
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- conjugate pseudo label paper
- UnderstandingDeepLearning
- 컴퓨터구조
- adamatch paper
- WGAN
- mme paper
- cifar100-c
- CoMatch
- GAN
- Pix2Pix
- shrinkmatch paper
- shrinkmatch
- Entropy Minimization
- 최린컴퓨터구조
- Pseudo Label
- remixmatch paper
- simclrv2
- tent paper
- 백준 알고리즘
- semi supervised learnin 가정
- dcgan
- mocov3
- dann paper
- Meta Pseudo Labels
- ConMatch
- CycleGAN
- SSL
- 딥러닝손실함수
- BYOL
- CGAN
- Today
- Total
Hello Data
비전공생의 PseudSeg(2021) 논문리뷰 본문
논문의 풀 제목은 PseudoSeg: Designing pseudo labels for semantic segmentation이다. 지난번 Pseudo label 관련해서 논문을 읽었었는데 연장선으로 한번 읽어보려고한다.
https://arxiv.org/pdf/2010.09713.pdf
Introduction
pixel 단위로 annotation을 해주어야 하는 semantic segmentation은 비용이 상당히 든다고 한다. 그리고 데이터가 한정된 상황에서의 segementation 모델의 성능은 굉장히 떨어진다고 한다(여기서 low data regime 이라는 말이 나오는데 처음보는 용어인데 직관적으로 데이터가 적다 라고 해석하였다). 따라서 저자들은 data-efficient segmentation을 만드는 것에 주력하였고, labeled 된 few 데이터와 unlabeled 데이터를 활용해 성능을 올리고자 한다.
논문이 쓰여진 시점 기준 성공을 거둔 방식들은 Mean Teacher, UDA, MixMatch, consistency training 등이 있다.여기서 consistency training을 가볍게 설명하면 데이터들은 일관성을 가져야하는데, 증강된 데이터-원본 데이터 두개의 데이터에 대해 모델이 pseudo label을 나타냈을 때 똑같이 나와야 한다는 것이다. 다르다면 이를 CE를 활용해 loss를 발생시켜 학습시킬 수 있다. 그러나 저자들은 효과적은 pseudo label과 효과적인 데이터 증강을 사용하는 것은 굉장히 어렵다고 한다.
따라서 저자들은 별다른 추가적인 labeled data없이 성능을 올릴 수 있는 one - stage training framework를 제안한다. 이 논문의 contribution은 다음과 같다.
1. simple one stage framework for semantic segmentation
2. Directly applying consistency trainign approcach
3. PASCAL VOC 2012, COCO dataset 사용
Related work
Consistency regularization, Entropy minimization은 가장 보편적인 SSL 방법이라고 한다. 그리고 labeled 데이터를 활용한 semantic segmentation은 비용이 많이 들뿐더라 에러가 나기 쉽다고 한다(여기서 에러라 함은 학습할 때의 loss보다는 픽셀별로 annotated 해야되는 만큼 손수 작업하더라도 실수할 가능성이 많다는 의미같다). 따라서 unlabeled 데이터들을 leveraging 해 semantic segmentation에 활용하는 것이 좋다고 한다(여기서 leveraging 용어가 쓰였는데 아마 unlabeled 데이터를 leveraging 해 labeled 데이터로 활용하겠다 라는 의미로 쓰여진게 아닌가 싶다).
Proposed method
몰라도 되지만 해당 방법을 이해하기 위해서는 CAM, Grad-CAM에 대한 이해가 살짝 필요한데, 이에 대해서 포스팅을 직전에 공부해서 써놓았다.
https://keepgoingrunner.tistory.com/151
CAM, Grad-CAM 공부해보기
이번에 Pseudo segmentation 논문을 읽으면서 Grad-CAM 에 대한 내용이 나오는데 읽어야 잘 이해할 수 있겠다고 생각해서 공부해보려고 한다. 논문을 읽을까 생각했는데 자세히 나와있는 포스팅이 많아
keepgoingrunner.tistory.com
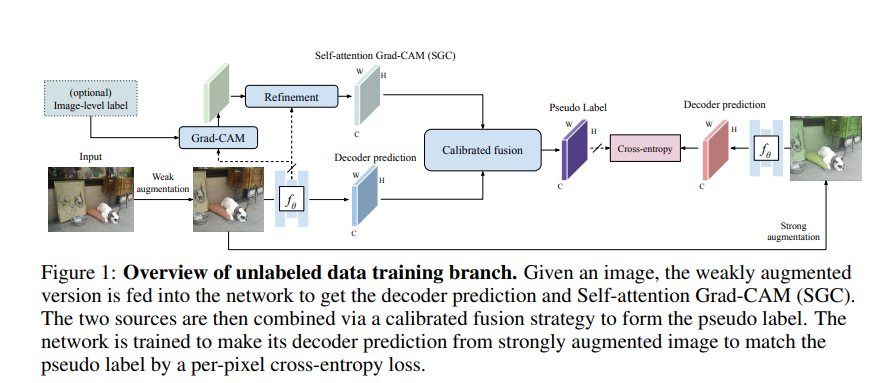
우선 구조를 시각화 하면 위와 같다. 그리고 다른 SSL방법과 동일하게 Ls(supervised loss), Lu(unsupervised loss)가 따로 나뉘어져 있는데
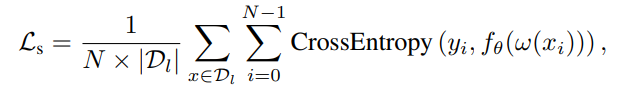
supervised loss는 위와 같다. w는 weak augmentation이고 f는 network를 뜻한다.

unsupervised loss는 위와 같은데, 여기서 베타는 strong augmentation이다. 그리고 y또한 pseudo label인 것을 확인할 수 있다.
그렇다면 여기서 중요한 점은 yhat, 즉 pseudo label을 어떻게 생성할지가 중요하다. 가장 직관적인 방법은 이전에 포스팅했던 pseudo label(2013)처럼 decoder에서 내놓은 분포를 사용하면 편하다. 그러나 이러한 방법은 데이터가 많이 available하지 않을 때는 적절하지 않다고 한다(처음에는 잘 이해못했는데 개인적인 이해를 써보자면, 처음부터 pseudo label을 생성하면 당연히 에러가 많기 때문에 어느 정도 labeled data를 통해 학습한 후 pseudo label을 생성하는 과정이 필요할텐데, 처음부터 data 가 부족하다면 만족스러운 결과를 얻지 못할 가능성이 높기 때문에 논문에서는 이러한 것을 말하는 것이 아닌가 싶다).그렇기 때문에 저자들은 이러한 pseudo label을 잘 생성하기 위해 2가지 instight 를 제시하는데, 첫번째로는 단순히 decoder 의 output보다는 특이하면서도(distinct) 효율적인 방식을 찾자. 두번째로는 단순히 하나의 output을 활용하기 보다는 multiple sources들을 ensemble하고 fusing하자.
CAM은 기존 CNN네트워크에서 Activation map을 시각화할 수 있기 때문에 이미지에서 특정 region 에 대해 localization할 수 있는 좋은 접근 방법이라고 한다. 그러나 단점이라고 한다면, 단순히 most discriminative한 region에만 attending한다는 것이다(이 부분에 대해서 개인적인 이해를 써보면, 한 이미지에서 한개의 물체에 대해서만 localization을 하는 단점이라고 생각된다. 그러나 segmentation에서는 여러 물체를 구분할 필요가 있다). 그래서 이러한 단점을 보완하기 위해 region 사이에 pairwise similarities 를 활용했다고 한다. 이를 잘 활용한다면 CAM을 활용해 한 부분에만 activation map이 활성화 되어도 similarity가 높은 다른 region에도 높은 CAM score를 할당할 수 있다.
그러나 CAM의 단점은 기존 CNN네트워크에 GAP를 추가해야하며, CNN 네트워크에만 활용할 수 있다는 단점이 있었고 이러한 단점을 보완한 것이 Grad-CAM이었다. 따라서 해당 논문에서도 Grad-CAM을 활용한다.

해당 수식은 각각 region간의 similarity를 계산하는 수식인데 attention dot product를 수행하며, 여기서 mi 는 skip connection, K는 kernel fuction을 의미한다(수식을 정확하게 이해는 못했지만 단순히 region간의 similarity를 계산하는 수식이라고 이해하였다. 이에 대한 수식은 논문의 Appendix A에 존재한다).

위 이미지가 Appendix A에 나온 SGC모습이다.
그러나 SGC에서 나온 map은 low resolution feature map이라고 한다. 그렇기 때문에 이를 활용해 segmentation을 수행하는 것은 촘촘하고 정확한 annotating 을 요구하는 semantic segmentation에는 부적합할 수 있다. 그렇기 때문에 추가적인 decoder에서 pseudo label을 활용한다.

여기서 p는 softmax에 들어가기 전 decoder의 logit값이다. 이렇게 2가지 방법을 fusion해서 pseudo label을 생성했다.
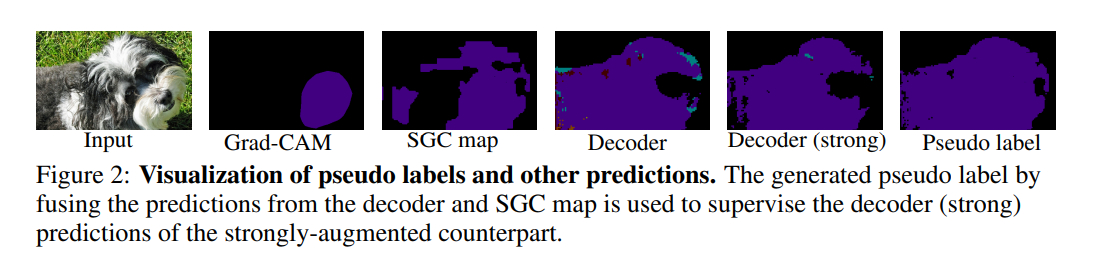
해당 activation map을 보면 SGC map과 decoder의 map이 합쳐진 것이 pseudo label map이 된 것을 확인할 수 있다.
그리고 글 초반부에 supervised loss, unsupervised loss 이렇게 2개가 있다고 하는데 training과정에서 2가지 loss를 추가했다고 한다. classification loss인 Lx , segmentation loss인 Lsa이다.

이에 대한 설명으로는 엄청 자세히 나와있지는 않은데 나와있는대로 설명해보자면, Segmentation backbone에 classification head를 하나 붙여 Grad-CAM을 계산해 Lx를 계산하고, SGC map을 계산하기 위해pixel labeled데이터와의 비교를 통해 Lsa 를 계산한다고 한다. 이 부분들은 자세히 나와있지 않아 그냥 넘어간다.
추가로 strong data augmentation으로는 color jittering, cutout 을 사용했다고 한다. 그러나 논문 마지막 즈음에 저자들은 이에 대한 논의가 추가로 필요하다고 말한다.
Result

labeled 된 데이터가 줄어들더라도 pseudo seg model이 더 강건한 것을 확인할 수 있다.

다른 모델과 비교했을 때 성능이 좋은 것을 알 수 있다.
이 외로도 temperature 사용 유무, color jittering, backbone에 대한 성능 관련해서도 논문에 나와있으니 궁금하시면 한번 찾아보면 될 거 같다.
재밌었던 논문이고 읽으면서 애매한 표현? 처음보는 표현들이 많아서 개인적인 이해를 많이 다은 설명이었다. 겁나지만 한번 코드로 구현해보고 싶기도 하다.
References
https://deep-learning-study.tistory.com/953
[논문 읽기] PseudoSeg, Designing Pseudo Labels for Semantic Segmentation(2020)
PseudoSeg, Designing Pseudo Labels for Semantic Segmentation(2020) semi segmentation 논문. pixel label이 존재하면, 이미지에 weak augmentation을 준 뒤 모델로 전달하여 얻은 prediction과 gt사이의 cross entropy loss를 계산. unlabe
deep-learning-study.tistory.com
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 UNet++(2018) 논문 리뷰 (0) | 2023.07.03 |
|---|---|
| 비전공생의 FixMatch(2020) 논문리뷰 (0) | 2023.07.03 |
| 비전공생의 Adversarial Learning for semi supervised semantic segmentation 코드 살펴보기 (0) | 2023.06.25 |
| 비전공생의 Pseudo label(2013)논문 리뷰 (0) | 2023.06.25 |
| 비전공생의 Mean teacher semi supervised learning (2018) 논문 리뷰 (0) | 2023.06.11 |


