
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- simclrv2
- semi supervised learnin 가정
- dcgan
- 백준 알고리즘
- CycleGAN
- Entropy Minimization
- remixmatch paper
- CoMatch
- 컴퓨터구조
- adamatch paper
- 최린컴퓨터구조
- shrinkmatch paper
- UnderstandingDeepLearning
- mocov3
- tent paper
- Pix2Pix
- Meta Pseudo Labels
- GAN
- CGAN
- dann paper
- shrinkmatch
- WGAN
- conjugate pseudo label paper
- SSL
- ConMatch
- cifar100-c
- 딥러닝손실함수
- BYOL
- Pseudo Label
- mme paper
- Today
- Total
Hello Data
ReMixMatch(2020) 논문리뷰 본문
논문의 풀 제목은 ReMixMatch: Semi supervised learning with distribution alignment and augmentation anchoring 이다.
https://arxiv.org/pdf/1911.09785.pdf
2020년에 나온 논문이고 Distribution alignment를 사용하는데 이를 사용하는 이유를 잘 살펴볼 필요가 있는 논문이다.
Introduction
SSL에서는 주로 consistency regularization, entropy minimiation이 활용되는데 여기서 entropy minimization은 high confidence prediction을 내뱉도록 모델을 훈련시키는 것이다. 그리고 큰 framework 자체는 기존의 mixmatch 의 논문을 따른다.
이 논문에서의 novelty라고 하는 첫번째는 distribution alignment인데, 해당 방법을 사용하는 이유는 p(x), p(y) mutual information을 최대화 하고 싶기 때문이다. 두번째는 augmentation anchoring인데 기존의 consistency regularization을 대체한다. 그 이유에 대해서는 consistency regularization을 수행하는 것에 대해 strong augmentation을 수행하는 것이 좋다는 논문을 인용하는데, mixmatch에서는 augmentation 이미지들에 대해 averaging 하고 이를 label을 만드는데 이러한 방식에서 strong augmentation을 수행하면 좋지 않다고 말한다(strong augmenation 을 수행하는 만큼 이미지 자체의 원본이 훼손이 되는데, 아마 부정확한 값들을 내뱉는데 이를 평균값 취하기 때문인 거 같다). 따라서 이 논문에서는 weak augmentation 취한 이미지의 결과 값에 대하여 strong augmentation적용된 이미지를 훈련한다고 보면 된다
Distribution Alignment
해당 방법은 unlabeled 데이터들에 대해 labeled 데이터와 맞추는 것이다. 이에 대한 근거로는 먼저 mutual information 이론에 대한 설명이 선행되어야한다.

x, y에 대해 상호정보량을 계산하는 것이다. 해당 수식에 대해 왜 저렇게 전개되었는지는 Appendix A에 나와있다. 해당 식은 $ I(X, Y) = H(E(Y)) - H(Y|X) $ 라고 볼 수 있다. 즉, X, Y가 상호정보량을 maximize한다는 것은 Y에 대한 entropy는 크다는 것은 Y에 대한 분포는 조금 완만해야 하며, H(Y|X)에 대한 정보량이 줄어들어야 하므로 model에 x가 주어졌을 때는 high confidence 를 가져야한다는 것과 같다. 사실 왼쪽 term은 우리가 SSL에서 추구하는 바와 반대라고 생각할 수 있다. 그래도 이를 수행하기 위해
$$ q = p_{model} (y |u; \theta) $$
라고 할 때, $ \tilde{p}(y) $를 지나간 배치 128개의 평균값의 ema 값이라고 할 수 있고(따로 언급은 없는데 class별로 평균값을 계산하지 않았을까 싶다) $ p(y) $는 labeled 데이터에 대한 확률 값이다. 즉 distribution aligment 를 활용해 다시 써보면
$$ \tilde{q} = Normalize(q * p(y) / \tilde{p}(y)) \\ Normalize(x)_{i} = x_{i} / \sum_{j} x_{j} $$
라고 할 수 있는데, 즉 labeled 데이터와 label이 같다면 이는 더 커질 것이고 아니면 작아질 것이라고 예상할 수 있다. normalize는 총 합이 1이 되도록 만들어 준다.\
Improved consistency regularization
위에서 말했던 것처럼 많은 SSL 논문이 consistency regularization을 사용한다. 그리고 이 과정에서 strong augmentation 을 활용하면 더 좋은 효과를 얻을 수 있다고 말하며 AutoAugment를 소개한다. 그러나 MixMatch에서는 strong augmentation을 적용하는 것이 큰 효과를 보지 못했다고 한다(위에서 언급). 따라서 여기서는 따로 CTAugment 라는 방법을 소개하면서 augmentation anchoring을 소개한다. 해당 방법은 weak augmentation된 이미지에 대해 anchor이미지라고 설정하고 strong augmentation된 이미지들이 이를 따라하도록 만드는 것이다. 추가로 CTAugment에 대해서도 설명을 하는데 이 부분은 넘어가려고 한다.
Putting it all together
labeled, unlabeled 데이터는 다음과 같이 정의된다.

기존의 MixMatch에서 사용되었던 Mixup이 똑같이 사용되며 unlabeled 데이터의 label값이 distribution alignment사용된 것이 다르다.
전체 loss는 다음과 같다.
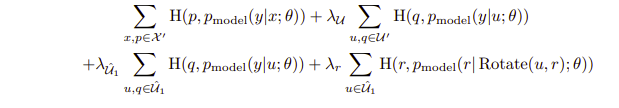
첫번째와 두번째 term은 기존의 mixmatch와 같으며, 세번째는 strong augmentation된 이미지들과 weak augmentation된 이미지들 간의 consistency regularization을 수행하며, 네번째 term은 unlabeled 데이터에 대해 rotate prediction을 수행하는 loss term이다.
Result
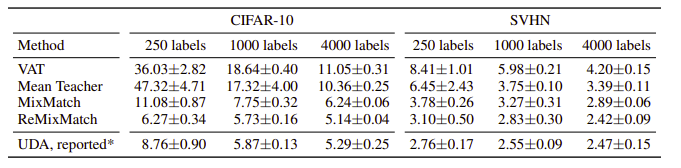
'Self,Semi-supervised learning' 카테고리의 다른 글
| ShrinkMatch(2023) 논문리뷰 (4) | 2024.03.19 |
|---|---|
| AdaMatch(2022) 논문리뷰 (0) | 2024.03.13 |
| Label smoothing 효과 공부해보기 (0) | 2024.03.04 |
| SelfMatch(2021) 논문리뷰 (0) | 2024.02.14 |
| Semi Supervised Learning에서 Pseudo label의 정확성 (0) | 2023.12.29 |



