
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Meta Pseudo Labels
- 컴퓨터구조
- dcgan
- GAN
- WGAN
- dann paper
- SSL
- cifar100-c
- semi supervised learnin 가정
- CGAN
- Pix2Pix
- 최린컴퓨터구조
- BYOL
- Pseudo Label
- 딥러닝손실함수
- shrinkmatch
- mme paper
- Entropy Minimization
- remixmatch paper
- CoMatch
- UnderstandingDeepLearning
- mocov3
- tent paper
- simclrv2
- ConMatch
- CycleGAN
- shrinkmatch paper
- conjugate pseudo label paper
- 백준 알고리즘
- adamatch paper
- Today
- Total
Hello Computer Vision
비전공생의 FixMatch(2020) 논문리뷰 본문
논문의 풀 제목은 FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence 이다. MixMatch 라는 논문도 있었는데 FixMatch가 더 나중에 나온 논문이고 인용수도 많아 우선 이걸 읽을라고 한다.
https://arxiv.org/ftp/arxiv/papers/2001/2001.07685.pdf
Introduction
딥러닝 모델들은 높은 성과를 이룰려면 많은 데이터가 필요하다고 한다. 당연하게도 일일이 annotated 된 데이터들의 cost는 높다. 그러나 unlabeled 데이터들은 적은 노력으로도 얻을 수 있기 때문에 semi / self supervised learning에 의한 성능 상승은 low cost 에서 얻을 수 있다.
SSL의 가장 기본적인 방법은 Pseudo labeling, Consistency regularization이다. 해당 논문을 통해 저자들은 기존 trend의 복잡한 방식들을 선택하기 보다는 간단한 방법을 선택했다고 한다(결과적으로 pseudo labeling과 consistency regularization을 합한 방식을 선택하는데 이 전 SOTA논문들은 한가지 방법에 대해 복잡한 방법을 통해 SOTA를 이루지 않았나 싶다). 그리고 중요한 것은 weak augmentation을 통해 pseudo labeling을 했다고 한다.
FixMatch
Fixmatch 는 위에서 미리 말했던 것처럼 Pseudo labeling, Consistency regularization 방법의 combination이라고 말한다. Consistency regularization 은 모델이 같은 이미지에 대해 비슷한 결과를 내어야한다는 가정에서 시작한다.
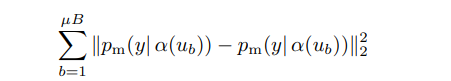
이러한 수식이 대표적일 수 있는데, 수식의 각 term 에서 나타난 alpha, pm 은 stochastic function인데, 따라서 각 term 은 다른 값을 가지게 되며 이를 최소화하는 것이 기본적인 consistency regularization의 목적이라고 할 수 있다(위 수식은 해당 논문에서 쓰이는 수식이라기 보다는 consistency regularization에 쓰이는 수식이라고 할 수 있다).
Pseudo labeling 은 말 그대로 unlabeled 데이터를 model에 넣어서 artificial label을 얻는 것이다. 그리고 이러한 label은 hard label이며 이는 threshold 값에 따라 정해진다. 이를 정하는 수식은 다음과 같다.
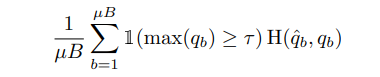
qhat 은 argmax(qb) 이고 t는 threshold 값이다. 그리고 pseudo labeling은 model이 prediction값을 low entropy 로 예상하게끔 훈련되므로 entropy minimization이라고 하는데, consistency regularization도 entropy minimization이 아닌가 라는 생각이 들긴한다.
FixMatch의 loss는 2가지로 이루어진다. supervised loss + unsupervised loss.

supervised loss는 위와 같다. alpha는 weak augmentation이고 unlabeled 데이터와 labeled 데이터와의 entropy를 최소화하는 것이다. 2023.08.03 수정. FixMatch이후 여러가지 논문에서 Supervised, Unsupervised loss에 대해 FixMatch에서 사용된 loss를 사용한다고 하는데 거기서 나온 수식은 y, weak augmentation된 데이터에 대하여 cross entropy 를 계산한다. 따라서 위에서 내가 말한 부분은 unlabeled, labeled 데이터의 cross entropy를 구한다고 했는데 내가 잘못본 거 같다..

supervised loss에 비해 unsupervised loss는 약간 헷갈릴 수 있다. 해당 q_b는 unlabeled 데이터에 대해 weak augmentation을 적용한 distribution값이다. 그리고 이를 감싸는 것은 논문에서는 안나오는데 아마 indexing 함수? 이거 같은데 분포의 argmax 값이 threshold 값을 넘지 못하면 loss를 생성하지 않는 함수 같다. 그리고 qhat_b는 이렇게 argmax값이며, A는 strong augmentation값이다. loss term을 요약해보자면, unlabeled data에 대해서 weak augmentation을 적용하고 분포의 argmax값이 threshold 값을 넘으면 loss를 발생시키는데, 이 argmax값과 이미지에 strong augmentation을 적용한 분포와의 Cross entropy를 최소화하는 것이라고 할 수 있다.
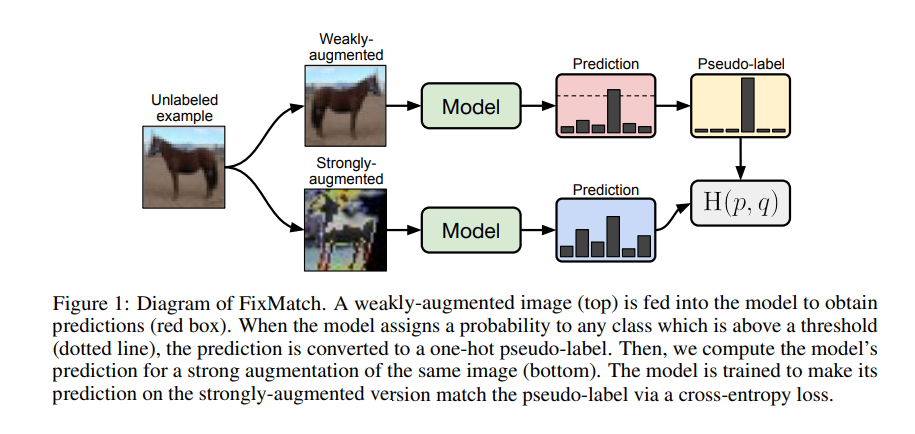
위 그림은 FixMatch의 구조를 보여준다.

그리고 loss에서 lambda가 따로있는데 이는 고정된 값을 설정하는데 그 이유에 대해서는 model이 unlabeled 데이터에 대해서 초반에는 잘 예측하지 못해 threshold 값을 넘기지 못해 loss를 잘 생성하지 못하지만 갈 수록 많이 생성해 loss를 발생시키므로 따로 조정할 필요가 없다고 논문에서 말한다.
논문에서 나온 weak augmentation, strong augmentation에 대해서도 설명을 하는데, weak augmentation은 단순히 flip-and-shift augmentation방법을 선택했다고 한다. 그리고 strong augmentation에 대해서는 AutoAugment 방법을 선택했다고 한다. 이를 따로 찾아보니 고정적인 방법을 사용하는 것이 아니라 task 및 데이터에 맞게 방법을 사용하며 성능이 좋은 것을 사용하는 것이라고 한다.
그리고 해당 SSL 알고리즘은 low label 에 대해서 regularization을 해야하므로(아마 entropy regularization을 의미하는 거 같다) 딥러닝 모델이 image classification 을 수행할 때 중요하게 생각하는 요소들이 SSL에서도 중요하다고 한다(이 말 뜻은 해당 논문에서 나온 것 역시 각 unlabeled data 분포에 대해서도 entropy를 최소화하는 것이 목적이기 때문에 일반 딥러닝 네트워크가 예측을 잘하도록 촉직하는 것이 해당 방법에서도 중요하다는 것을 말하는 거 같다). Adam 보다는 SGD를 사용했고 weight decay, cosine learning rate를 사용했다고 한다(더 많은 방법들이 있다).
Experiments

여러 데이터 셋에 대해 error rate를 기록한 것이다. 적은 unlabeled data일 수록 다른 모델에 비해 error 가 더 낮은 것을 확인할 수 있다.
Ablation study
해당 논문에서는 아주 간단한 방법 두가지를 조합했고 SOTA를 달성했는데 이러한 성능이 어떻게 나왔는지에 대해 저자들은 궁금해한다. 이에 저자들은 Sharpening, Threshold, augmentation strategy에 있다고 한다. 기본적으로 분포 logit 값을 조정할 수 있는 temperation 값에 대해서는 0.95를 주었을 때 가장 error가 낮았다고 하며 이와 반대로 threshold 값을 높게 줄 경우 error가 낮았다고 한다.
++++ 2024.1.12 추가
FixMatch에서 Labeled, Unlabeled 데이터가 사용되는데, Labeled 데이터는 Unlabeled 데이터의 일부일까? 예를 들어 데이터셋이 50,000개이고 Labeled 데이터를 400개 쓰면 Unlabeled는 50,000개 일까 49,600개일까? 정답은 49,600개이다. 논문 page의 가장 아래에 써져있다.
++++2024.1.25 추가
google에서의 setting을 본다면 총 이미지 65,536 개를 쓰고 64개의 batch를 default값으로 둔다. 그리고 1 epoch당 1024번의 최적화 과정을 거치는데, 아마 64개의 이미지로 1024번의 최적화 과정을 거쳐야 65,536 개가 되기 때문에 그러지 않나 싶다. 그런데 개인적인 생각으로는 최적화 step자체를 데이터개수 / labeled 개수 로 수행하는게 제일 낫지 않나 생각을 한다.
쉽고 재밌는 논문이었다.완전 최신 논문은 안읽어봤지만 이 시기 Semi supervised learning trend를 잘 알 수 있는 논문이었다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 DASO(2021) 논문 리뷰 (0) | 2023.07.21 |
|---|---|
| 비전공생의 UNet++(2018) 논문 리뷰 (0) | 2023.07.03 |
| 비전공생의 PseudSeg(2021) 논문리뷰 (0) | 2023.07.01 |
| 비전공생의 Adversarial Learning for semi supervised semantic segmentation 코드 살펴보기 (0) | 2023.06.25 |
| 비전공생의 Pseudo label(2013)논문 리뷰 (0) | 2023.06.25 |


