
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- CycleGAN
- GAN
- dcgan
- shrinkmatch
- 딥러닝손실함수
- Meta Pseudo Labels
- mme paper
- 컴퓨터구조
- shrinkmatch paper
- semi supervised learnin 가정
- conjugate pseudo label paper
- simclrv2
- CGAN
- CoMatch
- 최린컴퓨터구조
- dann paper
- SSL
- cifar100-c
- Pix2Pix
- 백준 알고리즘
- mocov3
- BYOL
- WGAN
- ConMatch
- Entropy Minimization
- UnderstandingDeepLearning
- adamatch paper
- Pseudo Label
- tent paper
- remixmatch paper
- Today
- Total
Hello Data
비전공생의 SimSiam 논문 리뷰 본문
논문의 제목은 Exploring Simple Siamese representation Learning이다.
https://arxiv.org/pdf/2011.10566.pdf
Introduction
siamse network는 가중치를 공유하는데 이러한 방법은 두 개체간의 comparing 을 하는데에 효과적이라고 합니다contrastive를제외하고도. 일반적으로 Siamse 구조는 collapsing문제를 안고 있는데, SimCLR에서는 negative pair를 이용하고, SwAV에서는 clustering 방법을 사용하고, BYOL에서는 momentum update를 사용해 이러한 문제를 해결하려고 하였다.
그러나 이 논문에서는 이러한 방법들을 다 사용하지 않고 오직 stop gradient만을 사용하여 collapsing문제를 해결할 수 있다고 한다.

Simsiam 구조는 다음과 같은 구조를 띄고 있으며, 위에서 말한 핵심구조들에서 core component 한개씩을 제외한 구조라고 한다. SimCLR 에서는 negative samples, SwAV 에서는 clustering, BYOL 에서는 momentum update를 제거하였다. Siamese 구조는 자연스럽게 inductive bias 를 가질 수 있다고하는데, 그 이유로는 같은 구조에서 가중치를 공유하기 때문이라고 말한다여기서inductivebias는2개의같은input에대해서같은output내보낸다.아무리복잡한transformation이적용된다하더라도.
Method
이를 수행하기 위한 encoder f로는 ResNet을 준비하고 predictor로는 3개의 MLP layer를 준비한다. 그리고 각 similarity는 cosine similiarty를 사용하였다.
pseudo code를 살펴보면 z에서 detach를 사용하여 stop gradient를 사용한 것을 확인할 수 있다. 그리고 각각의 증강에 대하여 서로 바꾸어 수행한다.
이러한 total loss의 최소값은 -1이다.
그래서 이에 대하여 stop gradient를 사용하고, 사용하지 않고에 대하여 실험을 해보았을 때 사용하지 않았을 때 바로 -1로 수렴하는 모습을 볼 수 있지만 이에 대한 정확도가 거의 0으로 수렴했기 때문에 stop gradient를 사용하지 않았을 때 collapsing 문제가 발생한 것을 확인할 수 있다.
base line setting으로는 SGD 옵티마이저, 512 배치사이즈 , 3개의MLP layer, backbone으로는 ResNet 50을 사용하였고 이를 ImageNet 1000class label없이 실험하였다고 한다.
Empirical study
여기서는 collapsing이 일어나지 않은 이유가 네트워크 구조때문이라고 말을 하지는 않는다. 왜냐하면 구조 외에도 여러가지 요인들batchsize,mlp,...이 있기 때문이다. 그래서 저자들은 어떤 것들이 영향이 있는지 한개씩 체크해보았다.
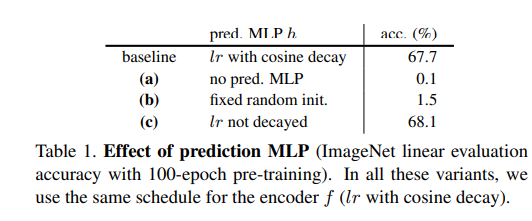
우선 MLP가 없으면은 collapsing이 일어난다고 하며, 추가로 학습률에 대해서 decay 를 사용하면 약간의 성능저하가 일어났다고 한다. 그리고 MLP 에 대해서 random 초기화를 하면 collapsing이 일어나지는 않았지만 학습이 제대로 수렴하지 않는다고 하였다.
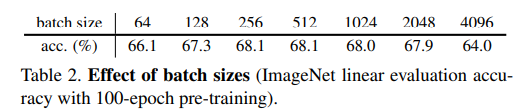
배치사이즈에 대해서는 너무 크고, 너무 작으면 성능저하가 일어나는 것을 확인할 수 있다. 이에 대해서 옵티마이저로 SGD를 선택한 경우 큰 배치사이즈는 안좋다고 말하는데 결과적으로 옵티마이저는 collapsing에 대해서 크게 영향은 없다고 말한다.

배치정규화의 경우 적절하게 사용할 경우 성능의 향상은 됐지만 collapsing과는 직접적인 연관을 찾지는 못했다고 한다.

위에서 언급한 내용 말고도 저자들이 가설을 세워 왜 collapsing이 일어나지 않는지 실험한 부분들도 있지만 이는 잘 이해할 수 없어서 패스.. 결과에 대한 table을 한번 살펴보자면 batch size가 크지 않고도, epoch가 적었을 때 가장 좋은 성능이 나오는 것을 확인할 수 있다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 MAEMaskedAutoEncoder,2021논문리뷰 0 | 2023.05.18 |
|---|---|
| 비전공생의 DINO2021 논문 리뷰 2 | 2023.05.17 |
| 비전공생의 SwAV2021논문 리뷰 1 | 2023.05.07 |
| 비전공생의 BYOLBootstrapyourownlatent,2020 논문 리뷰 0 | 2023.05.05 |
| 비전공생의 Distilating the Knowledge in a Neural Network2015 리뷰 0 | 2023.04.30 |



