
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- BYOL
- 최린컴퓨터구조
- adamatch paper
- semi supervised learnin 가정
- mocov3
- Pseudo Label
- cifar100-c
- Meta Pseudo Labels
- CGAN
- SSL
- WGAN
- Entropy Minimization
- CoMatch
- mme paper
- shrinkmatch paper
- dcgan
- CycleGAN
- UnderstandingDeepLearning
- conjugate pseudo label paper
- shrinkmatch
- ConMatch
- 컴퓨터구조
- simclrv2
- GAN
- Pix2Pix
- remixmatch paper
- 딥러닝손실함수
- dann paper
- tent paper
- 백준 알고리즘
- Today
- Total
Hello Computer Vision
비전공생의 Supervised Contrastive Learning(2021) 논문 리뷰 본문
비전공생의 Supervised Contrastive Learning(2021) 논문 리뷰
지웅쓰 2023. 11. 21. 17:18OOD detection 에 대해서 공부하고 있는데 많은 논문들이 contrastive learning을 활용하는데 있어 이론적으로 설득력이 있어 사용하는 것이 아닌 그냥 CL을 사용하는 것을 확인할 수 있다. OOD detection에서 활용하기 위해서는 조금 다르게 사용되어야 하고 해당 논문이 많은 도움이 될 거 같아 한번 공부해보려고 한다.
논문: https://arxiv.org/pdf/2004.11362.pdf
Introduction
최근 Contrastive Learning은 Self supervised learning을 이끌고 있다. 핵심 아이디어는 Embedding space에서의 Anchor 이미지에 대하여 positive 이미지는 끌어당기고 많은 수의 negative 이미지는 미는 것이다. 보통 positive sample은 Anchor이미지에서 증강된 이미지가 사용되며 상호 정보량을 최대한으로 한다. 여기서는 논문 제목에서도 알 수 있듯이 라벨링이 데이터들에 대해 Contrastive Learning을 수행한다. 해당 논문에서의 novelty는 하나의 Anchor이미지에 대하여 여러개의 positive sample을 고려한다는 것이다(기존 연구에서는 한개의 positive 이미지만 사용되었다). 이러한 positive 이미지들은 anchor 이미지와 같은 class의 이미지들로 이루어진다고 한다.

이렇게 여러개의 positive sample을 사용하는 것만으로도 SOTA를 달성했다고 한다.
Related work
cross entropy는 굉장히 간단하고 직관적이라고 한다. 각각의 클래스는 target vector를 가진다. 그러나 이러한 target label을 주는 것이 과연 최적일지에 대해서는 불확실하며 다른 연구에서는 이에 대하여 cross entropy 단점에 대해 연구하고 있다고 한다. 다른 loss들도 제안되었지만 실제로 가장 좋은 방법은 label distribution을 변경하거나 증강 방법이었다고 한다. 그리고 Contrastive Learning에 대하여 일반적인 SSL방법에서 사용되는 가정 중 하나는 많은 negative 이미지 중에서 False negative 의 확률이 적다는 가정을 한다.
Method
구조 자체는 SimCLR과 굉장히 비슷하다고 하며 지도분류학습에서 수정한 형태라고 한다. 배치를 받으면 먼저 데이터 증강을 2개씩을 적용하고 Encoder에 들어가 2048차원의 벡터로 만들어진다. 훈련과정에서 이러한 representation은 projection network를 통해 더 propagate 한다고 한다(추론 과정에서는 projection network는 버려진다). 여기서 Supervised Contrastive loss가 해당 representation에 대하여 계산된다.
그리고 Contrastive Loss을 보자면 이를 supervised domain 으로 적용해야한다. 기존의 self supervised 에서 사용된 contrastive loss는 다음과 같다.
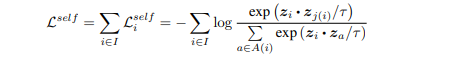
분모에는 2N - 1개의 positive, negative와 anchor이미지간의 similarity를 계산하고 분자는 anchor 이미지와 positive 이미지의 similarity를 계산한다. z는 encoder, projection network를 통과한 벡터이며, 각각의 벡터들은 내적을 하게 된다. 그러나 위와 같은 방법은 저자가 생각한 방법과는 잘 맞지 않은데 그 이유는 해당 논문에서 풀고자 하는 것은 라벨이 있기 때문이다. 따라서 위 수식을 지도학습으로 변경시키면 다음과 같다고 한다.
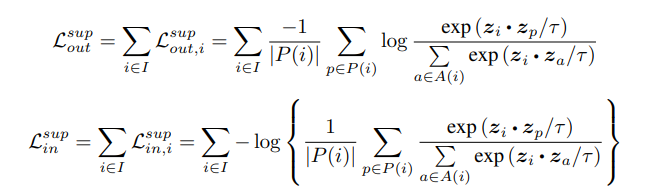
기존의 contrastive loss와 다른 것은 배치 안의 모든 positive sample이 numerator에 들어가는 것이 큰 특징이다. supervised loss를 사용함으로써 encoder는 같은 클래스의 input에 대해서는 가깝게 만들기 때문에 기존의 loss보다 더 robust한다고 한다. 기존의 식과 동일한 분모 같은 경우negative sample이 들어가므로 동일하다고 한다. 그리고 이 두개의 식을 각각 비교해보았을 때 위의 식에 대한 성능이 훨씬 좋았다고 하는데 이는 gradient 관련해서 설명한다. 따라서 이후로는 위의 식만 고려한다.
Experiments
ResNet 구조로 훈련했을 때의 성능이다.

그리고 위에서 설명한 식이 hard positive/negative mining을 수행한다고 Appendix에서 설명한다. 이에 대한 근거는 논문에 설명되어 있으므로 궁금하신 분은 보면 될 거 같고 그 뒤로 설명하는 부분에 대해서만 언급하려고 한다. easy positive sample에 대해서는 gradient 가 작으며, hard positive같은 경우 gradient 가 크다고 한다. 추가로 배치사이즈가 크면은 이러한 hard negative mining을 더 수행할 수 있으므로 더 좋은 성능을 낼 수 있다고 한다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 FlatMatch(2023) 논문리뷰 (1) | 2023.12.12 |
|---|---|
| 비전공생의 Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation(2023) 논문리뷰 (1) | 2023.12.11 |
| 비전공생의 Realistic Evaluation of Deep Semi-supervised Learning algorithms(2018) 논문리뷰 (0) | 2023.11.21 |
| 비전공생의 MoCo v3(2021) 논문리뷰 (0) | 2023.11.14 |
| 비전공생의 SimCLR-V2(2020) 논문리뷰 (0) | 2023.08.15 |



