
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- dann paper
- BYOL
- 딥러닝손실함수
- shrinkmatch
- tent paper
- dcgan
- 최린컴퓨터구조
- CycleGAN
- 컴퓨터구조
- UnderstandingDeepLearning
- WGAN
- conjugate pseudo label paper
- simclrv2
- Pseudo Label
- CoMatch
- adamatch paper
- Entropy Minimization
- ConMatch
- cifar100-c
- mocov3
- semi supervised learnin 가정
- SSL
- remixmatch paper
- shrinkmatch paper
- Pix2Pix
- mme paper
- 백준 알고리즘
- GAN
- Meta Pseudo Labels
- CGAN
- Today
- Total
Hello Data
비전공생의 Unsupervised Feature Learning via Non-Parametric Instance Discrimination(2018) 논문 리뷰 본문
비전공생의 Unsupervised Feature Learning via Non-Parametric Instance Discrimination(2018) 논문 리뷰
지웅쓰 2023. 8. 14. 17:42해당 논문은 Contrastive Learning 의 시초가 되는 논문이라 한번 읽어보려고 한다.
https://openaccess.thecvf.com/content_cvpr_2018/CameraReady/0801.pdf
Introduction
신경망의 마지막 단에 존재하는 linear classifier 로 분류를 하게 된다면

위와 같은 결과를 얻을 수 있는데 의도하지 않았는데도 신경망은 jaguar 와 leopard가 비슷한 이미지를 가졌기 때문에 semantic similarity 자동으로 밝혀낸다고 한다. 이를 통해 알 수 있는 점은 이미지에 따로 annotaing 하지 않더라도 이미지 그 자체의 visual data만으로도 이미지 각각의 similarity를 구분할 수 있다는 것을 의미한다. 그래서 저자는 이러한 사실에 흥미롭게 생각하면서 모든 instance 에 대하여 각각의 class라고 생각하며 이를 구분하려는 시도를 한다. 그러나 이러한 접근은 너무 많은 데이터의 클래스를 분류하는데 있어 어려움을 느끼는데 10,000개의 이미지를 10,000개의 클래스로 softmax분류하려면 굉장히 큰 어려움이 있다고 한다. 그렇기 때문에 저자는 이러한 문제점을 해결하기 위해 NCE(noise contrastive estimation)을 사용한다. NCE는 논문에서 추가 설명이 있지 않지만 개인적인 설명을 덧붙이자면 각 클래스로 분류하는 것이 아니라 positive, negative, 즉 binar classification문제로 변환하는 것을 의미한다(예를 들어 높으면 positive, 낮으면 negative).

Z는 정규화를 위한 값이다. 조금 더 살펴보면 i 이미지에 대하여 encoding한 f_i와 memory bank안에 있는 v벡터들간의 곱을 다 합한 것을 알 수 있다.
Approach

논문에서 제시하는 방법의 파이프라인은 위 이미지와 같다. CNN encoder를 통해 embedding vector는 L2 정규화를 거쳐 memory bank안에 있는 N개의 feature들에 대해서 similarity를 계산한다.
저자들이 원하는 목표는 논문 제목대로 unsupervised feature approach를 통해 instance discrimination을 하는 것이다. 그리고 이러한 목표를 달성하기 위해서는 2가지 접근방식이 있는데 parameteric classifier, Non-parameteric classifier이다.
Parameteric classifier

w는 모델에서 사용되는 weight이고 v는 faeture 이다.
Non-parametric classifier

저자가 제시하는 방법은 Non-parametric 방법이다. 이전에 제시했던 non parametric방법을 사용할 경우 모델의 특정 클래스를 학습하는 것이 아니라 representation, metric을 학습하는 것이기 때문에 새로운 class에도 성능이 좋고, weight의 gradient를 계산할 필요가 없다는 것이 장점이다. v는 L2 정규화를 통해 크기가 1인 벡터이다. t는 temperature parameter로 분포의 집중도를 컨트롤 하기 위한 하이퍼 파라미터라고 한다. 저자들이 목적을 달성하기 위해서는 다음과 같은 negative log likelihood를 최소화하 시켜야한다고 한다.
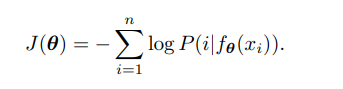
이 논문에서 추가로 활용된 기법은 memory bank이다. 모든 이미지에 대하여 feature representation을 항상 계산한다면 이는 굉장히 힘든 일이라고 한다. 그래서 memory bank V를 활용해 feature 인 v를 넣는다고 한다. memory bank에는 전 iteration의 feature들이 들어가있다.
논문에서 추가로 설명한 내용은 noise distribtuon, data sample에 대한 이야기와 몬테카를로법칙을 적용한 얘기들이 나오는데 이 부분은 정확히 이해를 못해서 패쓰..
추가로 이 논문에서 제시한 방법을 수행하는 것은 각 instance가 각 class로 분류하는 것인데 따라서 이는 변동이 심하다고 한다. 이것을 방지하기 위해 proximal regularization 기법을 사용한다.


Result

해당 instance discrimination 을 사용할 경우 backbone CNN에 적용했을 때 성능이 다른 classfication성능보다 좋은 것을 알 수 있다.
생각보다 읽는데 어려운 점이 많았다. 나중에 한번 더 읽을 예정이다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 MoCo v3(2021) 논문리뷰 (0) | 2023.11.14 |
|---|---|
| 비전공생의 SimCLR-V2(2020) 논문리뷰 (0) | 2023.08.15 |
| 비전공생의 CoMatch(2021) 논문 리뷰 (0) | 2023.08.13 |
| 비전공생의 MixMatch(2019) 논문 리뷰 (0) | 2023.08.13 |
| 비전공생의 ConMatch(2022) 논문리뷰 (0) | 2023.08.03 |



