
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- mocov3
- CoMatch
- Meta Pseudo Labels
- 최린컴퓨터구조
- tent paper
- BYOL
- adamatch paper
- simclrv2
- ConMatch
- cifar100-c
- dann paper
- CGAN
- dcgan
- remixmatch paper
- CycleGAN
- mme paper
- shrinkmatch
- semi supervised learnin 가정
- conjugate pseudo label paper
- 딥러닝손실함수
- WGAN
- GAN
- Pix2Pix
- 컴퓨터구조
- 백준 알고리즘
- SSL
- shrinkmatch paper
- Entropy Minimization
- Pseudo Label
- UnderstandingDeepLearning
- Today
- Total
Hello Data
Meta Pseudo Labels2021 논문리뷰 본문
논문의 풀 제목은 글 제목에 적혀있다. https://arxiv.org/pdf/2003.10580.pdf
Introduction
여기서 제시하는 기존 Pseudo label의 문제는 잘못 만든 PL의 경우 악영향을 끼칠 수 있다는 것이며 이는 confirmation bias를 크게 할 수 있다는 것이다여기서말하는PL의경우일반적인SSL에서의PL이아니라pre−trained된Teacher를통해만든PL을student에게주는PL을말한다. 따라서 여기서 제시하는 해결점은 PL을 만드는 Teacher 모델도 추가적으로 훈련하는 것이다기존방식에서의Teacher의파라미터는업데이트하지않는다. 추가적으로 훈련하는 방식이 Novelty라고 할 수 있는데 이를 student 로부터 추가적으로 배운다고 한다. 그리고 최종 inference는 student 모델로 수행하며 SOTA를 달성했다고 한다.
Meta Pseudo Labels
teacher를 추가적으로 학습하는 것에 대해서 여기서는 student의 feedback을 받는다고 표현한다.

전체적인 프레임워크는 오른쪽과 같다. 추가적으로 다른 점은 teacher가 pre-trained 된 것이 아니라 같이 학습이 된다는 것이다. 그리고 notation이 여러개 나오는데, S, T는 각각 student, teacher network를 뜻하며 T(x,θT)는 teacher 모델의 prediction이다softlabel일수도있고hardlabel일수도있다.기존의방식은softlabel을사용하지만여기서는hardlabel을사용한다고뒤에서언급된다.
여기서 student는 teacher 가 생산한 많은 수의 pseudo label을 받고 학습하는데 논문에서는 이를 dependency를 가지고 있다고 한다. 이를 θS(θT)로 표현하는데, teacher network에 대해 의존적이라는 것을 표현한 듯하고 이를 function of θT라고 한다. 이를 목적함수에 한번 대입해보자면,
한번 풀어서 써보자면, 목적함수에 대한 θS를 줄이는 것이 최종목적인데 이는 θT에 의존적이다 라는 것을 표현했다. 그렇다면 기존의 pre-trained teacher로 학습한 것은 어떻게 학습되냐에 따라서 student의 줄일 수 있는 loss 한계가 있을 텐데 같이 학습함으로써 S도 줄일 수 있다라고 직관적으로 이해해도 무방할 거 같다. 이를 아래와 같이 표현한다.
한마디로 지금까지 한 말은 모두 teacher 또한 배워야 student도 잘 배울 수 있다는 것이다. 모델을 업데이트하는 공식을 한번 살펴보면,
student는 unlabeled 데이터에 대해 teacher가 준 pseudo label에 대해 학습한다근데여기서thershold가언급되지않는데,appendix를살펴보면0.95로설정한다.
teacher 는 위와 같은 방식으로 업데이트 된다. 우선 labeled 데이터에 대해 loss가 발생하는 것을 알 수 있다. Ll 안에 있는 loss는 Lu 인데 이는 기존 student에서 발생했던 loss인데 이를 아마 feedback이라고 말하는 듯하다. 보면 labeled 데이터에 대해서는 teacher 의 network로 학습하는 것을 알 수 있으며 기존 student에서 발생했던 update를 활용해 teacher 모델을 업데이트 한다. 따라서 student 는 unlabeled 데이터에 대해서만 학습을 진행하고 teacher model은 이러한 feedback과 labeled 데이터에 대해서 업데이트 해서 최적화를 시킨다고 볼 수 있다.
pseudo code이다. appendix A에는 이렇게 하는 이유에 대한 수식적인 설명이 있는데 넘어가려고 한다. 먼저 S, T를 초기화한 후 T를 통해 만든 pseudo label을 통해 S를 훈련한다. 그리고 여기서 h는 gradient 벡터들 간의 내적이므로 스칼라임을 알 수 있는데 coefficient로 활용된다. 단순히 S의 gradient 가 아닌 한번 업데이트 나서의 gradient, 업데이트 전의 gradient가 곱해지는 것을 알 수 있다(보통 모든 훈련이 끝나고 같이 update를 진행했다면 여기서는 훈련이 끝나면 먼저 update를 진행하는 거 같다.
이제 teacher를 업데이트 하는데, 먼저 unlabeled 데이터에 대해서 loss를 계산하는 것이 있는데 이 부분이 살짝 헷갈린다. 이 부분이 아마 본문에서 나왔던 student의 feedback 같은데 따로 student의 파라미터는 없기 때문이다. 아마 gradient의 내적값 coefficient를 feedback으로 표현한 듯 싶다. 두번째로는 labeled 데이터로 훈련을 하고 마지막으로는 UDAUnsupervisedDataAugmentation 방식을 활용해 consistency regularization을 사용한다. 이렇게 3개의 gradient를 합해 teacher를 업데이트 하는 것이다.
기존의 방식과는 다른 방식이라서 새롭긴 했지만 결국 confirmation bias를 근본적으로 해결했는지는 의문점이다. 이렇게 생각한 이유는 단순히 pseudo label을 훈련하는 teacher network에 대해서 추가적으로 더 훈련을 진행한다가 여기서 제시하는 해결책이기 때문이다. 물론 student의 feedback이 여기서 얼마나 큰 영향을 주는지는 모르겠다.
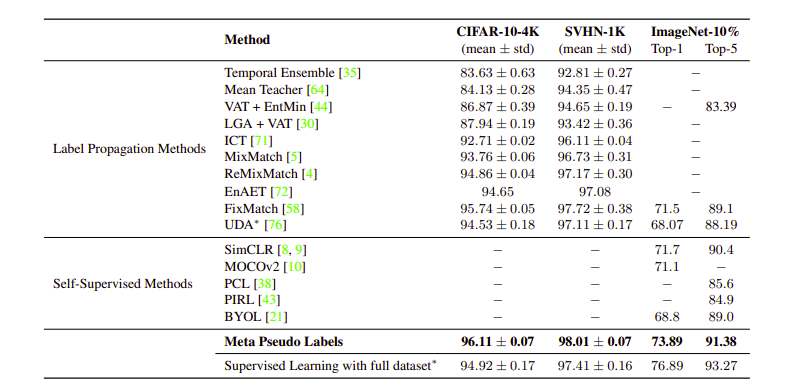
Result
'Self,Semi-supervised learning' 카테고리의 다른 글
| Pseudo Label2013 논문리뷰 0 | 2024.04.02 |
|---|---|
| Joint Optimization Framework for Learning with Noisy Labels2018 논문리뷰 0 | 2024.03.29 |
| Pseudo Labeling and Confirmation Bias in Deep Semi-Supervised Learning2020 논문리뷰 0 | 2024.03.27 |
| ShrinkMatch2023 논문리뷰 4 | 2024.03.19 |
| AdaMatch2022 논문리뷰 0 | 2024.03.13 |



