
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- UnderstandingDeepLearning
- CycleGAN
- 백준 알고리즘
- BYOL
- CoMatch
- adamatch paper
- WGAN
- 딥러닝손실함수
- shrinkmatch paper
- SSL
- mocov3
- Pix2Pix
- ConMatch
- simclrv2
- CGAN
- remixmatch paper
- Pseudo Label
- conjugate pseudo label paper
- mme paper
- Meta Pseudo Labels
- semi supervised learnin 가정
- dcgan
- 최린컴퓨터구조
- tent paper
- shrinkmatch
- Entropy Minimization
- dann paper
- GAN
- 컴퓨터구조
- cifar100-c
- Today
- Total
Hello Data
비전공생의 DASO(2021) 논문 리뷰 본문
논문의 풀 제목은
DASO: Distribution-Aware Semantics-Oriented Pseudo-label for Imbalanced Semi-Supervised Learning
이다.
https://arxiv.org/abs/2106.05682
Introduction
semi/self supervised learning은 unlabeled data에 대해서 좋은 성능을 보여주고 있으며 대표적인 방식은 pseudo label을 만들어 regularization하는 것이다(Fixmatch 논문을 보면은 쉽게 이해할 수 있다. 해당 논문도 비교대상으로 Fixmatch를 말한다).
그러나 지금까지의 많은 논문들은 class balanced data들에 한해서 연구들이 진행되었는데 실제 세상에서는 imbalanced data들, 즉 long tailed distribution을 띄는 데이터들이 많다. long tailed 관련해서 가볍게 설명해보자면

https://arxiv.org/pdf/1611.08976.pdf
해당 논문에서 나온 이미지이다. 많은 데이터들이 있고 이러한 데이터들을 활용해 10명의 사람을 구분해야한다고 하자. 그런데 왼쪽에 여자는 많은 데이터를 보유하고 있기 때문에 잘 분류할 수 있겠지만 오른쪽으로 갈 수록 꼬리부분에는 적은 사진 밖에 없다. 따라서 이러한 데이터분포는 다른사람인데도 이미 많은 수로 학습된 여자로 확증편향된 결과를 내뱉을 수 있다. 그렇기 때문에 훈련을 할 때도 이러한 class imbalance한 부분을 신경써서 훈련해야 모델이 확증편향되지 않고 제대로 훈련될 것이다.
이러한 문제의 어려운 점은 실제 데이터 분포가 어떻게 될지 아무것도 모르는 것이다. unlabeled 데이터분포와 labeled 데이터분포가 다를 수 있으며 label데이터에는 없던 class가 unlabeled 데이터에는 존재할 수 있다. 따라서 분포에 대해서 섣부른 가정(assumption)은 모델을 설계할 때 전혀 도움이 되지 않으며 해당 논문에서는 labeled 데이터분포와 unlabeled 데이터 분포가 같다는 가정을 사용하지 않는다.
그래서 이 논문에서는 DASO, Distribution-Aware Semantics-Oriented, 라는 방법을 이용해 framework를 제안한다. 핵심은 linear, semantic한 방법들을 혼합해 pseudo label을 생성한다.이렇게 혼합해서 사용하는 이유는 뒤에 나온다. 해당 논문에서의 contribution은 다음과 같다.
1. novel pseudo labeling framework for debiasing pseudo labels by class adaptively blending two complementary types of pseudo labels
2. Introduce semantic alignment loss to further alleviate the bias from high quality feature representation
3. DASO readily integrates with other framworks to show significant performance improvement.
Related Work
SSL(semi supervised learning)은 labeled , unlabeled 데이터들을 활용해 모델을 학습하는 것이다. 따라서 unlabeled 데이터들에 대해 pseudo label들을 생성한 다음 이를 labeled 데이터의 분포와 비교를 통해 consistency regularization하는 방법이 대중적이다.
Proposed Method

DASO 의 framework는 위 이미지와 같다. 논문에 여러가지 표기들이 나와서 헷갈리는데 appendix 에서는 이러한 표기법들에 대해서 어떤 것을 나타내는지 알려준다.
linear classifier는 쉽게말해 FC 인데 이에 FC에 의해 생기는 분포를 뜻한다. 그리고 이 논문에서 linear classifier 와 similarity classifier를 결합한 이유는 다음과 같다.

3개의 도표가 있는데 a,b를 잘 살펴보자. a는 pseudo label들의 recall 을 나타내고 b는 precision을 나타낸다. 그리고 해당 클래스의 인덱스들은 많은 순으로 c0~c9로 정렬되어 있고 c7~c9가 tail 부분이라고 할 수 있다. 먼저 FixMatch를 살펴보자면 tail부분에서 precision이 상당히 높고 recall 이 낮다. Precision이 무엇인지 가볍게 설명해보자면 TP / TP + FP이다.즉 내가 옳다고 예측한 것 중 얼마나 많이 맞추었냐이다. 이를 해석하자면 tail 데이터들에 대해 확증편향이 일어났다는 것이다. 처음에 이해하기 어려웠는데 예시를 들어보자면 100개의 공 중에 90개의 파란공, 10개의 빨간공이 있다 하자. 그런데 2개만 뽑아서 빨간공으로 예측했고 우연히 이게 다 맞았다. 그러면 100%라고 생각하는 것인데 이를 이 경우와 비슷하다고 보면 된다. 즉 c7~c9 데이터들에 대해 거의 적은 부분들을 c7~c9 예측했고 이것들이 맞았다는 것이다. 그렇다면 이제 recall을 살펴보자. recall 의 공식은 TP / TP + FN 이다. 즉 정답 100개가 있다면 얼마나 많은 정답을 찾았냐이다. precision과 비슷해보이지만 다르다. 이를 해석하자면 많은 c7~c9 데이터들에 대해서 잘 예측하지 못한 것이다. FixMatch의 이러한 수치들은 imbalance class문제에 대해 잘 대처하지 못하고 확증편향이 일어났다고 보면 된다. USADTM(주황색 막대)는 semantic pseudo label을 뜻하는데 FixMatch와 반대를 나타내는데 이는 오히려 적은 데이터들에 대해서 반대로 확증편향이 일어났다고 보면 된다. 이러한 결과를 토대로 저자들은 두개의 방법을 합치는 것을 제안한다.
Pseudo label
이제부터 linear pseudo label과 semantic pseudo label이 많이 나오는데 미리 정의해두려고 한다. 그리고 각각의 pseudo label에 활용되는 z는 encoder에서 나온 feature vector이다.

linear pseudo label은 위와 같다. 맨 바깥쪽에 있는 함수는 softmax 함수이다.
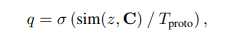
semantic pseudo label은 위와 같다. 여기서 sim 함수는 class간의 similarity를 계산하는 cosine similarity 함수이며 C라는 집합과 z라는 이미지를 계산한다. 그리고 T는 SSL에서 자주나오는데 scaling parameter로 1보다 낮으면 분포를 더 뾰족하게 만들어주는 효과가 있다.
Balanced prototype
저자들은 similarity based classifier 를 수행하기 위해 set of class prototype을 설계했다고 한다.

자세히 들어가보자면 우선 각 class를 담고 있는 고정적인 크기의 memory queue 를 설계한다.

각각의 class prototype ck는 memory queue인 Qk 안에서 feature point들을 평균시키게 된다. 그리고 queue가 다 찬 상태에서는 제일 오래된 feature 를 버리게 되며 계속 업데이트가 된다. 이러한 prototype representation도 bias가 일어날 수 있는데 따라서 저자들은 queue의 크기를 고정시켰으며, 추가로 momentum encoder를 채택했다고 한다. 여기서 feature encoder는 classifier 에 들어가는 feature들을 뽑아내는 encoder이다. feature encoder의 momentum 에 따라 update되는 encoder는 prototype generation encoder이다(이 부분은 살짝 헷갈리니 흥미있다면 논문을 읽어보시는 걸 추천).
그리고 각각 2가지의 pseudo label들은 blending process를 거쳐 phat이 만들어지는데 따라서 여기서의 unsupervised loss는 다음과 같다.

여기서 phat은 blending process를 거친 pseudo label이고 p는 여기서 따로 언급은 되지 않는데 supervised loss와 unsupervised loss가 다른 SSL논문과 비슷하다고 했으니 아마 unlabeled data에 대해 Weak augmentation을 적용하고 linear classifier를 통해 pseudo label을 만들지 않았을까 싶다. 그리고 해당 blending process는 다음과 같다.

phat은 linear classfier이고 qhat은 similarity classfier이다. 그리고 여기서 v_k는 distribution aware weights를 뜻하는데 k는 데이터 분포에서 어떤 한 클래스 k를 나타내는데 phat이(linear classifier) 예측한 클래스 k를 나타낸다. 따라서 v_k는 각 k클래스에 따른 weights를 나타내는 것이다. 그리고 이 값은 다음과 같이 결정된다.

여기서 mhat은 current pseudo label의 nomalized class distribution이라고 나와있는데 이전의 few epoch에서의 blending pseudo label의 accumulation이라고 한다. 따라서 mhat은 따로 지정할 수 없는 값이며 T 값이 hyper parameter라고 할 수 있는데 이에 대한 결과도 뒤에 나와있다.그리고 이 값은 학습마다 고정시키는 것이 아니라 mhat의 값에 따라 dynamic하게 변경했다고 하는데 이러한 변경으로 인해 DASO 가 flexible한 특징을 가지고 있다고 한다. 예를 들어 head class에 대해 bias가 생겼다면 v값의 가중치를 올려 q값(semantic pseudo label)을 올리는 것이다.
그리고 추가로 이 논문에서는 semantic alignment loss가 사용되는데 다음과 같다.
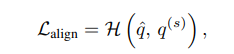
여기서 두개의 q는 모두 unlabeled 데이터이며 각각 weak augmentation, strong augmentation이 적용되었고 이 두 feature들에 대해 cross entropy를 구한다. alignment 는 similar sample은 similar feature를 가져야한다는 것인데 여기서 사용되는 이유는 more balanced feature representation을 위해서 사용되었다고 한다. 단지 FixMatch에서 나오는 것과 조금 다른 점은 손실함수에 들어가는 feature가 semantic pseudo label인 것이 큰 다른 점이다.
total loss는 3가지 loss로 구성되어있다.

여기서 Lcls 는 따로 수식으로 언급되지는 않지만 SSL의 기본 loss라고 한다. 따라서 아마 이러한 수식을 가지고 있을 것이라 생각한다.

Experiment / Result
글 초반부에 보면 imbalance class 분포에 대해서 가정을 하지 않는다고 하였다. 따라서 실험들을 보면 두가지 상황에 대하여 실험을 한다. labeled , unlabeled 데이터 분포가 같은 경우와 다른 경우.


여기서 비율로 나오는 gamma는 max(k) N / min(k) N 으로 정의된다.따라서 이 값이 1일 경우에 balanced class분포를 가지고 있으며 높을 수록 imbalance 한 정도가 심하다고 할 수 있다. 그리고 N은 labeled 데이터, M은 unlabeled데이터이다

추가적으로 여러가지 실험들도 수행되었는데 위 표를 보면 align loss를 추가하는 것이 도움이 된다고 말하고 있다. align loss자체가 semantic pseudo label을 어느 정도 사용하는 것이니 혼합해서 사용하는 것이 도움이 되는 것 같다.
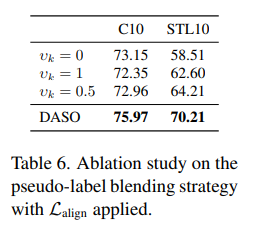
가중치에 대해서 고정시키는 것보다 dynamic하게 변화한 DASO가 성능이 좋은 것을 알 수 있다.

해당 표는 recall과 accuracy를 나타내는 표이다. DASO 의 성능이 fixmatch보다 좋은 것을 알 수 있다.
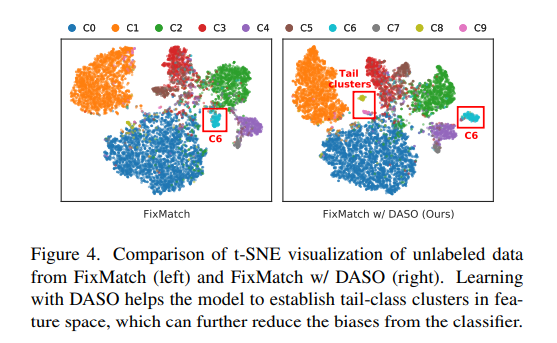
t-SNE로 각각의 class 들을 군집화했을 때 FixMatch에서는 흩뿌려져 있었던 클래스들이 DASO 에서는 군집화 되는 것을 확인할 수 있으며 c6은 다른 곳으로 임베딩 된 것을 확인할 수 있다.
FixMatch를 최근에 읽기도 했고 memory queue를 제외하고는 크게 어려운 점도 없어서 재밌게 읽었던 논문입니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 CCSSL(2022) 논문리뷰 (0) | 2023.08.02 |
|---|---|
| 비전공생의 SimMatch(2022) 논문 리뷰 (0) | 2023.08.01 |
| 비전공생의 UNet++(2018) 논문 리뷰 (0) | 2023.07.03 |
| 비전공생의 FixMatch(2020) 논문리뷰 (0) | 2023.07.03 |
| 비전공생의 PseudSeg(2021) 논문리뷰 (0) | 2023.07.01 |



