
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- GAN
- dcgan
- conjugate pseudo label paper
- mme paper
- SSL
- dann paper
- CoMatch
- tent paper
- CGAN
- semi supervised learnin 가정
- adamatch paper
- shrinkmatch
- Entropy Minimization
- BYOL
- mocov3
- Pix2Pix
- shrinkmatch paper
- Pseudo Label
- simclrv2
- WGAN
- 컴퓨터구조
- UnderstandingDeepLearning
- ConMatch
- Meta Pseudo Labels
- CycleGAN
- cifar100-c
- 최린컴퓨터구조
- 딥러닝손실함수
- 백준 알고리즘
- remixmatch paper
- Today
- Total
Hello Computer Vision
비전공생의 Attention(Neural Machine Translation By Jointly Learning to Align and translate, 2015) 본문
비전공생의 Attention(Neural Machine Translation By Jointly Learning to Align and translate, 2015)
지웅쓰 2023. 1. 3. 15:03Transformer를 공부하기 위해 Attention 관련 논문을 살펴보려고 한다.
이 논문에서는 대놓고 attention mechanism 이라고 언급하기 보다는 새로운 구조라고 말한다.
논문 처음부터 천천히 읽어보겠습니다.
Introduction
기존의 machine translation(Seq2Seq)에 단점에 대해서 언급을 합니다.
Encoder-Decoder로 이루어진 구조는 긴 문장에 대해서 대응하기 힘들고 그 길이가 길어질 수록 성능이 악화된다고 합니다.
(fixed vector length --> bottleneck 유발)
그렇기 때문에 Encoder-Decoder 학습과정에서 learn align, translate jointly 한다고 합니다.(논문의 핵심)
그리고 기존 구조 접근방식의 단점인 single fixed-length를 보완하기 위해 input을 모두 encode 하지 않는다고 합니다.
대신 sequence vector에 encode한 후 decoding하는 과정에서 기존 encoder part에서의 sequence vector 를 adaptively하게 choose한다고 합니다.(무엇에 집중할지 정하는 것이므로 attention)
조금 꼬아서 말한 거 같은데 기존 LSTM을 이용한 machine translation에서는 모든 문장에 대해 fixed vector에 정보를 담고(contextual vector)
이 벡터를 decoding하는 과정을 거쳤습니다. 그러나 이러한 context vector만을 반영하는 것이 아닌 기존 은닉cell도 참고하는 것이 내용인데요,
뒤에 조금 더 알아보기 쉽게 기호로 나오니 자세한 설명은 보류하겠습니다.
Background: Neural Machine Translation
기존 RNN Encoder-Decoder방식을 설명해줍니다.
$x = (x_{1},x_{2},x_{3},...x_{T})$ :input vector
$h_{t} = f(x_{t}, h_{t-1})$ : 은닉셀(hidden state). 그 전 은닉셀과 input 을 고려
$c = q(h_{1},h_{2},h_{3}..h_{T})$ :context vector. 모든 은닉셀 고려해서 벡터 생성. q : 비선형함수.
$p(y) = \prod_{t=1}^{T} p(y_{t}| y_{1},y_{2},y_{3}...y_{t-1},c) $ y : 출력 벡터
$p(y_{t}| y_{1},y_{2},y_{3}...y_{t-1},c) = g(y_{t-1}, s_{t}, c)$ g: 비선형 함수
출력벡터 y에 대해서는 contextual vector와 그 전의 출력벡터의 확률분포를 고려하는 것을 알 수 있습니다.
여기서 t번째 벡터의 분포에 대해서는 그 전 번역된 벡터와 decoder파트의 은닉셀, context vector를 활용하는 것을 확인할 수 있습니다.
이를 그림으로 나타내면 다음과 같습니다.

Learning to Align and Translate
$p(y_{i}| y_{1},y_{2},y_{3}...y_{i-1},x) = g(y_{i-1}, s_{i-1}, c_{i})$
$s_{i} = f(s_{i-1}, y_{i-1}, c_{i})$
기존의 방법과는 다르게 decoder파트에서의 은닉셀인 $s_{t}$에 대해 $c_{i}, y_{i-1}$의 영향을 준다고 할 수 있습니다.
기존의 $c$에 대해서는 단방향으로만 $h_{t}$의 영향을 받은 후 decoder 파트에서 이를 활용했는데요, (h : encoder에서의 은닉셀)
이 논문에서의 구조에서는 $s_{t}$ 에 대해서 전체 벡터인 $c$만을 고려하는 것이 아닌 각 encoder 파트에서의 모든 은닉셀들을 $s_{t}$를 만들 때마다 고려해 가중치를 준$c_{i}$를 고려합니다.
또한 새로운 구조에서는 $h_{t}$에 대해서 양방향으로 고려할 수 있도록 만드는데요, 수식은 다음과 같습니다.
$c_{i} = \sum_{j=1}^{T_{x}} \alpha_{ij}h_{j} $여기서 $\alpha$는 각 은닉셀의 가중치입니다. 이를 그림으로 나타내면 다음과 같습니다.

살펴보자면 각각의 출력벡터에 영향을 주는 $s_{t}$에 대해서 input vector의 은닉셀들을 양방향으로 탐색해 이에 가중치를 입히는 것을 확인할 수 있습니다.
$\alpha = \frac{exp(e_{ij})}{\sum_{j=1}^{T}exp(e_{ik})}$ 이렇게 소프트맥스 함수로 가중치를 결정합니다.
$e_{ij} = a(s_{i-1}, h_{j} )$ 디코더 i시점과 인코더 j시점에서 얼마나 유사한지 score를 계산합니다.
a의 경우 딥러닝 모델을 통해 최적의 파라미터로 결정한다고 합니다.
이 알고리즘을 조금 더 쉽게 시각화 해보자면 다음과 같습니다.
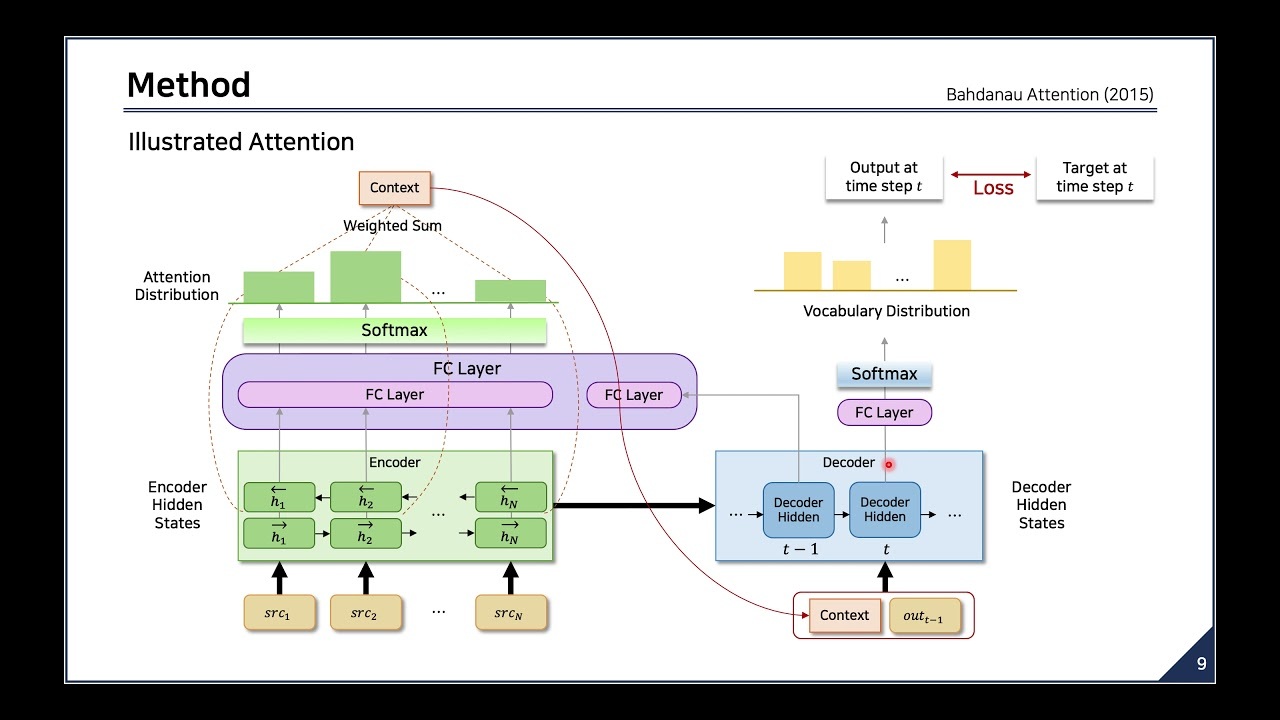
이러한 구조는 결국 디코더가 인코더 파트에서 어느 부분에 더 집중해야하는지 알려줍니다
Intuitively, this implements a mechanism of attention in the decoder.
이렇게 함으로써 모든 정보를 한 벡터에 모든 정보를 encoding하는 부담도 줄여준다고 합니다.
Results

여기서 RNNenc는 기존 모델이고 RNNsearch 는 논문에서 제시된 새로운 구조입니다.
보시다시피 문장이 길어져도 attention기법으로 인해 성능이 하락하지 않은 것을 확인할 수 있으며
기존 구조 30문장보다 새로운 구조 50문장할 때의 손실이 더 적었다고 합니다.

x,y행에는 각각 대응하는 언어들이 쓰여져있는데요, 영어와 프랑스어를 대응시킨건데 결과들이대부분 diagonal한 matrix로 만들어진 것을 볼 수 있습니다.
이러한 결과는 영어와 프랑스어가 alignment 측면에서 monotonic한 것도 있다고 합니다.
아마 그렇지 않은 경우도 있으니 양방향(bidirectional)한 hidden state를 고려한 거 같습니다.
한번 Attention에 대한 논문을 읽어보았는데요, 예전에 보았을 때보다 확실히 엄청 어렵다는 느낌을 받지는 않았습니다.
더 공부하면서 다음에는 Transformer에 대한 논문도 리뷰해보겠습니다.
틀린 점 지적해주시면 감사하겠습니다.



