 방법은 MAP(maximum a posteriori estimation)에 아주 유용한 방법이라고 하는데 여기서 사전 알고 있는 정보는 decision boundary 가 low density한 곳에 위치해있다. 라는 정보를 활용하는 것 같다.

여기서 n' 은 unlabeled 데이터이다. 조금 헷갈리지만 이해한바로 쓰자면, unlabeled 데이터를 활용하여 Entropy를 낮추는 것을 목적으로 한다는 것이다. 아래 포스팅을 이해한바로 쓰자면 labeled 데이터로만 훈련할 경우 Entropy를 적정량으로 줄일 수 있는데 unlabeled 데이터를 활용하면, 어차피 decision boundary 는 low density 한 곳에 있기 때문에 unlabeled 데이터도 잘 훈련될 것이고 이는 entropy를 낮추는 효과를 가져올 것이라는 내용이다.
https://shinminyong.tistory.com/43
Pseudo Labeling, TTA(Test Time Augmentation) 기법
안녕하세요. 요즘 이미지 관련 대회를 참여하면서 굉장히 많은 난관을 겪고 있습니다... A를 공부하면 A'을 알아야하고, A'을 배우기 위해서는 A''을 알아야하고 무한의 굴레인 것 같습니다. 하지
shinminyong.tistory.com

따라서 MAP를 최대화 하기 위해 H를 최소화한다. 여기서 n은 labeled 데이터이다. 저자들은 이러한 unlabeled 데이터를 활용한다면 better generalization performance를 얻을 수 있다고 한다.
(이 부분을 내가 이해한 부분을 써보자면, 우선 모델은 기본적으로 데이터가 많으면 성능이 잘나온다. 그러나 이러한 단순한 방법은 overfitting을 불러오는데 결국 pseudo labeling을 사용한다면 데이터를 많이 사용하면서도 강건한 모델이 나온다는 말 같다)

이는 unlabeled 데이터를 이용해 pseudo labeling 을 활용할 경우 decision boundary가 더 명확해지는, 즉 entropy가 줄어든 모습이다.
Conclusion

아래 3개가 저자들의 모델이고 PL은 pseudo labeling 방법을 사용한 것이며 DAE는 Denoising autoencoder를 뜻한다.
짧은 논문인데도 재밌었다. 그러나 해당 방법은 MNIST에만 훈련한 결과를 보여주었는데 아마 많은 클래스에 대한 데이터에도 잘 적용이 될까는 의문이다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 PseudSeg(2021) 논문리뷰 (0) | 2023.07.01 |
|---|---|
| 비전공생의 Adversarial Learning for semi supervised semantic segmentation 코드 살펴보기 (0) | 2023.06.25 |
| 비전공생의 Mean teacher semi supervised learning (2018) 논문 리뷰 (0) | 2023.06.11 |
| 비전공생의 Adversarial Learning for Semi supervised Semantic Segmentation(2018)논문 리뷰 (0) | 2023.06.08 |
| 비전공생의 Medical Image Segmentation Using deep learning: Survey(2021) 논문 리뷰 (2) | 2023.06.06 |


