
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- mme paper
- UnderstandingDeepLearning
- 백준 알고리즘
- cifar100-c
- adamatch paper
- CycleGAN
- mocov3
- 컴퓨터구조
- 최린컴퓨터구조
- dcgan
- 딥러닝손실함수
- CGAN
- shrinkmatch paper
- Pseudo Label
- dann paper
- remixmatch paper
- Entropy Minimization
- WGAN
- shrinkmatch
- simclrv2
- Pix2Pix
- CoMatch
- conjugate pseudo label paper
- semi supervised learnin 가정
- ConMatch
- tent paper
- SSL
- Meta Pseudo Labels
- GAN
- BYOL
- Today
- Total
Hello Computer Vision
비전공생의 Training Confidence-Calibrated Classifiers for Detection OOD samples(2018) 논문 리뷰 본문
비전공생의 Training Confidence-Calibrated Classifiers for Detection OOD samples(2018) 논문 리뷰
지웅쓰 2023. 9. 10. 18:06논문: https://arxiv.org/pdf/1711.09325.pdf
Introduction
딥러닝 모델이 좋아질수록 해당 모델들의 uncertainty를 측정하는 것도 어려워졌을 뿐더러 over confidence issue가 커졌다고 한다. 이 over confidence issue는 test sample이 OOD인지 아닌지 검출하는데 매우 중요하다.
기존 방법의 confidence score를 측정하는 방법은 (e.g. MSP) threshold를 사용하여 해당 값을 넘으면 1(normal) 넘지 못하면 0(anomaly)라고 분류하였다. 이러한 추론 방식이 매우 간단하지만 이러한 방식은 분류기의 성능에 매우 민감하다고 한다. 이상적으로는 분류기가 모든 ID 데이터와 OOD데이터를 훈련해서 분류하는 것이다. 앙상블 분류기를 사용할 수도 있지만 이는 비싸다고 한다. 따라서 이러한 문제점들은 간단하고 좋은 분류기를 생성하도록 하는 계기가 되었다고 한다. 분류기의 정확도를 잃으면서도 OOD 데이터를 탐지하는데 좋은 방법을 만들었다고 한다. 새로운 손실함수를 추가하는데 confidence loss이고 이는 KL divergence를 사용한다. OOD 데이터로 하여금 uniform분포가 되도록 하는 것이다. 그러나 이러한 방식은 OOD 데이터를 필요로 하는데 이는 굉장히 어렵다고 한다. 왜냐하면 OOD에 대한 space는 커버하기에 굉장히 크기 때문이다. 이를 대처하기 위해 GAN을 사용한다고 한다.
Training confident neural classifiers
새로운 loss term이 추가된 손실함수는 다음과 같다.

여기서 U는 uniform 분포를 말한다. KL divergence를 추가하는 것은 분류 성능을 떨어뜨릴 수 있다고 하는데 딥러닝에서는 예외이며, OOD데이터는 ID데이터와 잘 분리된다고 한다.

위 이미지를 본다면 OOD 데이터가 ID데이터와 근접해있을수록 decision boundary가 촘촘함을 알 수 있다. 따라서 저자는 여기서 GAN을 사용하여 이를 도와주려고 한다.
GAN의 프레임워크에는 2가지 요소로 이루어져있다. 생성기, 판별기. 생성기는 latent variable z에 대하여 mapping 을 하고 G(z) output을 뽑아낸다. 그리고 판별기는 G(z)가 target distribution에서 왔는지 [0, 1]로 판별하는 것이다.
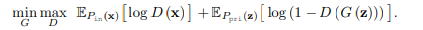
이렇게 해서 생성기는 P_in 의 분포와 비슷하게 띄게된다. 그러나 우리는 기존의 GAN과 다르게 P_in의 분포를 따르는 것이 아니라 효과적인 P_out의 분포를 생성하도록 만들어야 한다. 따라서 GAN loss에서 수정하여 새로운 loss를 제시한다.

첫번째 (a) term 을 보자면, 기존의 위에서 보여준 OOD 데이터에 대하여 Uniform분포로 만드는 것이 아니라 생성기에서 나온 분포를 uniform 분포로 만드는 것을 알 수 있다. 이로 인해 생성기는 low density sample을 생성하게 된다. (b)를 보자면 기존의 GAN loss와 같은 것을 알 수 있는데 우리는 ID데이터 분포와 비슷한 OOD 데이터 분포를 학습하고 싶다. 첫번째 (a) 에서 생성기가 어떤 데이터를 생성하든 0으로 만든다. 그러나 만약 생성한 데이터가 decision boundary 에서 멀리 떨어질 경우 손실함수가 올라가므로 decision boundary 근처의 데이터를 생성하게된다.
조금 더 설명해보자면 생성자는 D(G(z))를 최대한 1에 가깝게 만드는 것이다. 해당 목표는 -log(D(G(z))를 최소화하는 것과 같다. 만약 생성자가 형편없는 sample만 만들게 된다면 -log(D(G(z))값은 0으로 수렴하므로 손실값이 늘어날 것이다. 따라서 생성자는 더 나은 모델을 만들도록 노력해야 한다.
총 손실함수는 다음과 같다.


MSP와 비교했을 때 더 좋은 것을 알 수 있다.

위는 해당 논문의 알고리즘이다.
'Out of Distribution' 카테고리의 다른 글
| 비전공생의 A simple Unified Framework for detecting Out-of-Distribution samples and Adversarial Attacks(2020)논문리뷰 (0) | 2023.09.28 |
|---|---|
| 비전공생의 ODIN(2018) 논문리뷰 (1) | 2023.09.27 |
| 비전공생의 Learning Confidence for OOD detection in Neural Networks 논문리뷰 (0) | 2023.09.27 |
| 비전공생의 CSI(Novelty detection, 2020) 논문 리뷰 (0) | 2023.09.12 |
| 비전공생의 Deep semi supervised Anomaly detection(2020) 논문 리뷰 (0) | 2023.09.10 |



