
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- simclrv2
- shrinkmatch
- 딥러닝손실함수
- mme paper
- adamatch paper
- CoMatch
- Meta Pseudo Labels
- shrinkmatch paper
- WGAN
- CGAN
- semi supervised learnin 가정
- Pix2Pix
- cifar100-c
- dann paper
- 최린컴퓨터구조
- dcgan
- ConMatch
- UnderstandingDeepLearning
- SSL
- GAN
- mocov3
- BYOL
- tent paper
- Entropy Minimization
- 컴퓨터구조
- remixmatch paper
- 백준 알고리즘
- Pseudo Label
- CycleGAN
- conjugate pseudo label paper
- Today
- Total
Hello Data
비전공생의 MAE(Masked AutoEncoder, 2021)논문리뷰 본문
SSL을 contrastive부터 공부하면서 최근 트렌드인 MAE까지 도착했네요.. 아직 안읽은 논문들도 많을 것이라 생각하지만 지금껏 읽어왔던 것처럼 천천히 다 읽는 것을 목표로 해보겠습니다.
https://arxiv.org/abs/2111.06377
Masked Autoencoders Are Scalable Vision Learners
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we
arxiv.org
Introduction
NLP에서는 masked autoencoder방식인 BERT가 잘 작동한 방면 비전분야에서는 그만큼의 성과는 없었다고 합니다. 따라서 저자들은 왜 masked autoencoding 방식이 NLP 와 CV에서 다른 성능을 보일까 라는 질문으로부터 해답을 얻고자 합니다.
첫번째는 구조적인 차이입니다. 이전부터 NLP는 attention을 활용한 반면 CV는 2021년 전만 하더라도 CNN이 dominant했다고 합니다. 이러한 구조는 mask tokens, positional embedding을 통합할 수 없었다고 하는데요, 정확히 이해는 못했지만 CNN은 지역적인 정보들을 integrate하므로 기존 NLP과의 구조가 다르다. 라고 이해하였습니다. 그러나 이러한 장애물은 ViT가 나오면서 해결되었다고 합니다.
두번째는 information density입니다. 언어는 highly semantic, information dense한 반면 이미지는 그렇지 않다고 합니다. 직관적으로 생각해도 언어는 형용사, 명사, 등등 모두 중요하지만 이미지의 경우 픽셀 몇개가 masking된다고 큰 차이는 없을 거 같은데 이를 information density라고 표현합니다. 또한 NLP에서는 10%정도를 masking하는데 이미지에서 이정도를 masking한다면 근처 픽셀간의 정보들을 통해 recover할 수 있다고하니 학습이 제대로 이루어지지 않을 거 같습니다. 이러한 부분은 아주 높은 비율의 masking을 통해 해결했다고 합니다.
세번째는 decoder입니다. NLP에서의 decoder는 간단한데 mlp를 사용한다고 합니다. 그러나 비전에서 latent representation을 제대로 표현하기 위해서는 decoder역할이 아주 중요하다라고 저자들은 생각했습니다. 따라서 encoder와 symmetric하지 않은,조금 더 작은 구조를 택했다고 하는데 이는 computation에서 아주 큰 감소를 이루었다고 합니다.

이는 아주 높은 ratio의 masking을 적용해도 훌륭하게 representation을 뽑아낸 것을 확인할 수 있습니다.
Approach
기존의 AutoEncoder 는 대칭인 구조를 가지고 있는데 MAE에서는 asymmetric한 구조를 택했다고 합니다.
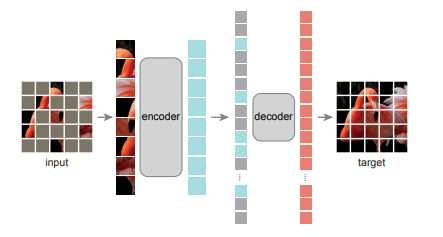
예전에 이 구조를 봤을 때는 별 생각없었는데 encoder 보다 decoder의 구조가 더 작은 것을 알 수 있습니다. 또한 input을 여러 패치로 쪼갠 후 masking된 패치는 encoder에 넣지않기 때문에 encoder의 구조를 더 크게 만들 수 있었다고 합니다. Masking하는 방법에 대해서는 여러 방법들이 후보에 있었으나 random sampling하는 방법을 택햇다고 합니다. uniform distribution을 사용하였는데 이로 인해 center bias를 방지할 수 있었다고 합니다. 이에 대해서는 자세히 안나왔는데 만약 일반적인 정규분포를 사용해서 masking을 했다면 이미지의 중간 부분 위주로 masking될 수 있었다는 내용을 말하는 거 같습니다.


decoder의 구조같은 경우 encoder와는 독립적이며 한 패치를 다루는 계산량에서 encoder의 10%도 되지 않는다고 합니다. decoder가 만들어낸 target에 대해서는 MSE loss를 사용하였고, 이는 BERT와 비슷하다고 합니다. 또한 MSE를 사용하는 과정에서 pixel들은 정규화 과정을 거친 후에 loss가 적용됬다고 합니다.
구조자체는 간단해서 이 장에서 말한 여러가지 부분들을 뒷 장에서 성능표로 나타내었습니다.

masking ratio를 살펴보면 저자들이 택한 75%에서 linear probing 에서 가장 좋은 성능을 나타냄을 알 수 있습니다. 10%밖에 하지 않아도 fine tuning단계에서는 꽤 높은 성능을 보여줍니다.
이 외에도 decoder의 depth, width에 대해서도 성능표를 나타내었고 크게 성능차이는 나지 않았습니다.

그리고 SSL에서 나름 중요하게 생각했던 증강방법에 대해서도 놀랄만한 결과가 나왔는데요, SimCLR의 논문에서는 어떠한 증강이 좋다라는 것이 논문의 주가 될만큼 contrastive 방법에서는 중요했는데, MAE에서는 사용하면 성능이 약간 상승했지만 사용하지 않아도 나쁘지 않았다라는 결과를 얻게됩니다. 저자들은 이미 random sampling으로 masking하는 것 자체가 데이터 증강 효과를 얻었기 때문이라고 분석합니다.

Result
기존의 SSL방법들과 비교를 해보았을 때 간단하고 빠르면서 좋은 성능을 냈다고 합니다.

MAE는 1600 epoch를 훈련하는데 31시간이 걸린반면 MoCov3는 300 epoch를 하는데 36시간이 걸렸다고 합니다.
이 외에도 detection, segmentation분야에 대해서도 transfer learning을 했을 때 좋은 성능이 나왔다고 합니다.

저자들이 이러한 autoencoding하는 방식이 NLP방식에서 큰 효과를 누린만큼 비전분야에서도 큰 활약이 있을 것이라 예상합니다. 그러나 이미지와 언어는 기본적으로 다르고 신경써야할 부분들이 있으므로 이를 조심히 다루어야한다고 조언합니다.
DINO에 이은 MAE논문을 읽어보았는데요, 최근으로 갈 수록 구조들이 간단해지고 왜 성능이 나오는지에 대한 고찰이 더 커지는 거 같습니다(물론 하드웨어, 데이터양의 차이가 있겠지만). 앞으로 연구할 때도 무작정 코드를 만지는 것보다는 어떤 방식으로 접근할지에 대한 충분한 브레인스토밍이 선행되어야 좋은 결실을 맺을 것 같습니다.
다음 읽어볼 논문으로는 SSL이 어떤 것을 배우는지에 대한 논문을 읽어볼 예정입니다. 한국인 분이 쓰신 논문이고 ICLR 2023 따끈따끈 논문이므로 앞으로 SSL공부하는데 큰 도움이 될 거 같습니다. 그 이후로는 DeiT, BeiT 를 추가로 공부해볼 예정입니다. 이 글은 제 개인적인 이해를 담았으므로 틀린부분있다면 지적해주시면 감사하겠습니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 BEiT(2021) 논문 리뷰 (0) | 2023.05.24 |
|---|---|
| 비전공생의 What do self-supervised ViT Learn?(2023) 논문 리뷰 (0) | 2023.05.21 |
| 비전공생의 DINO(2021) 논문 리뷰 (2) | 2023.05.17 |
| 비전공생의 SimSiam 논문 리뷰 (0) | 2023.05.15 |
| 비전공생의 SwAV(2021)논문 리뷰 (1) | 2023.05.07 |



