
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- adamatch paper
- cifar100-c
- Pseudo Label
- 컴퓨터구조
- 최린컴퓨터구조
- CoMatch
- ConMatch
- BYOL
- UnderstandingDeepLearning
- SSL
- shrinkmatch paper
- tent paper
- WGAN
- Meta Pseudo Labels
- mocov3
- dcgan
- conjugate pseudo label paper
- Entropy Minimization
- semi supervised learnin 가정
- CycleGAN
- CGAN
- remixmatch paper
- Pix2Pix
- 딥러닝손실함수
- dann paper
- shrinkmatch
- mme paper
- simclrv2
- 백준 알고리즘
- GAN
- Today
- Total
Hello Data
비전공생의 Style TransferImageStyleTransferUsingConvolutionalNeuralNetworks,2016 논문 리뷰 본문
비전공생의 Style TransferImageStyleTransferUsingConvolutionalNeuralNetworks,2016 논문 리뷰
지웅쓰 2022. 12. 27. 20:40오랜만에 논문 리뷰입니다! 시험 끝나고 좀 쉬면서 선형대수를 공부하다보니 일주일이 흘렀네요..
이번 논문은 Style Transfer로 잘 알려진 논문입니다. 바로 한번 들어가보겠습니다.
Introduction
이 논문을 쓰기 전까지는 기존 texture tranferstyletransfer와같은개념는 non parameterice method였다고 합니다.
그리고 결과들이 나쁘지는 않았지만 치명적인 단점으로는 low-level image featurea만을 변경할 수 있었다합니다.
이를 한번 생각해보자면 기존 방법들은 어떤 이미지가 들어오든 똑같은 방식으로 변환하고 있었던 것입니다.
그렇기 때문에 이 논문에서는 근본적인 요구조건으로 image representation을 찾는 것이라 말합니다.

이것이 논문에서 채택한 기본적인 방법을 도식화 한 것입니다.
기존 non parameteric 방법들을 사용하기 보다는 CNN을 이용해 내가 뽑아내고 싶은 texture image에 대해 특징을 추출한 것 입니다.
위쪽 이미지고흐그림은 스타일을 추출하기 위한 이미지이고 아래의 집 그림들은 배경을 추출하기 위한 이미지입니다.
CNN 에 이미지를 인코딩하는 과정을 보여주고 있는데 Style의 경우 low level에서 추출한다면 기본적인 색감만 추출하였고
high level에서 추출한다면 대략적인 이 그림의 '진짜' 스타일을 추출하였다고 보여집니다.
Content이미지의 경우 low level에서 추출한 경우 기본 이미지와 다를 것 없지만 high level에서 추출한다면 그 원본이 많이 망가진 것을 볼 수 있습니다.
여기서 네트워크는 VGG16 기본적인 네트워크를 사용하였다고 합니다.
Content representation
그렇다면 이러한 feature들을 어떻게 뽑아내었는지 과정을 한번 살펴보겠습니다.논문의기호를따랐습니다
l: 몇번째 레이어에서 추출하였는지여기서는1 5까지있다
F: 바꾸려고 하는 이미지의 feature map
P: 추출하고 싶은 이미지의 feature map
i: 몇번째 filter인지
j: filter에서 어디에 있는지
한마디로 요약하면 추출하고 싶은 이미지와 바꾸고 싶은 이미지의 feature맵들 각각의 차를 더한 것이며 이에 대한 손실값을 최소화 해줍니다.
손실함수에 대한 gradient는 다음과 같이 정의해줍니다.
이에 대해 실험한 결과 higher layer에서는 high level content 를 capture할 수 있었고 lower layer에서는 original image를 capture할 수 있었다 합니다.
Style representation
이 논문에서는 style을 capture하는 방식을 각각의 feature간들의 correlation들을 구하였습니다.
이러한 방법은 단순히 이미지의 arrangement를 잡아내는 것이 아니라 texture를 잡아낼 수 있었다합니다.
그래서 이러한 상관관계를 추출하기 위해 gram matrix를 썼다는 것까지는 알겠는데 이러한 상관관계를 추출을 어떻게 했느냐에 대해서는 조금 어려웠는데요,
이에 대한 설명은 이곳에서 도움을 받았습니다. 별준코딩님 블로그
간략하게 한번 설명해보자면 L layer에서 style을 추출하겠다 마음을 먹었다면

각각의 channel들이 있을 것이고 각각의 channel들의 상관관계를 구하는 것인데
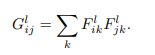
같은 layer에서의 feature들간의 내적을 구한 후
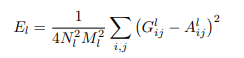
추출하고 싶은 이미지의 feature간의 차의 제곱을 구해준후 나누어줍니다
여기서 M: feature의 높이 x 너비, N : 채널의 수
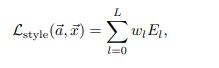
그렇게 해서 이러한 style loss함수가 나오게 됩니다. 여기서 w는 total loss에서의 L layer의 기여 정도입니다.
이러한 style 과 content loss의 과정을 그림으로나타내보면
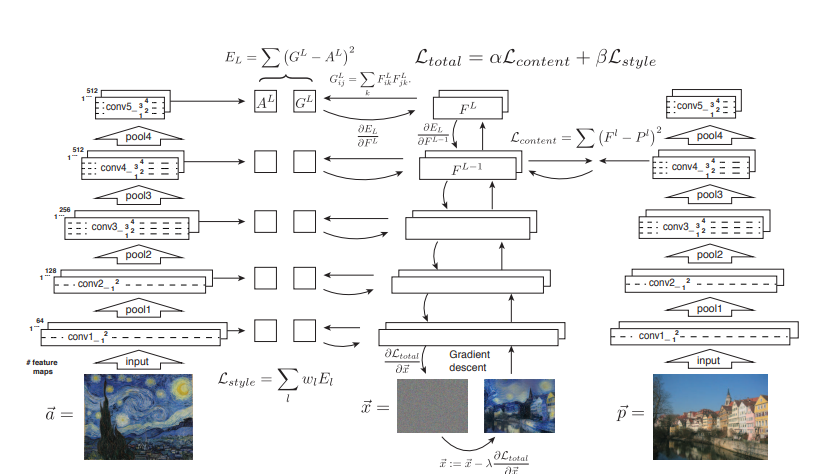
보면 알 수 있다시피 content 를 추출하는 경우 layer 1개에서 추출을 진행하지만
style loss의 경우 모든 layer에서 gram matrix를 추출함을 알 수 있습니다.
손실함수에서 나타난 알파와 베타의 경우 어느 쪽으로 비중을 두는 지에 따른 매개변수입니다.
Result


결과를 한번 살펴보자면 content이미지의 내용은 어느정도 보존하면서 style 을 입힌 것을 확인할 수 있습니다.
그리고 style과 content 은 서로 trade off관계를 가지고 있기 때문에 완벽하게 이에 대한 균형을 맞추는것을 힘들다고합니다.
마지막으로 한계점으로는 해상도와 노이즈였다고 합니다.
해상도가 높아짐에 따라 걸리는 시간이 늘어나는 문제가 발생하였다고 합니다.
또한 두가지 이미지를 이용해 한 이미지를 새롭게 만들어내는 과정에서 노이즈가 자주 개입되었다고 하네요.
gram matrix같은 요소를 글로만 보고 하니 어려운 부분이 많은 거 같습니다.
한번 코드 구현을 통해 조금 더 정확하게 알아보도록 하겠습니다.
틀린 점 지적해주시면 감사하겠습니다.



