
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- CycleGAN
- ConMatch
- 딥러닝손실함수
- conjugate pseudo label paper
- UnderstandingDeepLearning
- Pix2Pix
- 최린컴퓨터구조
- shrinkmatch paper
- SSL
- remixmatch paper
- tent paper
- dcgan
- Meta Pseudo Labels
- mme paper
- Pseudo Label
- 백준 알고리즘
- GAN
- dann paper
- WGAN
- adamatch paper
- shrinkmatch
- mocov3
- cifar100-c
- BYOL
- CoMatch
- 컴퓨터구조
- simclrv2
- Entropy Minimization
- CGAN
- semi supervised learnin 가정
- Today
- Total
Hello Data
비전공생의 CoMatch2021 논문 리뷰 본문
최근에 semi supervised learning 논문을 읽으면서 contrastive learning이 결합된 논문들을 읽어봤는데 이에 시초가 되는 논문인 CoMatch를 읽어보려고 한다.
https://arxiv.org/pdf/2011.11183.pdf
Introduction
많은 SSLsemisupervisedlearning방법들은 Pseudo label방법을 사용한다. 그런데 이 방법의 단점이라고 한다면 class distribution을 뱉는 모델의 성능에 크게 의존하는 것인데 따라서 확증편향이 일어나기 쉽다confirmationbias. 그래서 논문의 저자는 이러한 편향을 줄이기 위해 class probability와 low-dimensional embedding을 결합하는 방식을 사용한다.
Method
CoMatch의 전체적인 프레임워크는 다음과 같다.

여기서 f는 encoder, h는 classfication head, g는 non-linear projection head이다. DA는 distribution alignment로 https://arxiv.org/pdf/1911.09785.pdf 해당 논문에서 활용되었다. 이는 해당 feature를 정규화하는 방법인데 특정 class에 collapse가 일어나는 것을 방지한다고 한다이논문도한번읽어볼예정이다... 그리고 supervised loss, unsupervised loss는 각각 다음과 같다.
Aug_w는 weak augmentation, Aug_s는 strong augmentation을 나타낸다. t는 threshold값을 나타내고 argmax 값이 이 t값을 넘을 경우 loss를 생성하는 것을 알 수 있다. 그리고 전체적인 loss는 다음과 같으며 여기서 contrastive loss가 추가된 것을 알 수 있다.
처음에는 잘 이해가 가지 않았던 것이 Memory smoothed 인데 논문에서도 따로 설명해준다. 처음 본 용어라 살짝 두려웠지만 간단하게 memory bank라고 생하면 편하다. memory bank에 들어가는 feature는 labeled data, unlabeled data모두 활용되며 각 이미지의 class distribution, embedding 이 들어간다. 이는 프레임워크에서 상단을 보면 이해하기 쉽다. 그리고 이 memory bank 안에 들어가있는 feature들과 정보들을 활용해 pseudo label인 q를 생성하는 것이다. 각 이미지의 affinity는 다음과 같이 생성된다. 여기서 K는 memory bank안에 들어가있는 K개의 sample들을 말한다.
그리고 pseudo label q는 다음과 같이 생성된다.
이를 개인적인 해석을 덧붙여 한번 설명해보면 ak는 배치의 한 이미지 feature와 memory bank안에 있는 feature 간의 similarity를 계산한 것으로 알 수 있다. 그리고 생성하는 pseudo label q를 보면은 memory bank안에 있는 pseuo label과 aksimilarity를 곱한 것을 알 수 있는데 batch안에 있는 이미지와 높은 유사도를 보인 분포는 많이 반영하고 낮은 유사도를 보인 분포는 적게 반영하게 배치안의 한 이미지에 대해 memory bank를 활용하여 pseudo label을 생성한 것을 알 수 있다. 그리고 이렇게만든 q와 classification head를 통해 만든 p를 통해 Cross entropy를 계산한다. 이 부분은 프레임워크 부분을 보면 알 수 있다.
이제 contrastive loss를 한번 살펴볼 차례다. unlabeled data를 활용하여 similarity matrix를 생성한다.
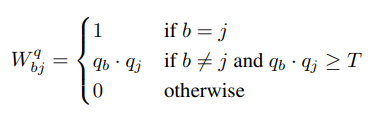
같은 이미지면은 1, 다른 이미지이고, 각 q값의 곱이 일정 임계값을 넘으면 그대로 냅두며 낮으면 0으로 두는 것을 알 수 있다. 이러한 그래프는 0은 연결이 없으며, 1은 매우높다는 것을 알 수 있다. 위 그래프는 target 그래프로 훈련에 사용된다.
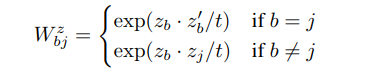
배치안에 있는 이미지들간의 similarity matrix는 위와 같이 생성한다. 그리고 위 matrix와 pseudo label target matrix와의 cross entropy를 구해 loss를 구한다.
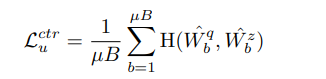
지금까지 활용한 유의미한 그래프를 사용하기 위해서는 각각의 class에 충분한 수의 데이터가 들어가야한다고 한다. 적은 class의 데이터셋이면 문제가 없지만 많은 class를 가지는 데이터셋이면 메모리에 문제가 생긴다고 한다. 따라서 저자는 MoCo, Mean teacher에서 활용된 EMA를 사용한다고 한다.
Result
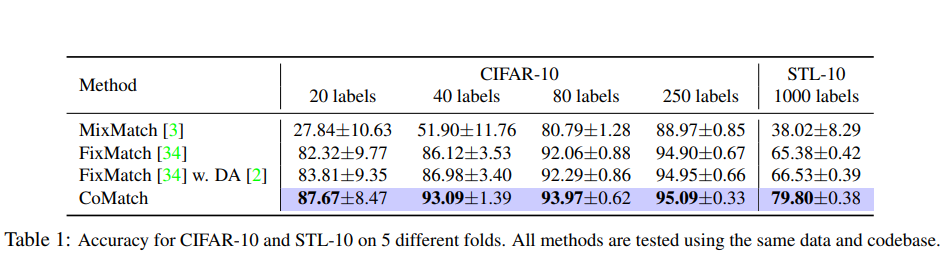
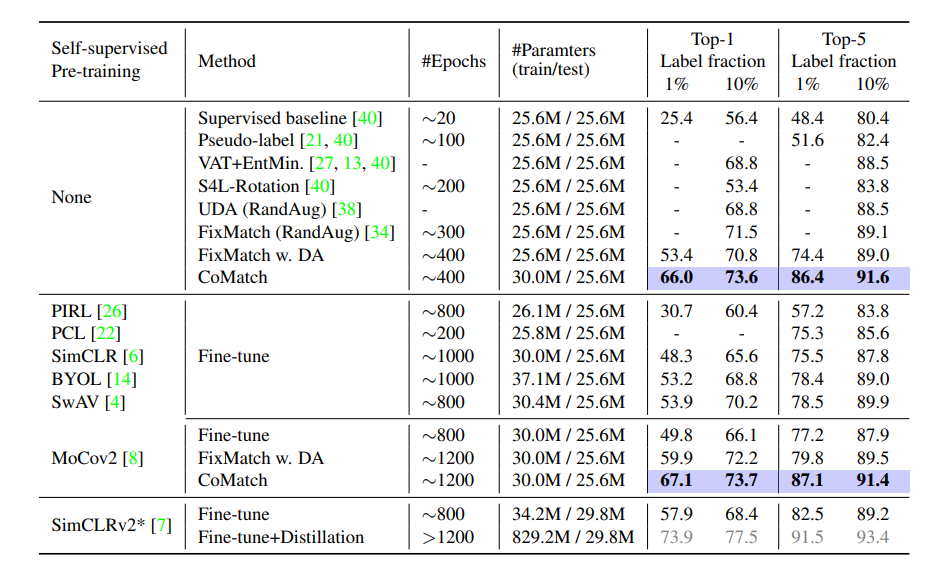
CoMatch의 정확성을 잘 보여주는 표들이다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 SimCLR-V22020 논문리뷰 0 | 2023.08.15 |
|---|---|
| 비전공생의 Unsupervised Feature Learning via Non-Parametric Instance Discrimination2018 논문 리뷰 0 | 2023.08.14 |
| 비전공생의 MixMatch2019 논문 리뷰 0 | 2023.08.13 |
| 비전공생의 ConMatch2022 논문리뷰 0 | 2023.08.03 |
| 비전공생의 CCSSL2022 논문리뷰 0 | 2023.08.02 |



