
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- UnderstandingDeepLearning
- tent paper
- BYOL
- simclrv2
- adamatch paper
- SSL
- mocov3
- Pseudo Label
- 백준 알고리즘
- CGAN
- 딥러닝손실함수
- Pix2Pix
- mme paper
- 컴퓨터구조
- GAN
- ConMatch
- CoMatch
- dann paper
- conjugate pseudo label paper
- 최린컴퓨터구조
- WGAN
- remixmatch paper
- semi supervised learnin 가정
- Meta Pseudo Labels
- CycleGAN
- shrinkmatch paper
- cifar100-c
- dcgan
- shrinkmatch
- Entropy Minimization
- Today
- Total
Hello Computer Vision
비전공생의 SimMIM(2021)논문 리뷰 본문
논문의 풀 제목은 SimMIM: a Simple Framework for Masked Image Modeling이다. 기존 MAE와 비슷한 시기에 나온 논문 같고 비슷한 방식으로 SOTA를 이루어서 한번 읽어보려고 한다.
https://arxiv.org/pdf/2111.09886.pdf
Introduction
Masked signal modeling 방법은 input에 대해 일정 부분을 masking하고 이를 예측하는 작업이다. 이는 NLP에서 큰 성공을 거두고 여러 분야에 응용되지만 비전 분야에서는 그렇지 못했다고 하는데 저자들은 NLP와 CV의 3가지 차이점으로 보았다.
1. 첫번째는 locality이다. 각 픽셀들은 옆 픽셀들과 이웃해있고 연관성이 높기 때문에 semantic reasoning을 하는 것이 아닌 단순히 copy하는 경우가 생긴다.
2. visual signal이 raw, low-level이다. 여기서 low level이라는 것은 큰 정보를 가지고 있지 않다 라고 이해하였다(당연히 256x256되는 픽셀에서 구석에 있는 1개의 픽셀은 큰 정보를 가지고 있지 않다). 그러나 text token은 high level이다. 여기서 저자들은 high level task에 적용되는 것이 low level에도 적용되는지에 의문을 가진다.
3. visual signal은 연속적이지만 text는 discrete하다. 이 논문이 나올 때까지 classification based masked language modeling이 어떻게 continuous visual signal에 적용되는지 알려지지 않았다고 한다.
이에 저자들은 기존에 제안되었던 MIM의 복잡한 디자인(tokenization vis VAE, clustering etc..) 대신 아주 간단한 프레임워크를 제안한다고 한다.
1. image patches들에 대해 random masking을 한다. 기존 BEiT에서는 block masking을 했다면 여기서는 random으로 masking을 해준다. 여기서 patch size를 크게한다면(ex.32) masking ratio는 10~70%까지 다양하지만 만약 작게한다면(ex.8) 80%이상으로 크게 해주어야 한다고 한다. 이에 대한 masking ration는 domain마다 다르다고 말한다.
2. raw pixel regression task가 적용된다. 간단한 작업이지만 tokenization, clustering 등과 비교했을 때 성능이 떨어지지 않는다고 한다.
3. 가벼운 prediction head를 사용한다. 가벼우니 pre-training에서 아주 빠른 속도를 가져온다고 한다.

이러한 부분들을 통해 ImageNet1K- 83.3% top-1 fine-tuning accuracy를 얻어 SOTA를 달성했다고 한다.
Approach
SimMIM에서는 4가지 주요 요소가 있다.
1. Masking strategy

다양한 masking하는 방법이 있지만 저자들은 32x32 random masking하는 방법을 택했다고 한다.
2. Encoder architecture
simMIM 에서의 encoder는 masked image에 대해서 latent feature representation을 추출한다. 여기서는 vanila ViT와 Swin Transformer를 사용한다.
3. prediction head
위에서 말한 것처럼 매우 가볍고 2 layer MLP로 이루어져있다.
4. prediction targets
저자들은 raw pixels들에 대해서 l1 norm을 사용한다.
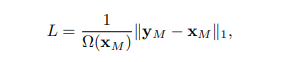
Experiments
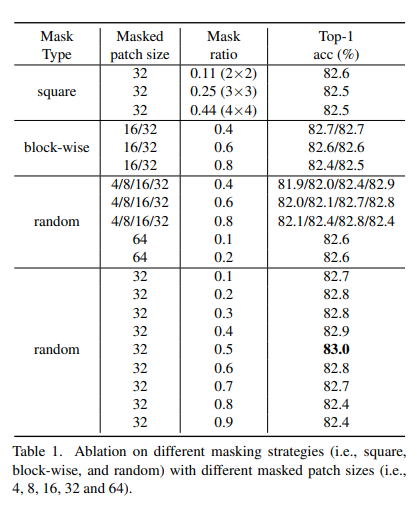
masking strategy에 대한 성능은 위 표와 같다. random, patch size를 32, masking ratio: 0.5로 했을 때 가장 좋은 것을 알 수 있다. 추가로 옵티마이저는 AdamW를 사용했으며 batch size는 2048이다.
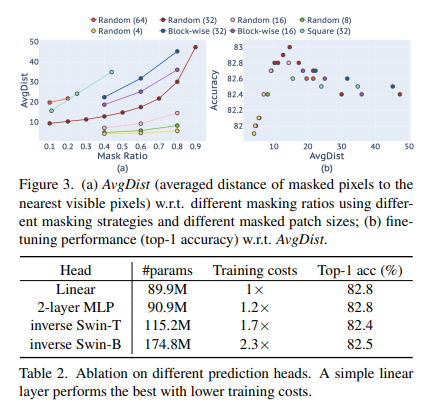
추가로 prediction head에 대해서도 실험한 결과 가벼운 Linear MLP를 썼을 때 가볍고 성능도 더 잘나오는 것을 확인할 수있다.
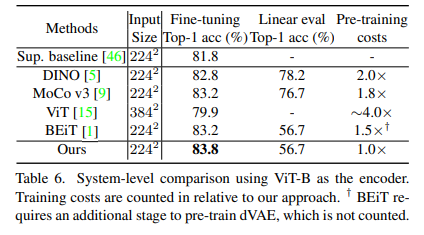
다른 SSL방법들을 비교했을 때 fine tuning accuracy가 가장 높은 것을 확인할 수 있다. 또한 여기서 backbone은 Swin-B모델을 backbone으로 삼았다.

추가적으로 masked 된 image에 대하여 reconstruction, prediction에 대하여 비교를 해보았는데 각 row에서 3번째, 4번째 이미지를 보면 된다. 4번째 reconstruction하는 것이 더 잘 복원했지만 fine tuning과정에서 더 유용한 결과를 내지 못했다고 한다.
재밌게 읽은 논문이었고 BEiT보다 훨씬 더 쉽고 간단한 방법으로 되어있어서 읽기 쉬웠다. 한번 코드를 볼 예정이다. 다음 논문은 아마 DeiT를 볼 예정이다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Adversarial Learning for Semi supervised Semantic Segmentation(2018)논문 리뷰 (0) | 2023.06.08 |
|---|---|
| 비전공생의 Medical Image Segmentation Using deep learning: Survey(2021) 논문 리뷰 (2) | 2023.06.06 |
| 비전공생의 Segformer(2021) 논문 리뷰 (0) | 2023.05.25 |
| 비전공생의 BEiT(2021) 논문 리뷰 (0) | 2023.05.24 |
| 비전공생의 What do self-supervised ViT Learn?(2023) 논문 리뷰 (0) | 2023.05.21 |



