
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- mocov3
- WGAN
- UnderstandingDeepLearning
- tent paper
- CGAN
- 최린컴퓨터구조
- GAN
- 딥러닝손실함수
- dcgan
- 컴퓨터구조
- remixmatch paper
- ConMatch
- Pix2Pix
- CoMatch
- adamatch paper
- 백준 알고리즘
- dann paper
- CycleGAN
- Entropy Minimization
- shrinkmatch paper
- BYOL
- Meta Pseudo Labels
- conjugate pseudo label paper
- Pseudo Label
- semi supervised learnin 가정
- cifar100-c
- mme paper
- shrinkmatch
- simclrv2
- SSL
- Today
- Total
Hello Computer Vision
비전공생의 SimCLR(2020) 논문 리뷰 본문
지난 번 MoCo에 이은 SimCLR논문 리뷰! 논문의 이름은 A Simple Framework for Contrastive Learning of Visual Representations이다. 논문 말 그대로 네트워크가 정말 간단하지만 대신 그 외적으로 증강방법, loss, batch size 등을 많이 신경쓴 것을 알 수 있다.
Introduction
기존의 방법들을 소개해주는데, Generative 방법은 비용이 비싸며, representation learning에 굳이 필요하지 않으며, Disriminative 방법은 supervised learning과 비슷한 구조를 가지지만 unlabeld dataset으로 훈련시킨다고 합니다(이 부분에 대해서는 자세히 안나와있는데 효율적인 방법이 아니라는걸 설명한 거 같습니다).
representation learning을 효과적으로 하기 위해 논문에서는 여러가지 요소를 실험했는데
1. data augmentation이 중요하다
2. non linear transformation을 도입하자
3. contrastive cross entropy loss를 사용하자
4. larger batch size를 사용하자
이렇게 4가지가 있으며 논문에서는 기본적인 ResNet-50을 사용하며 그 외에는 이러한 요소들에 대해 성능 평가 위주로 진행됩니다. 이러한 요소들을 이용해 76.5% top-1 accuracy 및 SOTA를 달성했다고 합니다.
Method
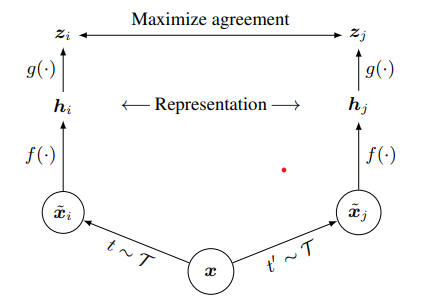
전체적인 network 의 구조는 다음과 같다.
t: 데이터 증강 방법
xi, xj : 증강하고 출력된 이미지
f: feature extractor(ResNet - 50)
g: projection head

그리고 SimCLR의 pseudo code입니다.
각 이미지 N개가 있다면(batch size) 각각의 이미지를 2개의 증강을 이용해서 증강시킨 후 (N -> 2N), 네트워크를 이용해서 임베딩 후 projection후 코사인 유사도를 이용해 측정합니다. 따라서 loss의 분자에는 기존 이미지 1개에서 증강된 다른 1개의 이미지와의 유사성만 계산되고 분모에는 이 1개를 제외한 2N-2 개의 이미지에 대해 비유사성을 계산하는 것을 확인할 수 있습니다. 훈련되는 네트워크는 feature extractor, projection head입니다. 이러한 과정을 잘 알려주는 그림은 다음과 같습니다.
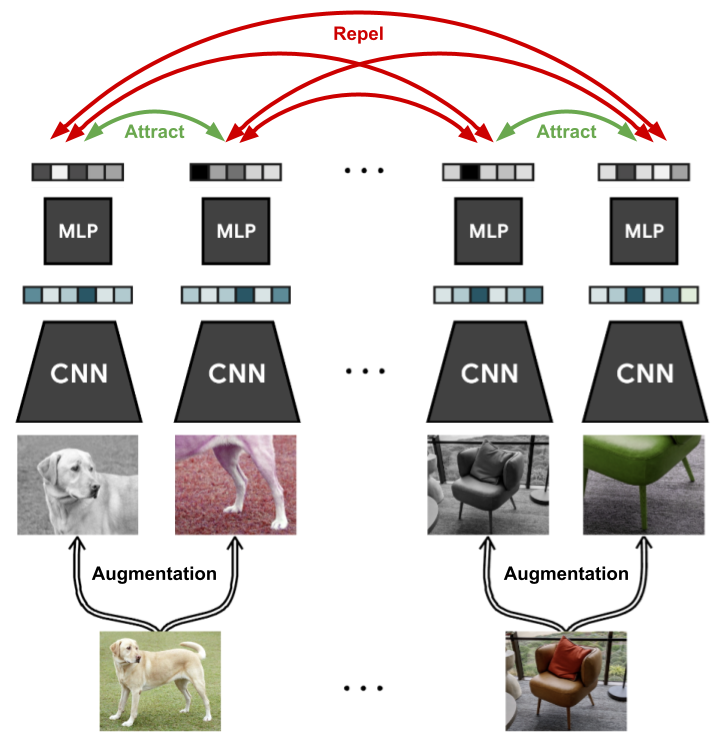
활용한 증강 방법들은 Random cropping, color distortion, random gaussian blur라고 합니다. 이와 관련하여
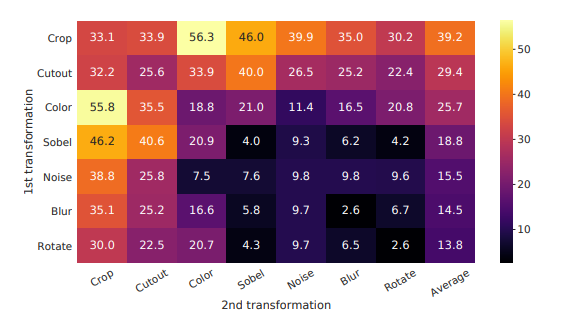
데이터 증강 방법들에 대해 실험을 하였는데 어떠한 증강도 1개만 쓰면 효과가 별로 없었다고 합니다. 그리고 기존 많은 연구들에는(ex. global-to local view prediction, neighboring view prediction 등등) 목표를 수행하기 위해 많은 복잡성을 가졌는데 여기서는 이렇게 포괄적인 목표를 달성하기 위해서는 random cropping(with resizing)이 아주 효율적이라고 합니다. 여기서 말하고자 하는건 기존의 여러 pretask 들을 위한 방법들이 있는데 이 논문에서 활용한 방법들을 사용하면(random cropping) broader 한 task 를 수행할 수 있다고 합니다.
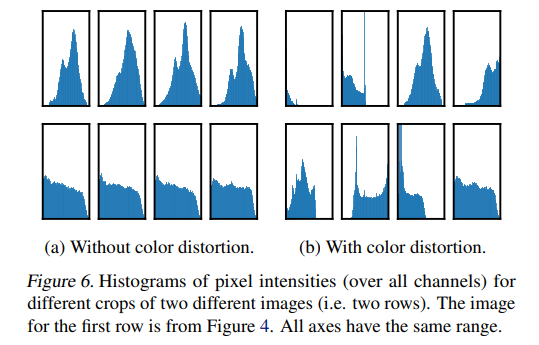
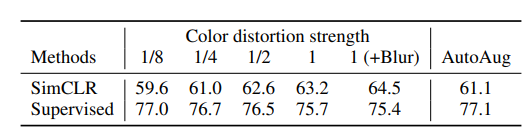
color distortion또한 적용했을 때와 하지 않았을 때의 pixel intensities와 성능에서 차이가 컸다고 하며, 이를 적용해야한다고 합니다.
저자들이 사용한 Loss는 NT-Xent loss입니다(the normalized temperature-scaled cross entropy loss)
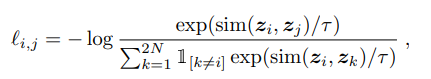
논문에서 다양한 loss에 대해서도 비교를 해놓았는데


여러 loss와 함께 gradient 를 비교한 표입니다.
1. l2 norm(코사인 유사도) 과 temperature를 쓰는 것이 효과적이다.
2. cross entropy 외 다른 loss들은 negative sample에 대해서 경중을 다루지 않았다고 합니다.
저자들은 batch size에도 관심을 가졌는데요, epoch가 더 많을수록 batch size 성능에는 큰 차이는 없었다고는 합니다. 중요한 점은 batch size가 커감에 따라 성능이 올라가는 것은 확인할 수 있는데요, 성능이 수렴하는데 큰 도움을 준다고 합니다. 아마 생각해보면 한 batch 내에서 한 이미지에 대해 더 많은 negative sample과 다르다는 것을 학습하고 분별할 수 있어서 성능이 좋아지지 않을까 생각이 듭니다.
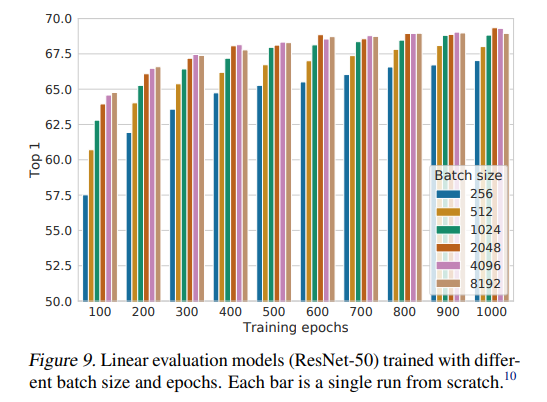
Conclusion
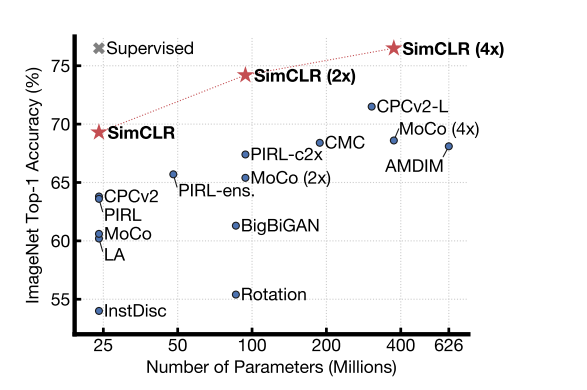
SimCLR의 성능인데요, 모델의크기가 커질 수록 supervised learning model과 비슷해지는 것을 확인해질 수 있습니다.
https://arxiv.org/pdf/2002.05709.pdf
MoCo 논문을 읽은 후라서 그런지 어렵지는 않고 여러 하이퍼 파라미터에 대해 실험한게 있어서 재밌는 논문이었습니다. 여기서 나온 NT-xent loss를 다음에는 한번 공부해볼까 합니다. 틀린점 있다면 지적해주시면 감사하겠습니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Distilating the Knowledge in a Neural Network(2015) 리뷰 (0) | 2023.04.30 |
|---|---|
| 비전공생의 BERT(2019) 논문 리뷰 (1) | 2023.04.25 |
| 비전공생의 MoCo(2020) 논문 리뷰 (0) | 2023.04.11 |
| Contrastive Learning 에 대한 이해 (0) | 2023.03.27 |
| 비전공자의 Self-Supervised Learning에 대해 이해해보기 (0) | 2023.03.14 |



