
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- remixmatch paper
- CycleGAN
- conjugate pseudo label paper
- ConMatch
- Entropy Minimization
- 컴퓨터구조
- cifar100-c
- CGAN
- tent paper
- BYOL
- GAN
- Pix2Pix
- 최린컴퓨터구조
- Meta Pseudo Labels
- mme paper
- simclrv2
- semi supervised learnin 가정
- adamatch paper
- WGAN
- shrinkmatch paper
- UnderstandingDeepLearning
- dann paper
- mocov3
- CoMatch
- Pseudo Label
- SSL
- dcgan
- 백준 알고리즘
- 딥러닝손실함수
- shrinkmatch
- Today
- Total
Hello Data
비전공생의 DINO2021 논문 리뷰 본문
지난번 Simsiam 에 이어 Facebook에서 2021 년에 발표된 SSL논문 DINO입니다. DINO는 self-distilation with no labels 을 줄인말입니다.
https://arxiv.org/pdf/2104.14294.pdf
Introduction
이 논문에서 저자들은 vision 분야에서의 ViT의 성공이 과연 SSL에서도 성공할 수 있을지에 대한 물음에서 시작되었다고 합니다. 기존 supervised learning 방법으로는 이미지의 visual information이 줄어들었는데 CNN을 이용한 SSL에서는 이러한 정보가 증대되었기 때문에 ViT를 이용한 SSL에서도 과연 이러한 것이 똑같이 적용되는지 궁금했다고 합니다.
저자들이 생각하는 ViT를 이용한 SSL의 주요 특징이라면
1. 물체의 윤곽선을 잘 잡는다.
2. kNN classifier에서 월등한 성능을 보인다 입니다.

위에서 언급한 것처럼 이에 대한 map을 시각화해보면 아주 정교한 것을 알 수 있습니다.
저자들은 smaller patches들을 활용하면 성능에 좋았고, collapse 를 줄이기 위해서는 centering, sharpening 방법을 사용하여서 이를 방지했다고 합니다. 본인들의 방법으로는 ResNet을 backbone으로 사용하여도 성능이 좋았다고 하며, 전체적인 구조는 다음과 같습니다.
두 네트워크는 구조는 같지만 weight를 공유하지는 않습니다. 또한 teacher network의 가중치는 student에 따라 업데이트 됩니다.
추가적으로 다른 Knowledge distilation을 활용한 SSL방법과 다른 점은 teacher network가 pre-train 된 것이 아닌 scratch부터 student랑 같이 학습된다는 점에서 다르다고 할 수 있습니다.
Related work
이전에 나왔던 BYOL과 비슷하다고 말하면서 저자들은 DINO는 no labels란 것에 주목합니다. 또한 이전에 knowledge distilation이 soft labels일 때 성능이 좋았다라는 연구들을 바탕으로 self-training 과 distilation이 아주 중요한 연결을 가지고 있다고 말합니다.결국DINO에서는noisystudent로훈련하는teachernetwork를사용하는것인데,2019년에labelsmoothing이왜좋은지에대해제프리힌튼이쓴논문에서는labelsmoothing이knowledgedistilation에서teacher의성능은올라갔지만student의성능은좋지않다고말한다
저자들은 이러한 연결이 no labels들을 훈련하는 것으로 연장했다고 합니다. 다른 연구들은 teach networks들을 pretrained 방식으로 fixed 시켰다면 여기서는 student를 훈련하는 와중에도 teacher는 계속 업데이트 되는, 즉 codistilation이라는 용어를 사용하였습니다.
Approach
DINO의 알고리즘 pseudo code를 보면 다음과 같습니다.
이미지에 각각 다른 증강들을 적용하고, loss는 crossentropy를 사용하는 것을 알 수 있습니다. 보면서 느낀건 swav처럼 clustering 방법처럼 엄청 복잡하지는 않을 거 같다라는 점?
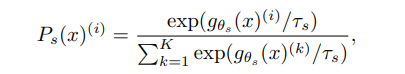
g는 네트워크이고, P를 K개의 dimensions에 대한 probability distribution을 나타냅니다. t는 0보다 큰 temperature parameter이고 이 paper에서 말하는 sharpness를 컨트롤합니다. 그리고 이렇게 얻어진 Ps 분포를 teach 분포인 Pt의 차이를 구하는데 crossentropy를 사용하며
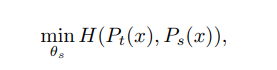
이렇게 나타낼 수 있습니다. 그리고 loss를 구하는 과정에서 한개의 이미지에서 V개의 서로다른 view를 생성하는데, 2개의 global view를 생성하고, V-2개의 local view를 생성합니다. 그리고 이러한 local view들은 student network를 통과하고, global view는 teach network를 통과하는데 이를 local to global 이라고 저자들은 표기하고 수식으로 나타내면 다음과 같습니다.
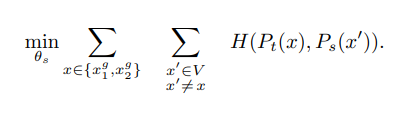
teacher nerwork를 학습할 때는 단순히 student 의 가중치를 복사하는 것은 gradient가 수렴하지 않았으며 EMA방식을 사용하는 것이 성능이 좋았다고 합니다.
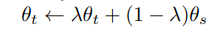
여기서 학습률을 조정하는 파라미터는 cosine scheduler를 사용하여 0.996~1을 조절했다고 합니다. 또한 저자들은 이러한 방식이 teacher network의 성능이 student보다 좋았다고 하는데 모델 앙상블의 효과가 있었다고 말합니다.
많은 SSL방법들이 다른 것은 collapse를 피하기 위해 방법들이 달라지는데, contrastive loss, clusterin 등등이 있습니다. DINO에서는 sharpening과 centering 을 이용했다고 하는데, 이를 설명해보면 centering은 한개의 dimension이 dominate하는 것을 방지하고, uniform distribution을 띄는 것을 의도하며, sharpening은 이와 반대의 효과를 가진다고 합니다. 서로 상충되는 방법들을 통해 collapse 를 피햇다고 합니다. sharpening은 위에서 말했던 것처럼 softmax에서의 사용됬던 temperature 이고 centering은 다음과 같은 수식을 이용합니다.
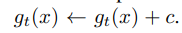
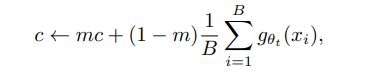
이를 논문에 나와있는 그대로 한번 설명해보면, c라는 bias term 을 teacher에 추가하는데 이 c또한 EMA를 통해 업데이트 되는 것을 확인할 수 있습니다이를아직코드로안봐서알수없지만예상으로는softmax들어가기전logit에c라는것을추가하는것이아닌가싶습니다.

추가) 페이스북 깃헙에 있는 DINO loss 관련 코드입니다. 잘 보면 self.center 값을 따로 주어 teacher output에 빼주는 것을 확인할 수 있는데 logit값에 일정값을 빼주거나 나누어 작게 만들어 분포가 uniform하는 것을 유도하는 것으로 보입니다.
훈련시킬 때는 1024의 배치사이즈, 16gpu, 학습률은 0.0005 * batch/256, adamw 옵티마이저, cosine scheduler weight decay를 사용했다고 합니다. 또한 sharpening 에 사용한 t의 경우 0.04~0.07로 30epoch동안 사용했다고 합니다. t는 1보다 크면 오히려 centering 하는 효과가 있으니 1보다 작은 값을 가집니다. 이에 대한 결과는 다음 표에 있습니다.
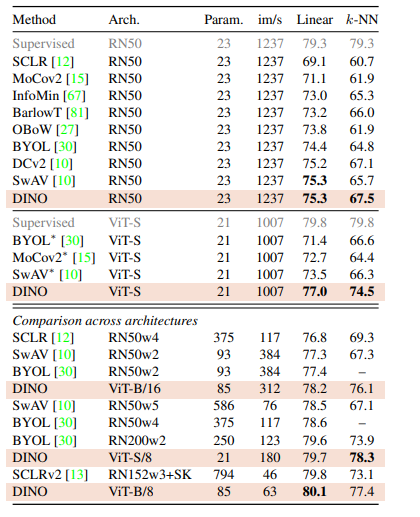
Result
이 외에도 처음에서 언급한 것처럼 물체를 찾아내는데 아주 좋은 성능을 보였습니다.
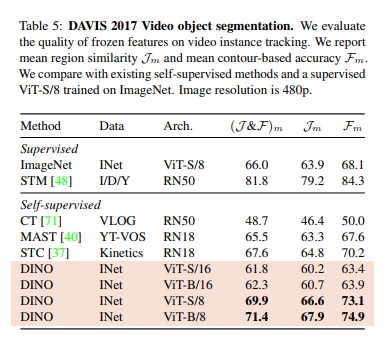
다음 자료는 momentum 을 사용하였을 때 teacher 의 성능이 앙상블한 효과를 내는 것 같은 결과입니다.
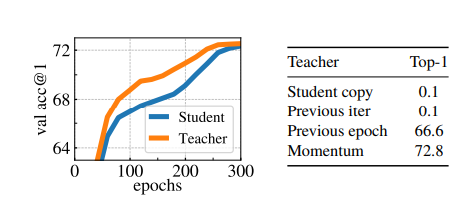
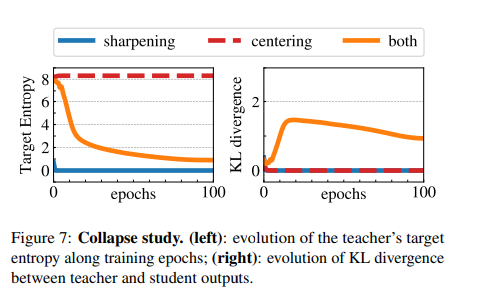
아래 표는 sharpening과 centering 둘 다 사용하였을 때 잘 수렴하는 것을 나타낸 것입니다. 한개만 썼을 때는 collapse가 나타나는 것을 확인할 수 있습니다.
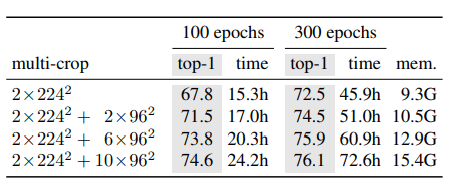
다음은 16gpu를 사용하였을 때의 시간과 memory사용량인데 BYOL에 비교해서는 학습시간이 그렇게 길지 않다는 것을 확인할 수 있습니다.
다음 표들은 기존 MoCo, BYOL, SwAV와 비교한 표들입니다.
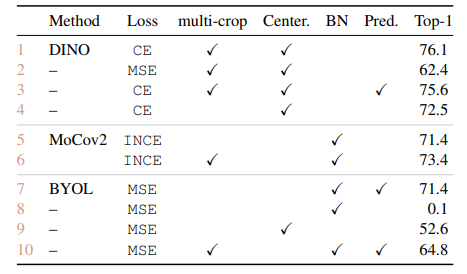

여기서 swav의 sinkhorn-knopp 은 softamax와 비슷한 효과라고 말하며, momentum encoder만 사용하여도 collapse는 어느정도 방지할 수 있다고 합니다.
이번에 DINO 논문을 살펴보았는데, 구조가 크게 어렵지 않았고 다른 방법들과의 비교를 통해 이게 정답이다! 라고 말해주는 것 같아 재밌었습니다. DINO에 대한 코드를 구경한 후 다음에는 MAE 를 읽어볼 예정입니다. 제 개인적인 이해를 담았으니 틀린부분있다면 지적 바랍니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 What do self-supervised ViT Learn?2023 논문 리뷰 0 | 2023.05.21 |
|---|---|
| 비전공생의 MAEMaskedAutoEncoder,2021논문리뷰 0 | 2023.05.18 |
| 비전공생의 SimSiam 논문 리뷰 0 | 2023.05.15 |
| 비전공생의 SwAV2021논문 리뷰 1 | 2023.05.07 |
| 비전공생의 BYOLBootstrapyourownlatent,2020 논문 리뷰 0 | 2023.05.05 |



