
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- tent paper
- Meta Pseudo Labels
- 컴퓨터구조
- ConMatch
- BYOL
- 백준 알고리즘
- Pseudo Label
- mme paper
- 최린컴퓨터구조
- shrinkmatch paper
- CoMatch
- Pix2Pix
- UnderstandingDeepLearning
- cifar100-c
- mocov3
- SSL
- adamatch paper
- simclrv2
- remixmatch paper
- shrinkmatch
- dcgan
- GAN
- 딥러닝손실함수
- semi supervised learnin 가정
- CycleGAN
- CGAN
- WGAN
- Entropy Minimization
- dann paper
- conjugate pseudo label paper
- Today
- Total
Hello Data
비전공생의 MoCo(2020) 논문 리뷰 본문
SSL 첫 논문 리뷰 대상은 MoCo 이다. 어디서부터 논문을 읽어야할지 감은 안잡혔지만 Moco -> SimCLR -> BYOL 순으로 대표적인 논문들만 읽어볼 예정이다.
Introduction
이전 비전 분야에서 unsupervised learning이 NLP 분야만큼 나오지 않은 이유는 표현들이 더욱 continuous, high-dimensional 등등의 이유라고 말한다. 그러나 contrastive loss가 등장하면서 최근의 발전을 이루고 있는데 추가로 활용하는 것이 dynamic dictionary이다. dictionary 안에는 query이미지에 대한 key 이미지들이 있으며 이미지 query 에 대해서 similar / dissimilar 을 계산하게 된다. 논문에서는 이 dictionary에 대하여 충분히 커야하고, 일관성을 가져야한다고 말한다. 크기가 클 수록 더 많은 negative key들과 같이 계산하게 되니 좋다. 그리고 일관성을 더욱 높이기 위해서 여기서 핵심들인 queue(이하 큐)와 key encoder 를 업데이트 하기 위해 momentum 을 활용한다(직관적으로 생각해보자면, queue encoder가 빠른 속도로 업데이트 된다면은 같은 queue내에서 비슷한 이미지에 대해서도 다른 결과를 내는 이러한 consistency하지 않은 것을 방지하는 것으로 보인다). MoCo의 전체적인 학습과정은 다음과 같다.

Method
MoCo에서 사용하는 loss는 infoNCE loss로 다음과 같다.

q: query
k+: q와 similar pair key(query 이미지의 증강)
ki : q와 dissimilar key(K개의 negative sample)
T: temperature hyperparameter
(여기서 T가 낮을수록 softmax 그래프가 뾰족해지며 확률분포에 대해 선호도가 뚜렷하다고 합니다)
이러한 loss를 활용하여 query encoder를 학습합니다.
학습하는 과정에서 논문의 저자들은 계속해서 consistency를 강조하는데요, 이를 위한 해결책으로는 첫번째로 큐를 제시합니다.
Solution1. Queue
장점
1. encoded key 들을 재사용할 수 있다.
2. dictionary size와 mini batch size를 decouple(분리)할 수 있다.
특히 두번째 장점으로 인해 더 큰 dictionary size를 유지할 수 있다고 말합니다. 이유에 대해서는 dictionary안에 있는 sample들에 대해서 FIFO(First in First out)를 이용하기 때문에(큐의 특징) dictionary에 mini batch에 대하여 enqueued 된다면 맨 아래에 있는(oldest) mini batch는 deque 됩니다. 따라서 이러한 dictionary 구조는 모든 데이터에 대해 최신적이며(removing outdated) consistent 를 가질 수 있다고 말합니다.
Solution2. Momentum update
이러한 queue구조는 dictionary를 충분히 크게 만들 수 있지만 학습에 쓰이기는 굉장히 어렵습니다. queue안에 있는 모든 데이터들에 대해 backpropagation을 수행하기 어려우니까요. 따라서 아주 naive 한 해결책으로는 query encoder를 key encoder가 copy한다고 말하지만 성능은 좋지 않다고 합니다. 이에 대한 이유로는 query의 빠른 변화, 학습에 대해서 key encoder가 consistency를 잃는다고 합니다. 따라서 이를 대응하기 위해 momentum update를 도입하는데 식은 다음과 같습니다.

m 에 0 값을 주게 된다면 이전에 말했던 query encoder을 copy하는 것이며 1을 주면 query encoder를 학습에 활용하지 않는 것이다. 논문에서는 실험적으로 0.999 값을 주며 key encoder의 학습을 조금 더 smoothly하게 한다고 한다. 여기서 저자들은 이 식의 핵심을 slowly evolving key encoder라고 한다.
## 논문에서 강조하는 consistent를 유지한다는 것이 관념적으로는 이해는 되고 구체적으로는 이해하기 힘들지만 해결책 2개를 따라가면서 이해를 써보자면,
queue를 사용해 구식의 표현들을 없앤다 --> 만약 large dictionary 안에서 구식과 최신의 표현들이 섞여있다면(초기의 encoder가 뱉은 표현, 많은 수의 update가 이루어진 후의 encoder가 뱉은 표현의 공존) 이 또한 문제일 것이다. 내게 조금 더 익숙한 attention encoder로 설명해보자면, 첫번째 학습에 쓰였던 key가 업데이트 되지 않고 10회 때 또 쓰인다면 학습이 원활하게 잘 되지 않을 것이다.
momentum update --> 아무래도 query encoder는 학습하는 속도가 빠를텐데(query 이미지 한개를 대상으로만 학습하니), 이를 key decoder 에도 적용한다면 큰 dictionary 안에 있는 모든 key 들에 대해 일관성이 없어질 것입니다(아무리 큐를 활용해 업데이트 한다고 해도, mini batch 마다 업데이트 되는 query encoder를 key encoder가 따라한다면, dictionary안에는 구식과 최신의 표현들이 뒤죽박죽 섞여있을 것이다). 따라서 이러한 query encoder 의 학습속도의 0.001만 적용한다(mini batch 동안의 backpropagation에서는 query encoder만 학습된다).
MoCo 에 대한 pseudo code는 다음과 같다.

각각의 contrastive 를 위해서는 내적을 이용하고 이에 대한 loss는 Cross Entropy Loss가 사용된다. 여기서 query encoder back propagation으로 학습이 되고 key encoder는 따로 학습이 되는 것을 알 수 있다.
Others
추가적으로 저자들은 shuffling BN을 사용했다고 하는데 이는 batch내 samples 사이에서의 leak information을 방지한다고 한다. MoCo에서는 1개의 데이터와 다른 데이터들을 구분하는 것인데, 한 데이터 feature를 본다면, same batch 내에서 other samples들을 보지 않는 것이 좋다고 하는데(이는 shortcut connection 같은 효과를 가진다고 합니다, cheat효과) 이러한 것을 BN이 수행한다고 합니다. 따라서 shuffling BN을 사용한다고 이론적으로 논문에서 말하고 있습니다. shuffling BN을 수행하기 위해 훈련에서 많은 GPU를 통해 각 sample들을 다른 GPU에 넣어 훈련을 한다고 합니다(이 부분을 직역하니 좀 이상한데 다른 분들의 설명을 보니 fq에 들어가는 샘플은 그대로 두고 fk에 들어가는 샘플의 배치 순서를 바꾸어 key, query안에 있는 통계치가 같지 않도록 해준다고 합니다. 통계치만 같지 않도록 하고 다시 배치 순서는 그대로 원상복구 시킨다고 합니)
다음은 MoCO에 대한 성능입니다.
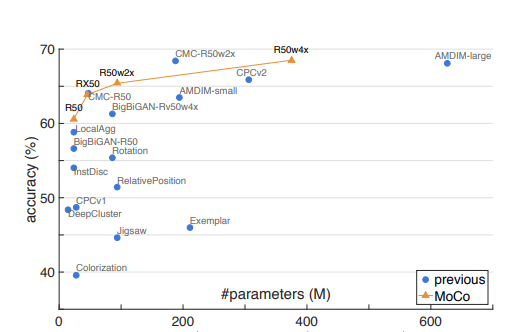
이 외에도 detection, segmentation에서도 훌륭한 성능을 가지고 있다고 합니다.
다음에는 SimCLR에 대해서 공부해보겠습니다. 틀린 부분 지적해주시면 감사하겠습니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Distilating the Knowledge in a Neural Network(2015) 리뷰 (0) | 2023.04.30 |
|---|---|
| 비전공생의 BERT(2019) 논문 리뷰 (1) | 2023.04.25 |
| 비전공생의 SimCLR(2020) 논문 리뷰 (2) | 2023.04.12 |
| Contrastive Learning 에 대한 이해 (0) | 2023.03.27 |
| 비전공자의 Self-Supervised Learning에 대해 이해해보기 (0) | 2023.03.14 |



