
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- WGAN
- 백준 알고리즘
- CGAN
- 최린컴퓨터구조
- cifar100-c
- SSL
- Entropy Minimization
- CycleGAN
- UnderstandingDeepLearning
- CoMatch
- mocov3
- remixmatch paper
- simclrv2
- tent paper
- ConMatch
- semi supervised learnin 가정
- conjugate pseudo label paper
- shrinkmatch paper
- Pix2Pix
- shrinkmatch
- dcgan
- BYOL
- Meta Pseudo Labels
- GAN
- 딥러닝손실함수
- mme paper
- 컴퓨터구조
- adamatch paper
- Pseudo Label
- dann paper
- Today
- Total
Hello Data
비전공생의 Deep semi supervised Anomaly detection(2020) 논문 리뷰 본문
논문: https://arxiv.org/pdf/1906.02694.pdf
Introduction

해당 이미지의 decision boundary를 보면 알 수 있듯이 semi supervised방법을 썼을 때 조금 더 나은 boundary를 보여줌을 알 수 있다. 제목에서 알 수 있듯이 여기서는 one class classification을 수행하는 것이다. 즉 모델로 하여금 normal class에 대하여 학습시키는 것이다. 그리고 기존의 deep 한 구조를 가진 semi supervised 방법을 사용한 것도 잇었으나 domain specific 했다고 한다.
Deep semi supervised Anomaly detection
여기서는 먼저 SVDD(Support Vector Data Description)에 대하여 설명한다.

이에 대한 건 아래 그림을 보면 편하다. 데이터 중심을 c라고 했을 때 정상데이터를 이루고 있는 원을 타이트하게 하는게 목적인 것이다. 이러한 결과로 normal data는 구 중심쪽으로 위치하게 되고 이상치는 바깥쪽으로 위치하게 된다. 두번째 loss term 은 L2 regularizer를 적용한 것이다.

이를 훈련하기 전에 auto encoder를 통해 수렴할 때까지 pre-train을 한다. c는 우리가 최적화해야하는데 하이퍼파라미터이고 input x에 대하여 score를 계산할 수 있다.

SVDD는 기하학적으로 추정을 줄일 뿐만 아니라 확률적 관점에서 entropy minimization을 했다고 볼 수 있다.
n개의 unlabeled 데이터가 있고, m 개의 labeled 데이터가 있을 때 (y는 -1, 1. 1은 normal , -1은 anomaly) 손실함수는 다음과 같이 나타낸다.
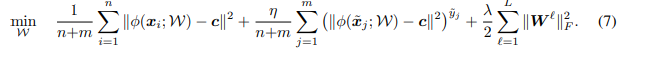
unlabeled 데이터에 대해서는 그대로 SVDD의 loss term을 그대로 사용했다. labeled 데이터에 대해서는 새로운 하이퍼파라미터를 추가하는데 ($\eta $)이는 label, unlabel loss term 에 대하여 balance를 control 한다고 한다. 해당 값이 1보다 높을 경우 labeled 데이터를 강조하는 것이고 1보다 작을 경우 unlabeled 데이터를 강조한다고볼 수 있다.
labeled 데이터의 normal데이터의 경우 quadratic loss를 부과해 center c와 가깝게 만든다. labeled anomaly데이터에 대해서는 반대로 center로부터 더 멀어지도록 훈련을 한다. 여기서 사용된 가정으로는 anomaly는 집중되어 모일필요가 없다는 것이다.
Reuslt
결과는 다음과 같다.




