
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Meta Pseudo Labels
- tent paper
- shrinkmatch paper
- WGAN
- adamatch paper
- simclrv2
- UnderstandingDeepLearning
- mocov3
- dann paper
- 딥러닝손실함수
- Entropy Minimization
- 최린컴퓨터구조
- 백준 알고리즘
- cifar100-c
- 컴퓨터구조
- remixmatch paper
- CycleGAN
- semi supervised learnin 가정
- Pix2Pix
- BYOL
- CGAN
- conjugate pseudo label paper
- GAN
- ConMatch
- SSL
- CoMatch
- dcgan
- shrinkmatch
- mme paper
- Pseudo Label
- Today
- Total
Hello Computer Vision
비전공생의 AdaIN(Arbitrary Transfer in Real-time with Adaptive Instance Normalization, 2017)논문 리뷰 본문
비전공생의 AdaIN(Arbitrary Transfer in Real-time with Adaptive Instance Normalization, 2017)논문 리뷰
지웅쓰 2022. 12. 29. 19:24지난번 Style Transfer 논문 리뷰에 이은 AdaIN 논문 리뷰입니다.
Style Transfer의 gram matrix개념은 사실 너무 복잡하고 어려워서 완전히 이해하기 힘들었는데
이번 논문은 빠르고 많은 수의 스타일을 임의로 전달할 수 있다는 점에서 아주 인상적입니다.
바로 시작해보겠습니다.
Introduction
기존 style transfer하는 방법들은 각각의 trade-off를 가지고 있었습니다.
속도가 빠르지만 스타일을 1개만 전달/ 속도가 느리고 여러개의 스타일을 전달
그리고 이 논문에서는 이러한 문제점들을 Instance Normalization 개념을 통해서 개선했다고 합니다.
이러한 방법은 3자리수의 속도 이상을 개선했다고 합니다.(100배)
BatchNormalization
우리가 보통 네트워크를 훈련할 때 배치정규화를 사용하게 됩니다.
배치정규화(이하 BN)는 각 배치 안에서 channel별로 평균과 표준편차를 이용하여 정규화를 수행합니다.
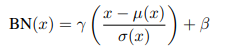

이러한 방법은 분류문제를 해결하는 모델일수록 효과가 좋다고 하며 훈련시간을 줄여준다고 합니다.
Instance Normalization
이 논문에서의 핵심 개념인 Instance Normalization(이하 IN)이 나옵니다.
BN이 배치 단위로 각 채널의 정규화를 수행하였다면 IN의 경우 개별의 채널별로 정규화를 진행합니다.



위에서 BN과 비교해본다면 더 확실하게 차이를 알 수 있습니다.
Conditional Instance Normalization
이에 응용하여 CIN 이란 개념도 나왔는데요,

스타일별로 $\gamma, \beta$ 를 학습한다면 각자 다른 스타일을 학습할 수 있지 않을까 라는 생각이었고
이 역시 32개의 각기 다른 스타일을 학습하고 적용할 수 있었다고 합니다.
Interpreting Instnace Normalization
이 논문의 핵심 개념은 IN 을 이용하는 것인데요, IN의 어떤 특징을 가지기 때문에 스타일을 효과적으로 전달할 수 있는걸까요?
기존 논문에서는 IN을 contrast normalization에 효과가 있었다고 말합니다. 여기서 contrast 란 대비란 뜻을 가지고 있고
이미지들이 서로 다른 채도, 각도를 가지게 되는데 이러한 차이를 정규화해주는데 유용하다라는 해석을 가지고 있었습니다.
그러나 논문 저자들은 이러한 의견을 실험결과로 반박합니다.

두번째 (b)실험결과에서 이미 contrast normalized된 이미지들 간의 훈련을 진행하였을 때 IN이 더 좋은 결과를 보였다고 합니다.
만약 IN이 contrast normalization에 효과적이었다면 이미 대비에 대해 정규화된 이미지들을 훈련했을 때 차이가 적어야할 것입니다.
기존에 gram matrix와 다른 연구들을 통해 feature statistics를 변경하는 것만으로도 스타일을 변경할 수 있었다는 것에 착안해
IN은 change the style을 수행하는 역할을 하고 있다고 말합니다. --> style normalization
Adaptive Instance Normalization
IN이 이미지의 statistics를 정규화할 수 있다는 것을 이제 알았다. 그렇다면 저자들은 임의의 이미지에 대한 statistics를 이용해 정규화할 수 있지 않을까? 라는 생각을 한다.
그리고 이것을 AdaIN이라 하는 것이다. 수식으로 나타내면 다음과 같다.
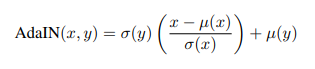
기존 정규화 방법은 $\gamma, \beta $를 학습해야 했지만 여기서는 기존 이미지에서의 statistics를 활용하는 것이므로 따로 훈련할 필요가 없다.
훈련 구조를 도식화 하면 다음과 같다.
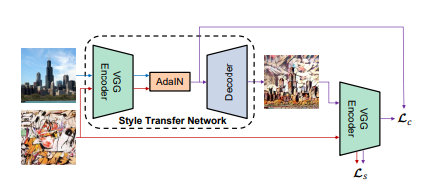
여기서 Encoder를 담당하는 VGG는 고정되어있으며 feature를 추출할뿐 따로 학습을 진행하지 않는다.
그리고 AdaIN layer를 통해 feature에 대한 statistics를 계산하며 이를 Decoder에 넣고 이미지를 생성한다.
그리고 다시 Encoder에 넣고 feature를 추출하며 이에 대해 기존 AdaIN에서 추출한 statistics와 비교하여 loss를 계산한다.
이를 수식으로 나타내면 다음과 같다. f는 Encoder이며 g는 Decoder이다.

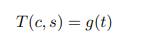
Training
총 손실은 content loss와 style loss값을 합친 값이다.

content loss의 경우 위에서 설명한 것을 수식으로 나타낸 것이며 loss는 L2 loss를 사용한다.
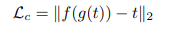
style loss의 경우 gram matrix와 원리는 비슷하며 대신 이러한 방법이 더 명확하다고 합니다.
여기서 시그마가 붙은 이유는 각 layer마다(i~L) 이에 대한 style대한 statistics를 추출하기 때문입니다.
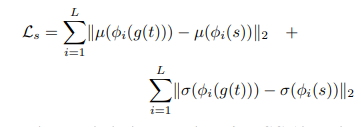
Result
AdaIN과 다른 방법들을 비교하였을 때 qualitative(변환이 잘 되었는지),quantitative(몇개의 스타일), speed문제에서 경쟁력 있었다고 합니다.

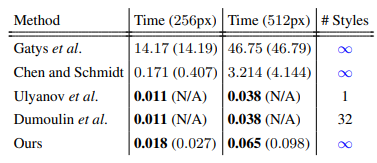
다른 방법들과 비교해본 이미지들과 이를 수치로 나타낸 것입니다.
속도 면에서 실시간으로 스타일을 변경할 수 있으며 스타일의 개수 또한 제한이 없는 것을 확인할 수 있습니다.
추가로 이미 AdaIN으로 정규화를 한 시점에서 decoder에 BN/IN을 쓰는 것을 오히려 성능이 하락했다고 합니다.

$\alpha$ 값을 변경해가면서 style, content간의 trade-off를 조절할 수 있다고 합니다.


이렇게 한 content이미지에 대해서 여러가지의 style또한 가중치를 정해서 적용할 수 있었다고 합니다.
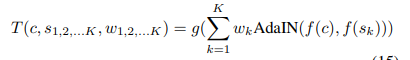

또한 이미지마다 mask를 설정해서 다른 스타일을 적용할 수 있었다고 합니다.

논문에 대한 느낀점
이해하는데 있어서 Style transfer논문 보다 훨씬 직관적이라 이해하기도 쉬웠고 성능도 좋은 거 같습니다.
다음에는 논문 구현 코드를 한번 살펴보겠습니다. 틀린 점 지적해주시면 감사하겠습니다.
참고 자료: 나동빈님 영상



