
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- cifar100-c
- 딥러닝손실함수
- remixmatch paper
- mme paper
- Meta Pseudo Labels
- tent paper
- conjugate pseudo label paper
- WGAN
- Entropy Minimization
- BYOL
- CoMatch
- shrinkmatch paper
- mocov3
- Pix2Pix
- semi supervised learnin 가정
- Pseudo Label
- 컴퓨터구조
- GAN
- CGAN
- adamatch paper
- simclrv2
- SSL
- UnderstandingDeepLearning
- dann paper
- dcgan
- shrinkmatch
- 백준 알고리즘
- CycleGAN
- ConMatch
- 최린컴퓨터구조
- Today
- Total
Hello Data
비전공생의 ConMatch(2022) 논문리뷰 본문
이번 논문은 한국인 분들이 작성한 ConMatch라는 논문이다. 지난 번에 리뷰한 SimMatch, CCSSL 논문처럼 비슷한 문제 해결을 위해 새로운 프레임워크를 제안한다.
https://arxiv.org/pdf/2208.08631.pdf
Introduction
Semi supervised learning은 데이터 문제에 대해서 많은 도움을 주는 방법이다. 하나의 이미지에 대해 strong augmentation, weak augmentation을 각각 적용한 후 모델에 넣고 분포가 consistency 하게 나와야 하는 것이 SSL에서 자주 사용하는 방식이다. 그러나 저자는 이러한 방식에 문제점을 제시하는데, 모델이 어떠한 방향으로 분포를 생성하는 것이 옳은 것인지 정의를 해주어야지, 그렇지 않고 단순히 같게 만드는 것은 모델의 정확도를 방해한다고 한다.
따라서 이 논문에서는 새로운 프레임워크인 ConMatch를 제시하는데 중요하게 여기는 점은 'confidence에 기반해 어느 방향으로 consistency regularization을 유도하는가' 저자는 non-parameteric 방법과 parameteric 방법 모두 제시한다.
Method
논문에서 사용되는 supervised loss는 FixMatch에서 사용된 loss를 사용한다. 그리고 unsupervised loss는 다음과 같다.

H는 Cross Entropy, q(r)은 weak augmentation을 통해 나온 pseudo label, A는 Strong augmentation, c(r)은 confidence of q(r)이다. 기존 방법들에 대해서는 pseudo label값이 일정 threshold 값을 넘는다면 이를 Cross Entropy에 활용하였는데 여기서는 따로 confidence 값을 계산한다.
그리고 추가적인 loss에 대해 다음과 같은 기존의 Contrastive Loss를 적용할 수 있지만 위에서 언급했던 것처럼 단순히 Strong augmentation이 적용된 두 이미지에 대해 당기기만 한다면 모델의 성능 및 latent feature space에 좋지 않다고 한다.
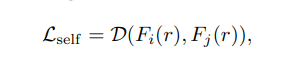
그렇기 때문에 저자들은 confidence-guided consistency regularization loss를 다음과 같이 정의한다.

unsupervised loss에서 q(r)은 weak augmentation을 적용하였지만 여기서 q_i(r), q_j(r)은 각각의 Strong augmentation을 적용한 분포이다. 길어보이지만 단순한데 하나씩 보자면 첫번째 loss term은 각각의 augmentation이 적용된 이미지를 Cross entropy 를 통해 구하고 이에 confidence를 곱해주고 두번째 loss term 또한 이와 비슷하게 반복하는 것을 알 수 있다. 그렇다면 중요한 것은 confidence를 어떻게 구하는 것인데 이를 non-parameteric, parameteric 방법으로 나눈다.
Non-Parameteric approach


위 식에서 알 수 있는 것처럼 한 이미지에 대해 Strong augmentation, weak augmentation을 적용한 후 Cross entropy를 구한 다음에 이 값이 낮다면(두 view가 비슷한 pseudo label을 갖는다면) 높은 s값을 갖게되며 이 값이 낮다면(두 view가 전혀 다른 pseudo label을 갖는다면) 낮은 s값을 갖게된다. 그리고 이러한 non parameter 방식을 적용한 ConMatch의 전체 loss는 다음과 같다.

Parameteric approach
위와 같은 non-parameteric 방식의 단점이라 한다면 confidence를 위한 모델을 따로 사용하지 않으니 순전히 각각의 이미지에 맡겨야하며, 이상치에 민감하다는 단점이 있다. 이러한 단점을 보완하기 위해 저자는 confidence 를 위한 네트워크를 정의한다.

h는 저자가 정의한 confidence estimator이며, 이에 대한 구조는 아래 그림처럼 되어있다. F(r)은 이미지에 대한 feature 이며 L(r)은 이미지에 대한 logit이다. 이를 concat 한 이후 sigmoid를 통해 confidence값을 뽑아내는 것을 알 수 있다. 다음 이미지는 ConMatch의 전체적인 프레임워크와 estimator의 구조를 알 수 있다.

그리고 이러한 estimator는 다음과 같은 loss로 업데이트 된다.

보면 pseudo label을 뽑아내는 model의 파라미터는 freezing하는 것을 알 수 있다.
또한 parameteric 방법을 사용할 때 추가적인 supervised loss를 사용하는데,
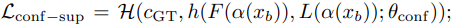
여기서 c_GT는 1 or 0 값을 가지는데, y값이 pseudo label값과 간다면 1, 다르다면 0 값을 가지게 된다. 따라서 parameteric 방법의 총 loss는 다음과 같다.

non parameteric 방법과 다르게 추가적인 loss가 들어간 것을 확인할 수 있다.
Result

parametric, non-parameteric방법 모두 성능이 다른 방법보다 좋은 것을 알 수 있다. 그리고 이 두가지 방법에 대해 한 클래스마다 데이터가 적은 데이터셋(CIFAR10)같은 경우 non-parameteric방법이 좋지 않은 성능을 보였지만 클래스마다 데이터가 많은 경우 두 방법의 차이가 줄어들었다고 한다.
해당 논문 또한 재밌게 읽었다. 다른 참고할 자료가 없어 제 개인적인 이해만을 담았으니 틀린부분이 있다면 언제든 말씀해주시면 감사하겠습니다.
'Self,Semi-supervised learning' 카테고리의 다른 글
| 비전공생의 CoMatch(2021) 논문 리뷰 (0) | 2023.08.13 |
|---|---|
| 비전공생의 MixMatch(2019) 논문 리뷰 (0) | 2023.08.13 |
| 비전공생의 CCSSL(2022) 논문리뷰 (0) | 2023.08.02 |
| 비전공생의 SimMatch(2022) 논문 리뷰 (0) | 2023.08.01 |
| 비전공생의 DASO(2021) 논문 리뷰 (0) | 2023.07.21 |



