
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- remixmatch paper
- Meta Pseudo Labels
- BYOL
- CGAN
- simclrv2
- GAN
- CycleGAN
- 컴퓨터구조
- shrinkmatch
- dcgan
- Entropy Minimization
- semi supervised learnin 가정
- 딥러닝손실함수
- Pseudo Label
- CoMatch
- conjugate pseudo label paper
- shrinkmatch paper
- 백준 알고리즘
- 최린컴퓨터구조
- dann paper
- SSL
- adamatch paper
- mme paper
- Pix2Pix
- WGAN
- UnderstandingDeepLearning
- cifar100-c
- tent paper
- ConMatch
- mocov3
- Today
- Total
Hello Data
Joint Optimization Framework for Learning with Noisy Labels2018 논문리뷰 본문
Joint Optimization Framework for Learning with Noisy Labels2018 논문리뷰
지웅쓰 2024. 3. 29. 18:58논문의 풀 제목은 글 제목에 적혀있다. https://arxiv.org/pdf/1803.11364.pdf
Introduction
정제된 라벨을 가지는 데이터셋도 있찌만 noisy label을 가지는 데이터셋도 있다고 한다. 여기서 저자는 과연 DNN이 이러한 label 데이터들에 대해서 잘 훈련할 수 있는지 의문점을 던진다. 그러나 기존 연구에서도 밝혔 듯이 DNN은 어떠한 데이터셋이든 기억하는 특징이 있기 때문에 noisy label을 가지고 훈련하는 것은 우리가 원하는 방향은 아니다. 이러한 것을 방지하기 위해 dropout, early stopping 같은 regularization 방법들이 있지만 이러한 것은 최적화하는 것을 보장하지는 않는다고 한다. 여기서 말하는 contribution은 다음과 같다.
1. 단순히 주어진 label에 대하여 파라미터를 업데이트 하는 것이 아닌 noisy label도 같이 업데이트한다한마디로1step으로훈련이끝나는것이아닌2step이다.
2. high learning 을 한다면 noisy label을 기억하지 않고 잘 수렴한다.
3. 1,2와 같은 방식으로 SOTA를 달성했다.

메인이 되는 framework는 위와 같다. 직관적으로는 알 수 있지만 약간은 헷갈린다. 왜냐하면 noisy label을 joint optimization하는 것 자체가 흔한 일은 아니기 때문이다. 따라서 알고리즘 부분에는 잘 나와있지 않은데 논문 5p implementation부분에서 훈련 과정이 어느 정도 서술되어 있는데, 1epoch동안 동일하게 업데이트 및 최적화를 하지 않는다. 즉, 일정 epoch 동안 파라미터를 업데이트 하고, 어느 정도 학습된 파라미터를 통해 다시 Y를 업데이트한다. 아마 당연하게도 이렇게 업데이트한 Y는 그대로 메모리에 넣어서 다시 사용하지 않을까 싶다.
Classification with Label Optimization
기본적으로 clean label, data로 훈련하는 loss는 다음과 같다.
그리고 위에서 말했 듯이 저자는 high learning rate가 DNN이 noisy label을 기억하는 것을 억제했다고 표현한다. noisy label을 업데이트 하기 위해 다음과 같이 식을 쓴다.
한마디로 파라미터만 업데이트 하는 것이 아닌 Y도 같이 업데이트 하는 것으로 알 수 있다
전체 loss는 다음과 같이 이루어진다.
첫번째 항은 파라미터 혹은 Y를 업데이트 하는 것이고 두번째, 세번째 term은 파라미터만 업데이트하는 규제항이다. 여기서 Lc 는 KL divergence를 뜻하며 s는 softmax를 뜻하지 않나 싶다. 즉 label이 1,0,0 이 아닌 0.7,0.2,0.1 같은 noisy label일 때 이를 학습하는 것이다.
이제 2 step으로 파라미터를 업데이트하는 단계이고 이것을 Alternating optimization이라고 말한다.
첫번째로 Y를 고정한 상태로noisylabel상태로고정하는것인데이것이문제가될수있다고생각을하지만아마highlearningrate가이것을방지해줄것이다라고저자는말하는거같다 5 식으로 파라미터를 업데이트한다.
3개의 식 중에 첫번째 규제항은 다음과 같이 나타낸다.
모델이 전체 loss를 최적화하기 위해 한 class로만 예측하는 collapse 문제가 발생할 수 있다고 한다아마일반적인classification에서는이러한문제를생각할필요없지만noisylabel이기때문에고려하는거같다. 따라서 저자는 훈련 데이터에 대한 분포는 고를 것이라는 가정을 하며 ¯sj는 훈련 데이터에 대한 각 클래스의 평균값이라고 하며 여기서는 mini batch의 평균값을 나타낸다. log안에 있는 값이 클 수록 loss는 커지므로 모델이 뱉는 각 클래스의 값이 평균과 빗슷하게 내도록 규제하는 것이다.
두번째 규제항은 다음과 같다.
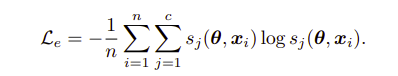
이것은 entropy minimization으로 위의 규제항과 반대로 한쪽으로 sharp하게 하는 것이다. 이렇게 까지 수행해야 고정된 noisy label에서의 파라미터가 한번 업데이트 되는 것이다.
두번째로는 noisy label인 Y를 업데이트 한다. 활용하는 loss는 기존의 5번식으로 동일하다. Y를 업데이트 하는 것이니 모델의 파라미터는 고정된 상태이다. 따라서 내뱉는 softmax 값에 따라서 noisy label Y가 update된다. hard label, soft label로 update하는 방식이 있는데, 여기서는 soft label로 update를 한다고 한다. 즉 위에서 말한 것처럼 일정 epoch에서는 파라미터만 업데이트 하니 이렇게 훈련된 모델의 파라미터로 Y를 업데이트 하는 것이다근데noisylabel로훈련했는데과연이모델파라미터가정확한지는모르겠다.
Result

CIFAR10 에 대한 정확도이다.
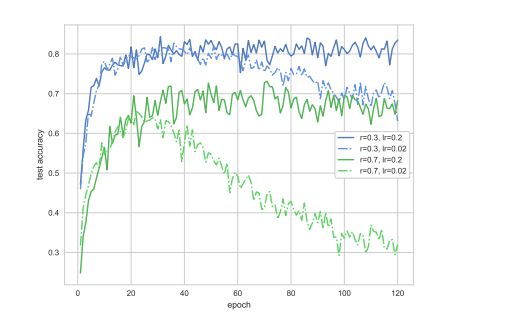
위 figure는 learning ratelr, noisy rater에 대한 figure이다. 높은 lr이 더 좋은 성능을 기록했음을 알 수 있는데 이에 대해서 배치사이즈에 대한 setting이 따로 발견하지 못했는데 이 lr이 얼마나 높은건지 알려줬으면 더 좋은 실험이 됐을 거 같다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| Entropy Minimization2004 논문리뷰 1 | 2024.04.03 |
|---|---|
| Pseudo Label2013 논문리뷰 0 | 2024.04.02 |
| Meta Pseudo Labels2021 논문리뷰 0 | 2024.03.28 |
| Pseudo Labeling and Confirmation Bias in Deep Semi-Supervised Learning2020 논문리뷰 0 | 2024.03.27 |
| ShrinkMatch2023 논문리뷰 4 | 2024.03.19 |



