
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- tent paper
- 백준 알고리즘
- adamatch paper
- Pix2Pix
- Pseudo Label
- CoMatch
- remixmatch paper
- dcgan
- SSL
- shrinkmatch
- 딥러닝손실함수
- GAN
- ConMatch
- cifar100-c
- simclrv2
- 컴퓨터구조
- Entropy Minimization
- BYOL
- dann paper
- mocov3
- WGAN
- 최린컴퓨터구조
- CGAN
- conjugate pseudo label paper
- shrinkmatch paper
- Meta Pseudo Labels
- mme paper
- semi supervised learnin 가정
- CycleGAN
- UnderstandingDeepLearning
- Today
- Total
Hello Computer Vision
비전공생의 BYOL(Bootstrap your own latent, 2020) 논문 리뷰 본문
비전공생의 BYOL(Bootstrap your own latent, 2020) 논문 리뷰
지웅쓰 2023. 5. 5. 17:54논문 제목은 Boostarp Your Own Latent, A new approach to self-supervised learning 입니다.
논문을 읽기 전 다른 분들의 설명을 보았는데 굉장히 흥미롭고 재밌어서 처음부터 한번 따라가볼라고 합니다.
Introduction
기존의 SOTA를 찍은 contrastive learning 방법들은 (SimCLR V2, MoCO V2) negative pairs 간의 주의한 관리가 필요하며 큰 batch size를 요한다고 합니다. 추가적으로 데이터 증강 방법에도 민감하다고 합니다. 이러한 방법들에 비해 본인들의 방법인 BYOL 은 negative pair에 민감하지 않으다고 합니다. BYOL은 2가지 네트워크 구조를 이용하는데 한가지는 target network, online network를 사용하는데 collapsed solution을 막기위해서는 두가지 모두 학습할 때 파라미터를 업데이트 하는 것이 아니라 online network만 학습하며 slow moving average 를 이용하여 target network 를 학습한다고 합니다.
2024.05.08 수정. 이 논문에서의 bootstrap 의미는 머신러닝에서의 bootstrap이 아닌 다른 의미를 가지는데, '자기 자신을 이용해 자신을 향상시킨다' 라는 의미를 가지고 있다.구조를 보면 더 쉽게 이 말이 와닿을 수 있다.
저자들이 생각하는 이 연구의 기여점은 3가지 입니다.
1. negative samples들을 이용하지 않고 SOTA한 결과를 도출했다.
2. 다른 SOTA 모델들보다 더 나은 representation을 학습했다.
3. 다른 모델들보다 더 강건하다.

성능을 나타내는 그래프이며 다른 것보다 파라미터 대비 높은 것을 확인할 수 있습니다.
Related work
기존의 방법들은 크게 2가지로 나눌 수 있는데 generative , discriminative한 방법들입니다.
Generative approach는 비용이 많이 들며, high level의 이미지를 generation하는 것이 representation 을 학습하는데 크게 필요가 없다고 합니다.
여기서 discriminative 한 방법은 contrastive한 방법들을 총 망라해서 나타내는 거 같은데, 각각의 모든 데이터들을 비교하는데 여기서 과연 이 많은 negative pairs 들이 필요한가에 대한 물음을 연구에서는 던지고 있습니다.
본인들의 방법이 기존에 나온 Predictions of Bootstrapped Latents 논문과 비슷하다고 하면서, 강화학습과 비슷한 개념이라고 합니다. 이 논문에서 Slow moving average 를 사용하는 것이 강화학습에서 활용되는 Bellman equation을 사용하는 것이라고 합니다. 이 방정식은 조금 복잡하긴 한데 가볍게 요약해보자면 recursive 한 것에 대한 합? 평균? 이라고 보시면 될 거 같습니다. 그러나 기존 강화학습 방법에서는 target network를 고정시키지만 여기서는 moving average를 통해 조금 더 smooth하게 변화시킨다고 합니다.
추가로 semi supervised 의 중요한 논문 중 하나인 mean teacher 논문에서 역시 2개의 network와 1개를 moving average 를 통해 업데이트 시키는데, 해당 방법은 classification + consistency loss 가 같이 수행되는데 만약 classification loss가 없을 경우 collapse가 일어난다고 하는데, 여기서는 classification이 없는데도 일어나지 않는다고 합니다. 구조에 대한 차이는 여기서 online network에 predictor라는 추가적인 head를 추가합니다.
Method
anchor 이미지에서 증강한 representation은 다른 증강 representation에 예측이 될 수 있을까? 라는 물음(사실 이 물음이 정확히 무엇인지는 이해를 못했습니다.. 확 다가오지 않네요..)에 positive pairs만 학습한다면 collapse가 일어난다고 합니다. 따라서 이러한 것을 방지하는 것이 contrastive 한 방법인데 이러한 방법의 단점은 많은 수의 negative samples를 필요로 하는 것입니다.
따라서 이러한 collapse 를 없애기 위한 다른 방법은 없을까? 라는 생각을 했고 가장 직관적인 방법은 target을 생성하기 위해 random 초기화된 network를 사용하는 것이라고 합니다. 그러나 이러한 방법은 collapse를 피할 수는 있지만 좋은 representation을 생성하기는 어렵습니다. 그럼에도 불구하고 이러한 방법이 아주 큰 성공을 거두었다고 합니다. random 초기화된 network에 분류를 해본 결과 1.8%의 정확도가 나왔고 이 online network를 훈련한 target network는 18.8%의 정확도를 이루었다고 하며, 이는 BYOL의 core가 됐다고 합니다.
BYOL의 목적은 downstream task 에 사용될 representation y를 배우는 것입니다.

구조를 한번 보면은 이미지 x에서 각각 증강 2개를 거치고 projection까지는 똑같은 과정을 거치지만 online network에서만 prediction과정을 거치는 것을 알 수있습니다. 그리고 이러한 output간의 l2 norm을 통해서 손실값을 구합니다.
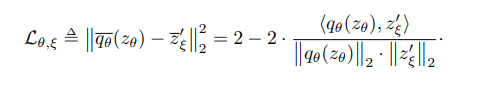
추가로 각각의 다른 증강이 쓰였기 때문에 서로 각각의 증강을 바꾸어 똑같은 과정과 손실값을 추가로 낸다고 합니다.
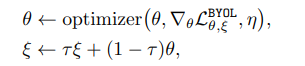
optimizer는 다음과 같이 학습하게 되고 target network는 online network에 기대어 학습하게 됩니다. 그리고 최종 목표는 다음과 같은데, target network에서 나온 projection값과 online network에서 나온 prediction값이 최소가 되고, 실제 online network의 값이 downstream task 값과 같게 나오는 것입니다.
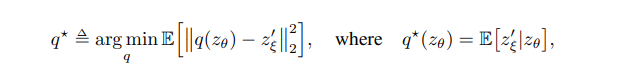
이러한 결과를 얻기 위해 SimCLR과 224크기로 맞춘 후 같은 증강 기법을 사용하였다. representation network는 Resnet 50을 사용하였고, 마지막 네트워크에는 MLP를 사용하였지만 batch norm은 사용하지 않았다고 합니다. LARS optimizer와 cosine decay 스케쥴러를 사용하였다고 합니다. 가장 중요한 부분은 512 Cloud TPU v3 core를 사용하였다고 합니다..^^
Experimental evaluation
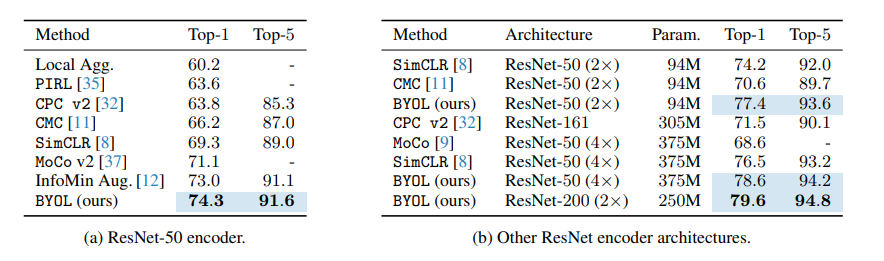
representation부분을 frozen 하고 linear classifier를 훈련한 결과 위와 같은 결과를 얻었다고 합니다. 모델의 크기가 커지면 커질 수록 성능 또한 커지는 것을 확인할 수 있습니다. 이 외에도 semi supervised protocol이나 transfer learning 결과에서도 SOTA를 찍었다고 논문에는 나와있습니다.
Building intuitions with ablations
논문 시작점에서 negative sample을 사용하지 않기 때문에 batch size가 크지 않아도 성능이 강건할 것이라 했는데, 이에 대한 결과는 다음과 같습니다.
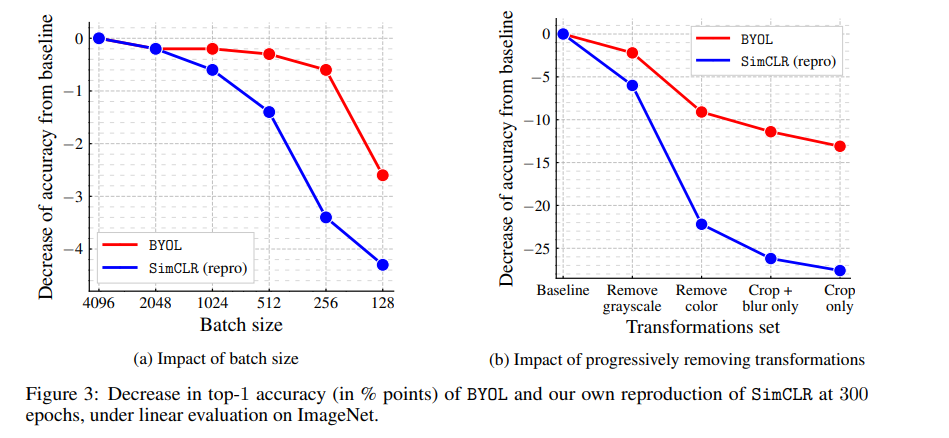
BYOL도 성능은 물론 떨어지지만 SimCLR처럼 크게 떨어지는 모습은 아닙니다(왼쪽 이미지). 그리고 데이터 증강 방법에서도 robust한 모습을 확인할 수 있습니다.
추가적으로 mean teacher 방법과도 비슷하다고 말하는데 BYOL에서 predictor부분만 없앤 것이 비지도학습의 MT라고 합니다. 따라서 결과적으로 추가적인 predictor가 collapse를 방지하는데 아주 중요한 역할을 하고 있다고 합니다.
논문을 길지 않고 재밌었지만 그 뒤에 appendix 부분이 상당한 부분을 차지하네요..(대략 20장) 이 부분에서는 연구에 대해서 실험한 것들이 더 자세하게 적혀져있습니다.
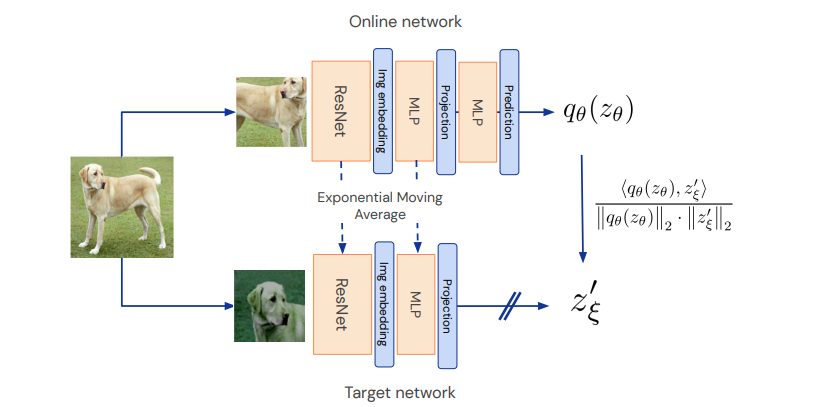
그리고 이건 논문 마지막 즈음에 있는 구조입니다.
틀린 부분있다면 지적해주시면 감사하겠습니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 SimSiam 논문 리뷰 (0) | 2023.05.15 |
|---|---|
| 비전공생의 SwAV(2021)논문 리뷰 (1) | 2023.05.07 |
| 비전공생의 Distilating the Knowledge in a Neural Network(2015) 리뷰 (0) | 2023.04.30 |
| 비전공생의 BERT(2019) 논문 리뷰 (1) | 2023.04.25 |
| 비전공생의 SimCLR(2020) 논문 리뷰 (2) | 2023.04.12 |



