
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- shrinkmatch
- adamatch paper
- remixmatch paper
- 백준 알고리즘
- mocov3
- tent paper
- 최린컴퓨터구조
- conjugate pseudo label paper
- cifar100-c
- shrinkmatch paper
- simclrv2
- WGAN
- dcgan
- Entropy Minimization
- CoMatch
- dann paper
- CGAN
- Meta Pseudo Labels
- SSL
- 딥러닝손실함수
- CycleGAN
- mme paper
- UnderstandingDeepLearning
- GAN
- 컴퓨터구조
- BYOL
- semi supervised learnin 가정
- Pix2Pix
- Pseudo Label
- ConMatch
- Today
- Total
Hello Data
비전공생의 CSI(Novelty detection, 2020) 논문 리뷰 본문
https://arxiv.org/pdf/2007.08176.pdf
논문의 풀 제목은 CSI: Novelty detection via Contrastive Learning on Distribtuonally shifted instances이다.
Introduction
(해당 논문에서는 OOD detection과 novelty detection이란 용어를 같은 용어로 보고 사용하였다)
일반적으로 OOD detection문제에서 training sample들에 한해 접근한 후 OOD 데이터들을 분리하려고 했다.그러나 OOD space는 굉장히 크다.그러므로 specific OOD 데이터로 샘플링을 하는 것은 detector로 하여금 bias가 생길 수 있다고 한다주로 OOD task에서의 관심은 1. modeling the representation to better encode normality 2. defining a new detection score 였다고 한다.
특히 최근의 SSL에서 학습된 inductive bias는 OOD detection에서 도움이 된다고 한다. Contrastive Learning은 sample들로 하여금 밀고 당기기 때문에 instance discrimination을 한다. 그래서 이러한 representation learning이 CV에서 큰 성공을 거두었기 때문에 저자는 이러한 representation의 힘을 OOD detection에서도 활용해보려고 한다. 여기서 몇가지 질문들에 답을 하기 위해 조사했다고 한다.
1. OOD detection을 통해 어떻게 discriminative representation을 배울지?
2. representation을 활용하여 score function을 어떻게 정의할지?
기본적으로 OOD에서 사용되는 representation learning과 기존의 representation learning은 기존 task에서는 ID데이터만 활용하기 때문이다. 여기서 저자는 이미 Contrastive Learning이 효율적이지만 추가적으로 distribution shifting을 통해서 더 향상시켰다고 한다. 기존의 Contrastive Learning의 loss는 다음과 같다.

여기서 T는 T1, T2로 된 증강이다.
CSI: Contrastive shifted instances
OOD detection의 목적이라 하면 데이터 x로부터 학습한 모델이 데이터 x'가 ID에서 왔는지 OOD에서 왔는지 구분하는 것이다. 많은 OOD detection방법에서는 score function이 높으면 input데이터가 ID 데이터로부터 왔다고 정의한다.
Contrastive learning은 인코더 f로 하여금 비슷한 sample과 다른 sample사이를 구분하는 중요한 정보를 추출하는 것이다. 여기서 contrastive learning방식은 SimCLR 방식을 사용한다.여기서 저자의 주요 finding이라 하면은 증강이 OOD detection에서 중요하다는 것이다. 여기서 이러한 증강 모음을 S라고 하는데 이것을 distribution shifting transformation이라고 한다. S집합은 K개의 다른 방식이 있다. 이를 표기하면 {S0, S1, S2, .. SK). SimCLR방식과 다른 점이라고 한다면 증강된 이미지를 positive sample로 봤다면 여기서는 S안에서의 증강이 사용됐다면 negative sample로 보는 것이 특이하다.
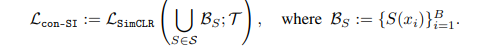
이를 표기로 나타내면 위와 같은데, original image에서 S 집합에서의 증강을 적용하면 OOD데이터라고 하는 것이다. 비록 이러한 방식이 classification 에서는 큰 성능을 내지는 못하지만 OOD detection에서는 좋은 성능을 낸다고 한다. 추가로 제시한 task로는 input x가 들어갔을 때 증강을 맞추는 것이었는데 이것은 encoder f로 하여금 각각의 변환된 객체들을 구분하는 것을 배우는 것이라고 말한다.

해당 loss term은 classification을 위해 사용되는 loss term이다.저자는 여기서 변환된 이미지를 OOD지만 semantically meaningful samples라고 한다. 표현으로는 nearby 하지만 too nearby는 아니라고 표현한다. 그리고 OOD score또한 정의하는데, 높으면 ood이고 낮으면 ID라고 할 수 있다.
그리고 labeled 데이터에 대해서는 x,y 쌍을 이용해 supervised contrastive learning을 활용한다.
Result




