
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 최린컴퓨터구조
- WGAN
- Meta Pseudo Labels
- Pix2Pix
- GAN
- SSL
- conjugate pseudo label paper
- adamatch paper
- CycleGAN
- Entropy Minimization
- shrinkmatch paper
- mme paper
- 딥러닝손실함수
- tent paper
- dann paper
- dcgan
- ConMatch
- cifar100-c
- semi supervised learnin 가정
- simclrv2
- CoMatch
- UnderstandingDeepLearning
- BYOL
- CGAN
- mocov3
- 백준 알고리즘
- shrinkmatch
- Pseudo Label
- remixmatch paper
- 컴퓨터구조
- Today
- Total
Hello Data
비전공생의 BEiT2021 논문 리뷰 본문
논문의 풀 제목은 BEiT: BERT Pre-Training of Image Transformers 이다.
https://arxiv.org/pdf/2106.08254.pdf
지난번 MAE 에 이은 BEiT논문 리뷰인데 구조자체와, 메커니즘은 비슷한 거 같다. 그러나 유명한 논문이기 때문에 한번 정리하고 싶은 마음이 커서 읽어보려고 한다.
Introduction
Transformer는 비전분야에서 큰 성과를 냈지만 이러한 성과에는 CNN보다 많은 training data가 필요하다고 한다. 그렇기 때문에 이러한 데이터 문제를 해결하기 위해 SSL방법을 transformer에 접목시키자 한다.
같은 시기 masked language model인 BERT가 좋은 성능을 내었는데 이에 저자들은 denoising auto encoding 방법을 vision transformer방법에 사용하는 것에 관심을 들였다. 그러나 이러한 방법을 이미지에 직접 적용하기는 어려웠는데, 그 이유는 NLP와는 달리 이미지는 pre-exist 한 vocabulary가 없었고이뜻은아마NLP에는불용어라든가,stopwords등이렇게미리정의된사전이있는데이미지는따로없다는것을말하는거같다 pixel단위로 다 recover하는 것은 model capability를 낭비하는 것이라고 말한다. 따라서 저자들은 이러한 부분들을 극복하려고 노력했다고 한다.

따라서 위와 같은 구조를 세웠다고 한다. 이미지는 2가지로 나뉘게 되는데 첫번째는 ViT에서 자주 쓰이는 것처럼 패치단위로 나뉘게 되고 일부는 masking된다회색부분. 두번째로 이미지는 tokenizing 되는데, 이러한 discrete 한 token들은 discrete VAE에 의해 latent로 code로 변환된다고 한다. 따라서 모델은 마스킹된 부분들을 기존 이미지의 부분을 recover하는 것을 목적으로 한다픽셀단위recoverx.
저자들이 말하는 contribution은 다음과 같다.
1. MIM, transformer 결합 모델 제시.
2. BEiT를 활용해 downstream task 실시.
3. 이러한 방법을 활용해 human annotation없이 좋은 성능.
Methods
위 introduction에서 dVAE를 tokenizer로 사용한다 했는데 여기에는 tokenizer, decoder로 이루어져 있다. tokenizer qz|x로 image x를 discrete tokenzing 하고, decoder px|z는 z가 주어졌을 때 x를 잘 복원하도록 한다. 각 이미지는 14x14 픽셀로 분해되며 각 vocaburaly size는 8192이다여기서말하는vocabularysize는embedding이라고봐도무방한거같다.
backbone 구조로는 transformer를 사용하며, 각 토큰들 + special token 기존ViT에서보면clstoken같긴한데여기서는명확히나와있지않다 + pos embedding 이 transformer encoder에 들어가게된다.
BEiT에서는 masekd language modeling 에 영감받아 masked image modeling을 실시하며, 40%의 토큰을 masking한다. 기존 MAE와는 다르게 여기서는 masking된 patch들 또한 encoder에 들어가고 softmax를 통해 출력값이 나타나게 된다.
pretraining objective는 다음과 같다고 할 수 있다.
M은 masking된 image patch를 뜻하고, 이에 tokenizing된 것을 기존에 것과 유사도가 최대로 하는 것이 목적인 것이다.
추가로 저자들은 random masking을 하는 것이 아니라 block wise masking방법을 택했다 하는데 pseudo code를 봐도 잘 이해하지 못했다..
하이퍼 파라미터들을 살펴보면, 12layer, 768 dim size, 12개의 attention head로 이루어져있다. imagenet 1K로 pretrain했고, 2000 batch size로 800회 훈련했다고 한다. Adam 을 사용했고 5일동안 훈련했다고 한다.
pre-train 이 끝난 후 classification을 수행할 때는 마지막에 linear layer를 task layer로 설정했고, semantic segmentation을 수행할 때는 SETRPUP를 추가했다고 한다.
Experiments
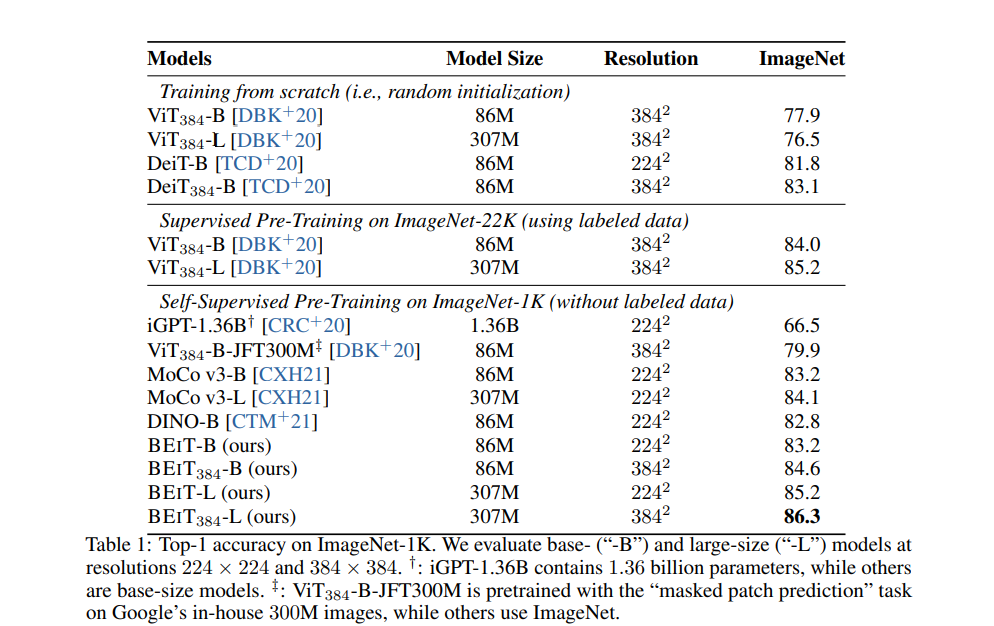
결과표는 다음과 같다. 모델 크기가 차이가 나기는 하지만 DINO, MoCo 와 비교했을 때 더 우수한 것을 확인할 수 있다.
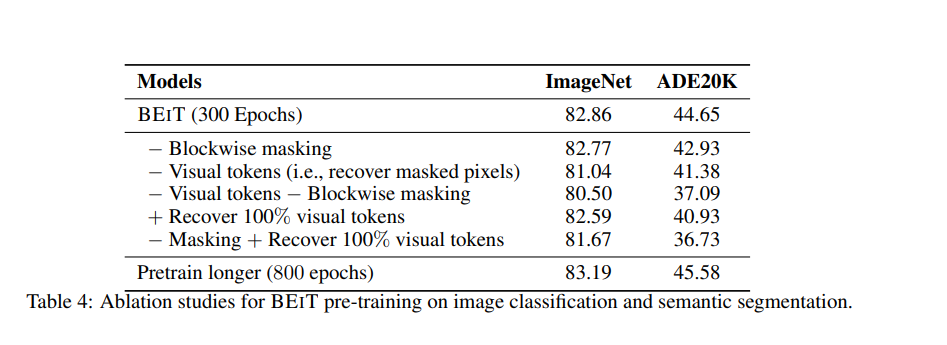
classification뿐만 아니라 segmentation에서도 우수한 것을 확인할 수 있다.
BEiT 모델 자체가 MAE랑 비슷하긴 했지만 수식적인 부분에서 VAE와 흡사하다는 생각을 했고 저자들도 이에 동의했다. tokenizing 하는 방법에 대해 이를 이미지에 적용시켜서 자세히 설명해주어 재밌는 논문이었다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 SimMIM2021논문 리뷰 0 | 2023.05.28 |
|---|---|
| 비전공생의 Segformer2021 논문 리뷰 0 | 2023.05.25 |
| 비전공생의 What do self-supervised ViT Learn?2023 논문 리뷰 0 | 2023.05.21 |
| 비전공생의 MAEMaskedAutoEncoder,2021논문리뷰 0 | 2023.05.18 |
| 비전공생의 DINO2021 논문 리뷰 2 | 2023.05.17 |



