
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 백준 알고리즘
- Entropy Minimization
- 최린컴퓨터구조
- UnderstandingDeepLearning
- CycleGAN
- shrinkmatch
- CoMatch
- Meta Pseudo Labels
- GAN
- CGAN
- BYOL
- mocov3
- 딥러닝손실함수
- conjugate pseudo label paper
- dcgan
- WGAN
- remixmatch paper
- Pseudo Label
- simclrv2
- SSL
- ConMatch
- shrinkmatch paper
- adamatch paper
- semi supervised learnin 가정
- tent paper
- dann paper
- 컴퓨터구조
- mme paper
- Pix2Pix
- cifar100-c
- Today
- Total
Hello Computer Vision
비전공생의 Segformer(2021) 논문 리뷰 본문
논문의 풀 제목은 SegFormer: Simple and Efficient design for Semantic Segmenetation with Transformer이다.
https://arxiv.org/pdf/2105.15203.pdf
이번에 아는 분들이랑 kaggle 에서 열리는 메디컬 segmentation 경연을 나가게 되어 관련 논문을 읽으려고 하는데 해당 모델이 성능이 좋다해 읽어보려고 한다.
Introduction
semantic segmentation은 image classification과 밀접한 관련이 있기 때문에 기존의 segmentation의 SOTA를 찍은 구조들은 imageNet에서 좋은 성능을 보인 구조들이었다고 합니다(VGG, ResNet). 또 다른 방법으로는 dilated convolution을 사용하는 사례도 있었다고 소개하며, SERT paper에서는 Transformer 를 활용해 이 분야에서도 충분히 효용성이 있다는 것을 증명했다고 합니다.
그러나 ViT 역시 문제점들이 존재하는데 첫번째로는 ViT는 single low resolution을 output으로 내뱉는다고 합니다. 두번째로는 많은 연산량입니다. 이러한 문제점들에 대해서 pyramid vision Transformer(PVT), Swin Transformer등이 나왔지만 이런 구조들은 encoder에 치중하여 decoder구조에 대해서는 성능의 향상이 일어나지 않았다고 합니다.
이 paper에서의 소개하는 SegFormer의 주요 contribution은
1. positional encoding이 없는 새로운 hierarchical transformer encdoer구조
2. 가벼우면서도 훌륭한 표현력을 가지는 MLP decoder
3. 구조가 가지는 efficiency, accuracy and robustness
hierarchical 한 구조를 통해 high resolution, low resolution features들을 얻을 수 있고, 이러한 정보들을 합쳐 MLP decoder는 local, global한 attention을 동시에 얻어 좋은 표현력을 얻는다고 합니다. 이러한 결과들을 통해 SOTA를 달성했습니다.

Method

구조를 시각화하면 위와 같다. 크게는 2개의 모듈로 이루어져있다. 첫번째는 hierarchical encoder, 두번째로는 MLP decoder이다. 이미지를 input으로 받는다면 이것을 4x4 patch로 분할하는데, 기존의 ViT가 16x16으로 분할한 것보다 더 작은 사이즈인데 그 이유는 dense prediction task를 수행함이라고 한다. 이미지는 hierarchical encoder를 거치면서 기존 이미지의 1/4, 1/8, 1/16, 1/32의 해당하는 representation을 얻고 이를 MLP decoder에 보내는 것을 위 구조에서 확인할 수 있다. 이렇게 모아진 feature들을 concat 후, H/4 x W/4 x N(cls) 의 크기로 MLP decoder에서 내뱉는다. 여기서 N은 우리가 segmentation할 categoriy의 개수이다.
위에서 말했던 것처럼 hierarchical features 들을 얻게되는데, 이러한 디자인은 non-overlapping하기 때문에 local continuity를 보존하기 힘들다고 한다(이 부분에 대해서 예를 한번 들어보면 32x32이미지에서 16x16, 8x8 feature map들을 얻었을 때 각 feature간의 겹치지 않는 부분들이 생길텐데 이러한 부분들에 대한 정보손실을 말하는 거 같다). 따라서 저자들은 K = patch size, S = stride, P = padding을 따로 설정하여 patch들이 overlapping 할 수 있도록 했다. 연구에서는 K=7, S=4, P=3 and K=3, S = 2, P= 1을 선택하였다
encoder에서의 주 연산량은 self attention인데 이러한 과정에서 O(N^2)의 연산량이 발생한다고 하며 이는 큰 이미지를 다루기 힘들다고 한다. 띠리서 저자들은 R이라는 reduction ratio를 따로 설정하여 연산량을 줄였다.

위와 같이 N(H x W)을 R로 나누고 동시에 C에 R을 곱해줌으로써 reshape이 가능하게 만들어주고 이를 linear layer에 맞춰 C 차원을 맞추어주는 것을 확인할 수 있다. 이러한 연산의 결과로 O(N^2) 에서 O(N^2 / R)로 연산량이 줄었다고 한다.
기존 ViT에는 positional embedding이 있지만 Segformer는 resolution이 다양하기 때문에 PE역시 이에 맞춰 달라져야하는데(interpolated) 이는 accuracy 가 낮아졌다고 한다. 이를 대처하기 위해 CVPT에서는 PE 대신 3x3 CNN을 사용하였다고 한다. 그리고 저자들은 PE가 semantic segmentation에 딱히 필요없다고 한다.

이를 수식화하면 위와 같은데, 이를 Mix FFN(feed foward network)라고 한다. 추가로 여기서 cnn은 depth wise convolution을 사용해 연산량을 효과적으로 다루었다.
decoder는 유일하게 MLP layer로만 준비되어있다. 이렇게 간단한 decoder의 원인은 larger effective receptive field 라고 한다(아마 SegFormer구조에서는 hierarchical 하게 feature들을 뽑아내고 이에 크고 작은 receptive field가 있다. 라고 이해하였다). decoder의 과정을 수식화 하면 다음과 같다.
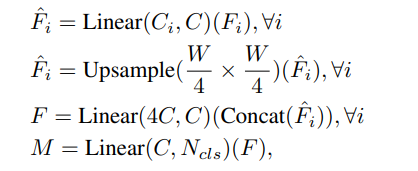
다양한 크기를 가진 multi level features(F)들을 한 채널로 unify시킨 후, 모든 feature에 대해서 원본 이미지의 1/4만큼 upsample을 시킨 후, concat 시킨다. 그리고 linear layer를 통해 C로 채널을 맞춰주고 마지막 layer에서는 N개의 채널을 뽑아내는 layer를 통과시킨다.

semantic segmentation에서는 large receptive field를 유지하는 것이 주요한 이슈라고 한다. 이에 따라 저자들은 본인들의 map을 시각화하였는데 위 이미지가 해당된다. DeepLabV3의 맵을 보았을 때, stage 4 의 map이 깊은데도 꽤 작은 것을 확인할 수 있지만, SegFormer의 encoder는 local, non local attention map을 효과적으로 capture했다고 한다. 위에서 설명했던 방법들을 똑같이 고정시키고 backbone만 CNN으로 설정하였을 때는 성능이 잘 나오지 않는데 그 이유에 대해 저자들은 overall receptive field가 제한되었기 때문이라고 한다.
Experiments
mmsegmentation을 base로 훈련을 했다고 하며 데이터 증강은 random cropping, horizontal flipping을 사용했다고 한다. optimizer는 AdamW, batch size는 16을 사용했다. 그리고 간편성을 위해 auxiliary losses, class balance loss를 사용하지 않았다고한다. 지표는 Mean IoU를 사용했다고 한다.
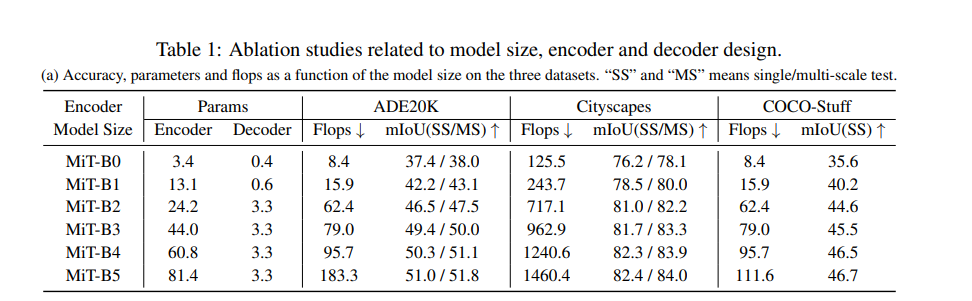
위 표에 따르면 encoder의 모델크기가 증가할 수록 성능이 계속 증가하는 것을 확인할 수 있다.

decoder의 채널인 C의 값도 실험해보았는데 768까지는 성능이 올라갔지만 그 이후로는 미비했다고 한다.

PE, mix FFN을 사용한 것도 비교해보았을 때 PE보다 FFN의 성능이 더 좋은 것을 확인할 수 있다.

각 block에서 쓰인 하이퍼 파라미터이다.
이런 비슷한 구조를 Swin Transformer에서 보았는데 더 자세히 설명하고 쓰여있어 이해하기 쉬웠다. 그리고 mmsegmentation에 대해서 한번 알아볼 계획이다.
Reference
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Medical Image Segmentation Using deep learning: Survey(2021) 논문 리뷰 (2) | 2023.06.06 |
|---|---|
| 비전공생의 SimMIM(2021)논문 리뷰 (0) | 2023.05.28 |
| 비전공생의 BEiT(2021) 논문 리뷰 (0) | 2023.05.24 |
| 비전공생의 What do self-supervised ViT Learn?(2023) 논문 리뷰 (0) | 2023.05.21 |
| 비전공생의 MAE(Masked AutoEncoder, 2021)논문리뷰 (0) | 2023.05.18 |



