
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- conjugate pseudo label paper
- UnderstandingDeepLearning
- 최린컴퓨터구조
- WGAN
- Meta Pseudo Labels
- Pix2Pix
- tent paper
- semi supervised learnin 가정
- CycleGAN
- mocov3
- 컴퓨터구조
- adamatch paper
- Entropy Minimization
- shrinkmatch paper
- Pseudo Label
- remixmatch paper
- dcgan
- 딥러닝손실함수
- SSL
- CoMatch
- ConMatch
- shrinkmatch
- simclrv2
- cifar100-c
- CGAN
- BYOL
- mme paper
- dann paper
- 백준 알고리즘
- GAN
- Today
- Total
Hello Data
ShrinkMatch(2023) 논문리뷰 본문
논문의 풀 제목은 Shrinking Class Space for Enhanced Certainty in Semi-Supervised Learning이다. https://openaccess.thecvf.com/content/ICCV2023/papers/Yang_Shrinking_Class_Space_for_Enhanced_Certainty_in_Semi-Supervised_Learning_ICCV_2023_paper.pdf
Introduction
많은 SSL(semi) 프레임워크는 pseudo label을 생성한 후 훈련을 진행한다. 그렇기 때문에 unlabeled 데이터에 대해 얼마나 정확한 pseudo label을 생성하는지가 모델 성능을 좌지우지한다고 볼 수 있다. 따라서 FixMatch 에서는 high confidence threshold를 걸어 높은 품질의 unlabeled 데이터에 대해서만 훈련을 진행한다. 이 방법은 굉장히 정확할 수 있지만 단점이라면 많은 수의 unlabeled 데이터가 버려진다는 단점이 있다. 따라서 저자는 이렇게 버려지는 데이터(uncertain samples)에 대해 안전하게 많은 정보를 얻을 수 있다고 믿으면서 논문을 전개한다.

위 figure를 보면 tabby cat이 정답이지만 모델은 tiger cat, siamese cat인지 헷갈려하는 모습이다. 이에 대해 top1 accuracy 는 낮지만 top-5 accuracy는 높다고 하는데 이러한 발견은 이렇게 높은 확률을 가지는 데이터가 confusion class들 때문에 헷갈려 활용하지 못하는 것에 대해 논문에서 제시하는 shrink 방법을 활용해 활용하자는 것이 주요 contribution이라고 할 수 있다.

위 표에서 super class는 20개의 class를 말한다. 즉 uncertain samples 이라 하더라도 훈련이 진행될 수록 top1의 인덱스가 super class공간에 위치할 확률이 높아진다고 한다(여기서 super class는 cifar100에서 정의된 class들로 기본적으로 cifar10의 클래스 내에서 비슷한 class들을 super class라고 한다). 위의 첫번째 그림과 다시 연관지어 설명하자면 결국 학습에 사용되지 않는 uncertain samples들은 노이즈가 너무 많아 분류하지 못한다 라기 보다는 헷갈리는 class들이 많아 높은 threshold를 통과하지 못해 사용되지 못한다. 라고 해석할 수 있다. 논문의 contribution은 다음과 같다.
1. low certainty 가 confusion class들에 의해 발생한다는 것을 처음 발견 및 해결방안 제시
2. uncertain loss에 대해 reweight
Method
기본적으로 Unlabeled 데이터에 대해서는 loss가 다음과 같이 설정된다.

이 논문을 볼 정도면 FixMatch는 기본적으로 안다고 생각해서 따로 설명하지는 않으려고 한다. 여기서 $ \xi $는 max값을 의미한다. FixMatch는 간단한 프레임워크를 사용하면서 높은 성능을 기록했지만 이렇게 해서 버려지는 uncertain samples들이 20%에 이른다고 한다. 한 측면에서 생각해보면 '많은 unlabeled 데이터에 대해 20%는 노이즈가 많으니 사용하지 않는 것이 좋다' 라고 생각할 수 있지만 논문에서는 이러한 20%도 모델 최적화에 도움이 될 것이라고 생각하면서 해결책들을 제시한다. 저자의 생각은 이 20%가 노이즈가 많아 버려지는 것이 아니라 위에서 보여주었던 것처럼 confused 한 class가 많아 버려지기 때문에 잘 활용하는 것이 목적인 것이다(아마 이러한 것은 클래스가 많은 데이터셋에 대해서 더 심할 것이며 결과적으로 더 많은 unlabeled 데이터가 버려질 것으로 추론할 수 있다. cifar10 에서는 클래스가 적기 때문에 FixMatch 방법이 높은 정확도를 기록할 수 있겠지만 ImageNet 1K 에서는 아마 높은 성능을 기록하기는 힘들 것이다).
해결책은 original class space를 shrink 하자는 것인데 간단하게 말하면 detecting, removing confused class라고 할 수 있다. 이 결과로 original class space는 confused class가 산재해있지만 shrink class space에는 이러한 confused class들이 제거된 공간이라고 볼 수 있다. 이러한 과정을 거친다면 top1 class는 threshold 를 넘는다고 한다.

위 figure는 unlabeled 데이터에 대한 프레임워크이며 간단히만 본다면 confused class가 많을 때는 여러 값들이 높지만 과정을 거친다면 top1 을 제외하고 높은 값들이 제거되면서 top1 class가 더 높아진 것을 확인할 수 있다.
이론적으로는 굉장히 좋아보이지만 어떻게 automatically 하게 이러한 shrink space(top1 class를 제외한 confused class들은 제거된 class 공간)를 찾아낼 것인지가 관건이다. 자칫 잘못하면 실제 정답 class가 top2, top3에 있을 경우 제거될 수 있기 때문이다. 우선 이것을 수행하기 위해 예측한 target 값들에 대해 내림차순으로 sort 를 한다.

s는 confidence score이고 여기서는 softmax이다. 아래 n1 은 top1 class이고 K를 통해 제약을 준다고 한다. 결국 shrink class space는 다음과 같의 정의된다고 한다. $ (n_{1}) U (n_{i})^{C}_{i = K} $ 코드를 살펴보면
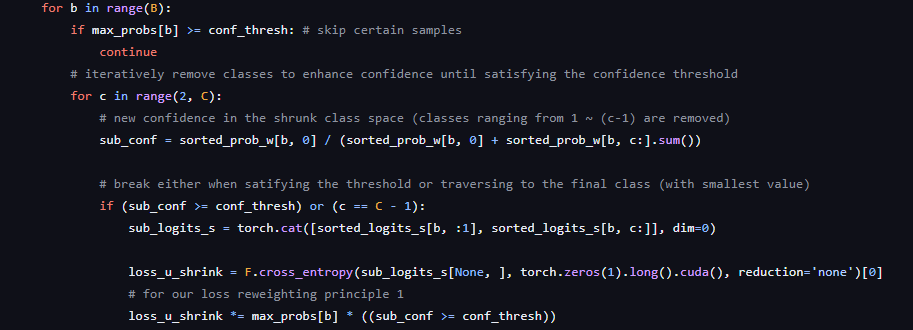
B는 배치크기이고 C는 클래스의 개수이다. 만약 confidence값을 못넘긴다면, shrink loss가 발생하는 것인데, sub conf 변수는 새롭게 만들어진 confidence값이다. 따라서 threshold를 넘는 C 값에 대해 logit을 다시 정렬해주고 loss를 발생시키는 것을 알 수 있다.
그리고 이 C에 대해 제약으 준다고 하는데 무슨 제약을 준다는 건지는 잘 모르겠다. 어찌됐든 새롭게 만들어진 weak augmentation에 대한 확률 값은 $ \hat{p} = (s^{w}_{n_{1}}) U (s^{w}_{n_{i}})^{C}_{K} $ 이와 같이 똑같이 strong augmentation 데이터에 대해서도 적용하며 아래와 같이 regularization을 준다고 한다.

잘 본다면 shrink 되기 전 weak augmentation 데이터의 confidence 값이 threshold를 넘지않는다면 loss를 발생시키는 것을 확인할 수 있는데 uncertain samples들에 대해서만 발생시키는 loss라고 볼 수 있다. 기존의 framework에서는 threshold를 넘지못한다면 버려졌다면 여기서는 이를 발생시키는 것이다. 추가적으로 weak augmentation과 strong augmentation에 대해 shrink하는 layer가 조금 다른데 둘 다 일반적으로 같은 classifier를 사용한다면 model의 confidence가 매우 공격적으로 변하게 된다고 한다. 즉 noisy samples 을 blindly하게 confidence가 높다고 판단하는 것이다(이 부분에 대해서는 명확한 설명을 하고 있지는 않다). 따라서 strong augmentation된 데이터에 대해서는 별도의 classifier를 사용한다고 한다.
이러한 방법에는 두가지 단점이 있다고 한다. 각 데이터 간의 top1 confidence 는 다를텐데 이러한 데이터를 똑같이 다루기 보다는 더 높은 confidence를 가지는 데이터에 대해 더 많은 attention을 가져야한다고 말한다. 또 다른 단점으로는 model은 훈련하면서 점진적으로 발전하는데 이를 고려하지 않는다고 말한다. 따라서 훈련 과정에 따라 uncertain samples 간 다르게 다루어야 한다고 말한다. 앞서 말한 2가지 단점을 보완하기 위해 다음과 같이 가중치들을 고려한다.

단순하게 더 높은 confidence를 가지는 uncertain samples 에 대하여 더 많은 가중치를 주는 모습이다.




맨 위의 m은 uncertain sample의 개수이다. 여기서 m은 ema를 통해 업데이트 된다. 마지막 Shrink loss는 이러한 weight들을 고려한 loss라고 할 수 있다.
저자가 이러한 방법에 대해 강조하는 부분은 informative, safe하다는 것이다. 여기서 말하는 safe에 대해서는 기존의 cross entropy같은 경우 top2, top3의 값 안에 real class가 있는 경우 top1 의 값만 올리도록 update하니 안좋다고 한다. 그러나 반대로 여기서는 fusion class들을 exclude한다고하니 안전하다고 하는데 이 부분은 조금 다시 생각해야할 부분 같다.
Result

cifar10, cifar100에서 SOTA를 달성했다고 하며

imagenet 1k 에서도 SOTA를 달성했다고 한다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| Meta Pseudo Labels(2021) 논문리뷰 (0) | 2024.03.28 |
|---|---|
| Pseudo Labeling and Confirmation Bias in Deep Semi-Supervised Learning(2020) 논문리뷰 (0) | 2024.03.27 |
| AdaMatch(2022) 논문리뷰 (0) | 2024.03.13 |
| ReMixMatch(2020) 논문리뷰 (0) | 2024.03.07 |
| Label smoothing 효과 공부해보기 (0) | 2024.03.04 |



