
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- simclrv2
- adamatch paper
- cifar100-c
- Entropy Minimization
- CGAN
- GAN
- dann paper
- CoMatch
- WGAN
- 딥러닝손실함수
- mme paper
- 백준 알고리즘
- semi supervised learnin 가정
- Meta Pseudo Labels
- 컴퓨터구조
- dcgan
- tent paper
- shrinkmatch
- CycleGAN
- Pseudo Label
- 최린컴퓨터구조
- SSL
- UnderstandingDeepLearning
- BYOL
- Pix2Pix
- shrinkmatch paper
- remixmatch paper
- conjugate pseudo label paper
- mocov3
- ConMatch
- Today
- Total
Hello Computer Vision
비전공생의 SwAV(2021)논문 리뷰 본문
논문의 풀 제목은 Unsupervised Learning of Visual features by contrasting cluster assignments이다. 지난번에 BYOL을 리뷰했었는데 SwAV또한 성능이 좋아 많은 논문에서 비교대상으로 삼고있고, Clustering 방법을 사용하고 있어 흥미로워 읽어보았다.
Introduction
현재 많은 self supervised learning 방법들이 supvervised learning 과의 차이가 점점 들어들고 있다. 그리고 이러한 SSL 의 두가지 중요한 요소는 1) constrastive loss 2) set of image transformation이다. 이 두가지 요소는 성능에 필수적이지만 각각을 pairwise로 비교를 해야하므로 practical 하지 않다고 한다. 이 논문의 저자들은 이러한 방법없이 좋은 성능을 냈다고 한다.
기존에도 clustering을 이용한 방법도 있었지만 모든 데이터셋에 대하여 계산을 한 후에 codes(clustering assignments)를 계산할 수 있다고 한다(offline). 그러나 저자들은 이러한 방법 대신 swapped 방법을 통해 online learning을 수행한다고 하며 이러한 방법은 small batch size, small memory bank에도 잘 작동한다고 한다(뒤에서 더 자세히 나올 예정). 더 많은 view를 비교한다면 성능이 좋아지지만 기존에는 증강을 많이 활용하지 않은 것 또한 지적하며 논문에서는 새로운 증강 방법인 multi crop을 제안하였고, 이러한 smaller sized image들은 많은 view를 제공하지만 추가적인 memory나 computational cost가 들지 않는다고 한다. 작은 사이즈의 이미들을 이용하면 feature 에서 bias가 생긴다고 하지만 이는 다양한 사이즈의 이미지를 활용하면서 방지할 수 있다고 한다. 저자들이 생각하는 이 논문의 기여점은 3가지 이다.
1. Online clustering(전체 데이터셋을 계산하고 새로운 데이터에 대해 새로운 데이터에 대해 군집화를 수행하는 것이 아닌 실시간으로 가능하다는 의미인 거 같다)
2. multi crop 방식을 통해 많은 view를 얻을 수 있지만 memory에 대한 부담이 없다.
3. 위 2가지 방법과 Resnet 을 결합해 downstream task에서 좋은 성능을 내었다.
Method
저자들의 목표는 online으로 visual features를 배우는 것이라고 한다. 여기서 online, offline에 대해 더 자세히 나오는데 기존의 방법은(offline) 전체 데이터셋에 대해 clustered 된 후 다른 이미지 view에 대해 clustering 하는 작업을 수행할 수 있엇다. 그러나 이러한 방법은 모든 데이터에 대해 feature 를 계산해야 하므로 효과적이지 않다고 한다.
그러나 저자들은 codes(clustering assignment)를 target으로 하지 않고 이미지들의 view에 대하여 일관적인 mapping에 집중했다고 한다. 이러한 방법은 각각 이미지의 feature에 집중하기 보다는 각각의 clustering에 대해 comparing 하는 것에 집중했다고 한다. 조금 더 정확히 한 이미지에서 나온 feature 인 zs와 zt에 대해 각각의 군집을 계산하고 각각의 군집을 qt, qs라고 했을 때 서로의 군집을 바꾸어 이에 대한 loss를 계산했다고 하는데 식은 다음과 같다.

이미지 x에 대해 증강된 이미지를 xt라고 했을 때 non-linear mapping f 와 l2 norm을 거친 후 나온 벡터를 zt 라고 했을 때해당 벡터가 속하는 codes를 qt라고 한다. 여기서 qt가 나오는 과정은 K trainable prototype vector{c1, c2, .. ck} 라고 한다. 방금 말한 과정을 이미지로 나타내면 다음과 같다.

그리고 식1에서의 loss는 Cross entropy를 계산한다.

한 이미지 증강에서 나온 이미지 벡터 zt에서 Prototype vector matrix (trainable)C를 통해 qs에 속할 확률인 softmax를 계산하고 이를 cross entropy를 계산하는 것으로 확인할 수 있다. 여기서 qs또한 같은 이미지의 증강의 군집이므로 같아야 loss가 낮아질 것이다. 이를 전체로 풀어쓰면 다음과 같다.

이러한 방법을 online으로 쓰기 위해서는 batch안에 있는 이미지 feature들을 계산해야하고 prototype vector matrix C는 다른 배치에서도 사용된다. 그렇기 때문에 다른 이미지도 같은 code에 속하는 것을 방지한다고 한다.
(codes를 online으로 사용하기 위한 수식이 추가로 있는데 이는 잘 이해하지 못해서 패스합니다..)
성능을 다른 모델들과 비교한다면 다음과 같다.
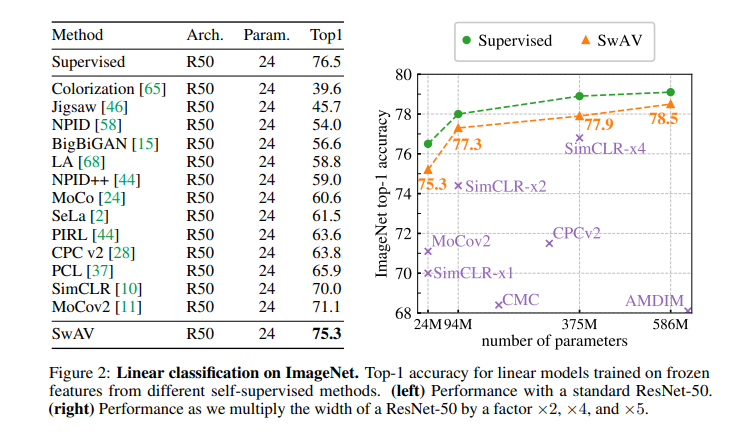
이미지를 crop해서 비교하는 것은 정보를 획득하는데 있어서 중요하지만 이러한 과정의 비용은 quadratically하게 늘어나기 때문에 힘들다고 한다. 따라서 저자들은 multi crop을 사용해 2개의 큰 이미지만을 crop하고 추가적으로 V개의 작은 해상도의 crop을 한다고 한다. 이렇게 작은 해상도의 이미지로 crop하는 것은 비용이 추가적으로 별로 안든다고 한다.
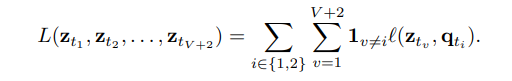
여기서 모든 croped 된 V+2개의 이미지를 모두 code계산하는 것이 아닌 V개의 작은 해상도의 이미지는 단순히 feature로만 이용하고 2개만 code계산을 수행한다. 추가로 multi crop을 SimCLR에 사용하였을 때보다 clustering method에 multi crop을 사용할 때 효과가 더 컸다고 한다. supervised 방법 때 multi crop을 사용한 건 효과가 거의 없었다고 한다.
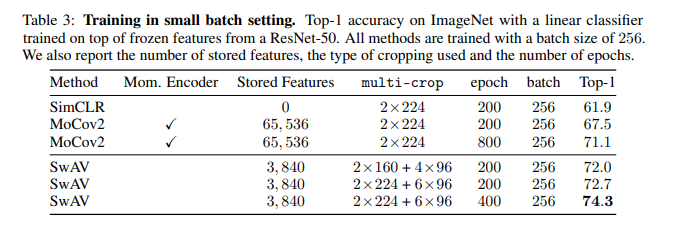
작은 batch size로 설정하였을 때 다른 구조들보다 훨씬 좋은 성능이 나오는 것을 확인할 수 있다.
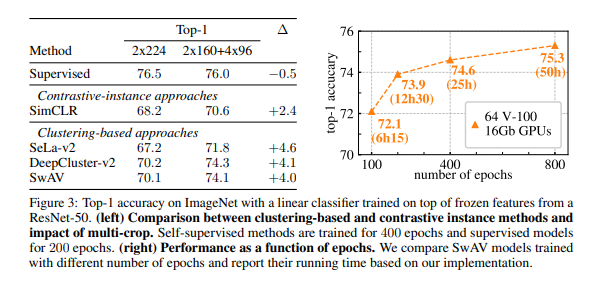
그리고 epoch수를 늘릴 때마다 성능은 늘어나는 것을 확인할 수 있다.
이는 pseudo code이다.

읽으면서 굉장히 재밌었던 논문이고 처음부터 따라가면서 제 개인적인 이해를 적었으니 틀린 부분 지적해주시면 감사하겠습니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 DINO(2021) 논문 리뷰 (2) | 2023.05.17 |
|---|---|
| 비전공생의 SimSiam 논문 리뷰 (0) | 2023.05.15 |
| 비전공생의 BYOL(Bootstrap your own latent, 2020) 논문 리뷰 (0) | 2023.05.05 |
| 비전공생의 Distilating the Knowledge in a Neural Network(2015) 리뷰 (0) | 2023.04.30 |
| 비전공생의 BERT(2019) 논문 리뷰 (1) | 2023.04.25 |



