
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- CGAN
- conjugate pseudo label paper
- Pix2Pix
- Pseudo Label
- 딥러닝손실함수
- WGAN
- BYOL
- cifar100-c
- CoMatch
- SSL
- dcgan
- mocov3
- Entropy Minimization
- GAN
- 백준 알고리즘
- UnderstandingDeepLearning
- 컴퓨터구조
- Meta Pseudo Labels
- CycleGAN
- shrinkmatch
- shrinkmatch paper
- semi supervised learnin 가정
- 최린컴퓨터구조
- tent paper
- ConMatch
- dann paper
- adamatch paper
- mme paper
- remixmatch paper
- simclrv2
- Today
- Total
Hello Computer Vision
비전공생의 SimCLR-V2(2020) 논문리뷰 본문
논문의 제목은 Big Self-supervised models are Strong Semi-supervised learners 이다. SimCLR 저자가 낸 후속 논문으로 SimCLR에서 몇가지 변화를 통해 성능을 높였다.
https://arxiv.org/pdf/2006.10029.pdf
Introduction
우선 제목이 일반 SSL 논문 같지 않다. 기본적으로 SSL 성능을 올리는 방법을 제목으로 올릴텐데 self supervised 모델이 semi supervised 모델의 도움이 된다고 제목으로 썼기 때문이다. 기존의 SSL모델을 활용하는 방법은 "task agnostic" 한 unlabeled 데이터를 활용하여 pre-train --> task specific 한 labeled 데이터를 활용하여 fine-tuning 하는 것이 일반적이라고 한다. 여기서 task agnostic은 task specific 의 반대말로 이해하면 쉬운데, task에 상관없이 훈련시킨다는 뜻으로 한마디로 일반적인 representation 을 훈련한다고 생각할 수 있다. 그러나 위에서 제시한 방법에서 저자는 큰 흐름을 추가한다. "task agnostic"한 unlabeled 데이터 활용 pre-train --> "task specific" 한 labeled 데이터 활용 fine-tuning --> "task specific" 한 unlabeled 데이터 활용, distill 이다. 여기서 distill 은 이미 훈련한 큰 모델에 대하여 작은 모델에게 knowledge distilation하는 것이다.
Method
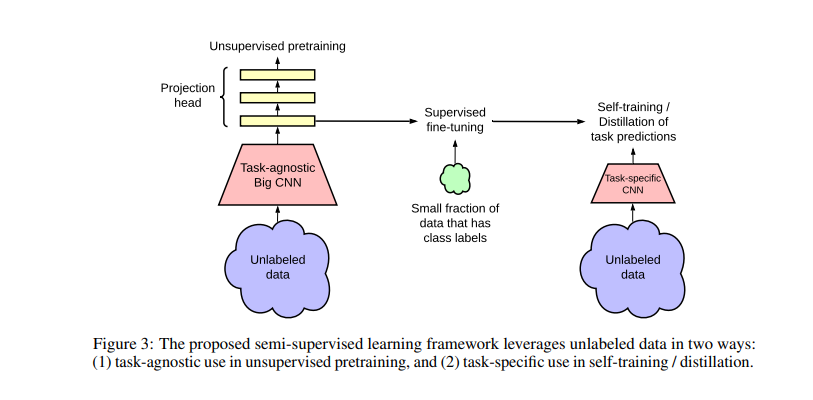
논문에서 효율적이라고 생각하는 방법의 파이프라인을 그리면 위와 같다. 설명한 것처럼 pre-train -> fine-tuning -> distill 순서를 거치는 것이다. 그리고 첫번째 단계에서 pre-train 하는 모델을 SimCLR-V2 를 사용한다. SimCLR에서 기본적으로 사용했던 것이 ResNet 50이었다면 조금 더 큰 모델인 ResNet 152를 사용한다. 저자가 논문에서 강조하는 것은 큰 SSL 모델이 더 representation을 표현하는데 중요하다고 한다. 추가적으로 encoder를 통해 받은 feature 에 대해 projection하는 네트워크가 non-linear 하다면 좋다고 한다(SimCLR에서는 g로 표현되었다). 예를 들어 SimCLR에서는 2- layer였다면 3-layer로 변경하니 성능이 더 좋았다고 한다. 아래는 SimCLR 의 pseudo code.

그리고 마지막 g encoder의 경우 fine tuning할 때 사용하지 않았지만 이번에는 fine-tuning할 때도 포함시켜 훈련했다고 한다. 그리고 MoCo에서 사용한 memory bank의 경우 SimCLR-V2 에서 큰 효과를 보지 못했다고 하는데 그 이유는 이미 배치사이즈가 커서 따로 사용할 필요가 없다고 한다(배치사이즈 4096).
Knowledge distilation
여기서 저자는 fine-tunining 된 모델에 대하여 teacher로 하고 student network를 따로 설계해 훈련시킨다고 한다. distilation loss는 다음과 같다.

위 수식은 cross entropy라고 알고 있는데, teach model의 분포값과 student model값의 차이를 최소화하는 것이 목적이다.

해당 그래프를 보면 distill된 모델이 더 우수한 것을 알 수 있다.
Result

결과를 보면 더 큰 모델이 fine tuning에서 더 좋은 결과를 내었음을 알 수 있다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 Realistic Evaluation of Deep Semi-supervised Learning algorithms(2018) 논문리뷰 (0) | 2023.11.21 |
|---|---|
| 비전공생의 MoCo v3(2021) 논문리뷰 (0) | 2023.11.14 |
| 비전공생의 Unsupervised Feature Learning via Non-Parametric Instance Discrimination(2018) 논문 리뷰 (0) | 2023.08.14 |
| 비전공생의 CoMatch(2021) 논문 리뷰 (0) | 2023.08.13 |
| 비전공생의 MixMatch(2019) 논문 리뷰 (0) | 2023.08.13 |



