
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- CycleGAN
- Entropy Minimization
- conjugate pseudo label paper
- remixmatch paper
- dcgan
- dann paper
- shrinkmatch
- simclrv2
- 딥러닝손실함수
- semi supervised learnin 가정
- Pseudo Label
- Meta Pseudo Labels
- CoMatch
- cifar100-c
- GAN
- mocov3
- BYOL
- mme paper
- ConMatch
- SSL
- 최린컴퓨터구조
- shrinkmatch paper
- tent paper
- 컴퓨터구조
- UnderstandingDeepLearning
- adamatch paper
- Pix2Pix
- WGAN
- 백준 알고리즘
- CGAN
- Today
- Total
Hello Data
AdaMatch(2022) 논문리뷰 본문
논문의 풀 제목은 AdaMatch: A unified approach to Semi-Supervised Learning and Domain Adapation 이다.
https://arxiv.org/abs/2106.04732
AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation
We extend semi-supervised learning to the problem of domain adaptation to learn significantly higher-accuracy models that train on one data distribution and test on a different one. With the goal of generality, we introduce AdaMatch, a method that unifies
arxiv.org
기존의 SSL 프레임워크를 가져와서 SSDA에 적용한 것이 아주 좋다는 내용의 논문이다.
Introduction
Semi supervised learning에서 unlabeled 데이터를 잘 활용하는 것은 아주 중요한데 이러한 unlabeled 데이터가 distribution shift가 일어날 경우 잘 고려를 해야한다. 해당 논문은 이러한 점에서 SSL, UDA, SSDA task에서 좋은 성능을 냇다고 한다(기존의 SSDA 논문에서는 adversarial 관련 연구들이 많은데 그냥 pseudo label을 생성하는 것이 가장 좋지 않나 생각이 든다...)
AdaMatch
기본적으로 Semi supervised learning의 알고리즘을 사용하여 UDA문제를 해결하려고 한다. 기본적인 setting은 source distribution에서 labeled 데이터를 사용하고 target distribution에서 unlabeled 데이터를 가져온다. 그리고 class의 개수는 같다. 여기서 3개의 방식을 소개하는데 logit interpolation, relative confidence threshold, modified distribution alignment이다.

위 프레임워크를 본다면 우선 기본이 되는 것은 두 distribution에서 sampling된 데이터를 같이 모델에 넣어서 batch norm을 적용해 feature를 뽑아낸 것과 source distribution에서의 데이터만 뽑아낸 데이터를 모델에 넣어 feature를 얻을 때는 batch norm을 업데이트 하지 않는다. 따라서 같은 source 데이터라도 뽑히는 feature들은 다르다고 할 수 있다. 이를 아래와 같이 표현한다.
Random logit interpolation
위에서 말했듯이 각각의 source Z는 다른데, 이를 이용해 logit interpolation을 하는 것이다.
이렇게 하는 이유는 결국 두 logit의 차이가 최소가 되도록 하는 것이 목적이라고 한다.
Distribution alignment
기존의 RemixMatch에서 사용되었던 DA이다. 만약 source, target distribution이 다를 수록 target distribution에 대한 예측값은 떨어질 수 밖에 없다. 따라서 source distribution에 대한 model의 output값을 활용해 distribution alignment를 수행하고 target distribution에 대해 더 잘맞추는 것이라고 할 수 있다.
이를 rectify the target unlabeled pseudo labels 이라고 표현한다. 언급되지 않은 단점이지만 만약 cifar100, imagenet 같이 클래스가 많으면 source data에 대해서 발견되지 않은 class가 있을 수 있고 이를 target pseudo label을 고치게 되면 악영향이 있을 수 있긴하다. 물론 이러한 부분을 아래에서 제시되는 threshold를 적용해 방지할 수 있긴하다.
저자도 언급했지만 fixmatch를 기반으로 모델이 구성되어 기존의 fixmatch에서 추가된 방법들이라고 이해해도 괜찮을 거 같다.
전체 loss는 다음과 같다.
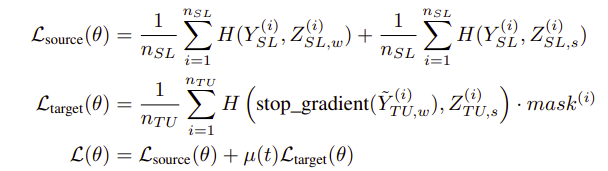
살펴보면 labeled source 데이터에 대해서는 label값을 이용해 훈련을 하고 특이한 점은 기존 weak aug, strong aug이미지에 대해서 둘 다 loss를 생성하는 것이다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| Pseudo Labeling and Confirmation Bias in Deep Semi-Supervised Learning(2020) 논문리뷰 (0) | 2024.03.27 |
|---|---|
| ShrinkMatch(2023) 논문리뷰 (4) | 2024.03.19 |
| ReMixMatch(2020) 논문리뷰 (0) | 2024.03.07 |
| Label smoothing 효과 공부해보기 (0) | 2024.03.04 |
| SelfMatch(2021) 논문리뷰 (0) | 2024.02.14 |



