
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- shrinkmatch paper
- semi supervised learnin 가정
- BYOL
- 컴퓨터구조
- WGAN
- cifar100-c
- Pix2Pix
- SSL
- CoMatch
- tent paper
- GAN
- ConMatch
- CycleGAN
- mme paper
- conjugate pseudo label paper
- 백준 알고리즘
- mocov3
- Pseudo Label
- simclrv2
- remixmatch paper
- UnderstandingDeepLearning
- 최린컴퓨터구조
- dcgan
- adamatch paper
- Entropy Minimization
- 딥러닝손실함수
- shrinkmatch
- Meta Pseudo Labels
- dann paper
- CGAN
- Today
- Total
Hello Data
Pseudo Label(2013) 논문리뷰 본문
논문의 풀 제목은 Pseudo Label: The Simple and Efficient SEmi Supervised Learning Method for Deep Neural Networks 이다. https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=798d9840d2439a0e5d47bcf5d164aa46d5e7dc26
Introduction
많은 SSL(Semi) 방법들은 Unsupervised pre-training 을 하고 (뒤에서 나오겠지만 Denoising Autoencoder를 사용한다) labeled 데이터로 fine-tuning하는 방식을 택했다고 한다. 그 외 방법들은 볼츠만 머신을 사용하거나 Semi Supervised Embedding 방식을 택했다고 하는데 이러한 부분에 대한 문제점을 딱히 언급하지는 않고 Pseudo Label 방식을 소개한다. 여기서 Pseudo Label은 Unlabeled 데이터에 대해 가장 높은 값에 대해 class를 부여하는 것이다. 이 방법을 사용하는 것에 대해서는 Entropy Regularization과 동일한 결과를 얻게 된다고 한다 (요슈아 벤지오 논문).
class probabilities 에 대한 Entropy는 class overlap 대한 지표라고 한다 (여기서 overlap의 의미는 다른 class와 얼마나 겹치는지에 대해 말하는 거 같다). 따라서 이러한 entropy를 줄이는 것은 class overlap을 줄이는 것이라고 한다 --> 즉 한가지 class로 예측하는 것이다. 이렇게 Pseudo Label을 사용하는 것은 SSL에서 주로 사용되는 cluster assumption 에 따라 class boundary 는 low density 에 그어져야 하는 목적을 부합하는 것이다.
Denoising Auto-Encoder
auto encoder를 활용해 pre-train 을 수행한다.

$ \tilde{x} $ 는 denoising 된 데이터이고 $ \hat{x} $은 예측한 데이터의 값이다. 여기서 s는 activation function을 의미하며 여기서는 아마 sigmoid를 사용하는 거 같다. 그리고 예측한 데이터와 기존 깨끗한 데이터 간의 cross entropy를 수행한다.
Pseudo Label
최근의 Pseudo Label은 threshold를 사용하는데 여기서는 pre-train 후 사용하기 때문에 threshold를 사용하지 않는다.

데이터 argmax값이 label값으로 설정하고 이 Pseudo Label은 fine-tuning에 사용하는 것이다.

n은 labeled 데이터이고 n' 은 unlabeled 데이터인데 이 개수가 다르기 때문에 weight값이 중요하다고 한다. 따라서 여기서는 T시점에 따라 annealing을 한다.
Why could Pseudo Label work
Pseudo Label이 왜 잘 작동하는지를 설명한다. 우선 SSL의 목적은 적은 labeled 데이터와 더불어 많은 unlabeled 데이터를 활용해 test error 를 줄이는 것이 목적이다. 이를 수행하기 위해 앞서 말했던 cluster assumption을 활용하는데 decision boundary 가 low density 에 놓여야 이러한 test error가 줄어들 수 있다고 한다(따라서 Pseudo Label을 활용한 Entropy minimization은 이러한 목적을 위한 하나의 방법인 것이다). 다른 방법들은 Semi Supervised embedding, Manifold Tangent classifier 이러한 방법들이 있다고 한다.
Entropy regularization은 unlabeled 데이터를 활용해 MAP 를 최대화한다고 한다. 이 방식은 unlabeled 데이터의 entropy minimization을 통해 low density seperation을 수행한다고 볼 수 있다. 사용되는 수식은 다음과 같다.

여기서 n' 은 unlabeled 데이터이다. 위에서 말했던 것처럼 entropy 는 class overlap의 measure(측정값) 이라고 할 수 있는데, 이 값이 높을 수록 많은 class가 겹친다고 볼 수 있다 (e.g., uniform 한 결과를 내뱉을 때 가장 높다). 따라서 overlap 값이 낮아질 수록 decision boundary 는 data density은 곳에 위치하게 된다.
Entropy regularization을 쓰는 이유에 대해서는 MAP 최대화 한다고 했는데, 다음과 같이 나타낼 수 있다.

여기서 n은 labeled 데이터이고 앞의 term은 Likelihood이다. 뒤의 term은 Prior로 MAP를 최대화 하기 위해서는 이 값이 낮아야하는데, 여기서 unlabeled 데이터의 entropy를 최소화 하는 것을 prior로 하는 것이다. 이러한 방법을 통해 generalization error를 줄일 수 있다고 한다.
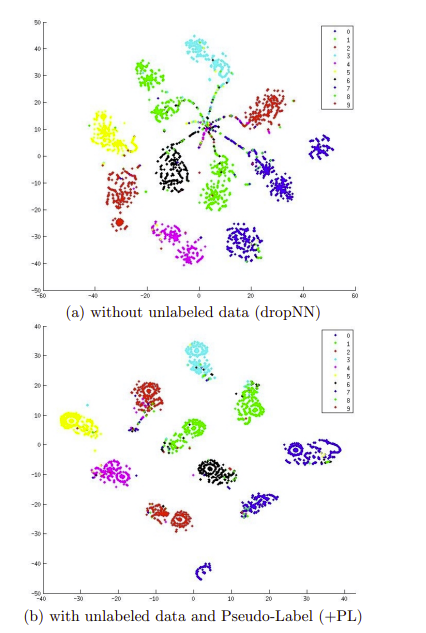
결과를 시각화 해보면 둘 다 train error(ERM) 은 0에 수렴하지만 (a) 는 labeled 데이터로만 훈련했을 때인데 unlabeled 데이터에 대해 entropy minimization을 수행했을 때 조금 더 clustering이 잘 되었음을 알 수 있다.
이 논문에서는 Pseudo Label을 사용하는 것에 대한 정당성과 이유를 보여주었다. 한계점이라고 한다면 스크래치 상태에서 pseudo label을 사용하지 않았다는 점이라고 볼 수 있다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| Consistency Regularization 설명 (1) | 2024.04.28 |
|---|---|
| Entropy Minimization(2004) 논문리뷰 (1) | 2024.04.03 |
| Joint Optimization Framework for Learning with Noisy Labels(2018) 논문리뷰 (0) | 2024.03.29 |
| Meta Pseudo Labels(2021) 논문리뷰 (0) | 2024.03.28 |
| Pseudo Labeling and Confirmation Bias in Deep Semi-Supervised Learning(2020) 논문리뷰 (0) | 2024.03.27 |



