
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- CycleGAN
- BYOL
- semi supervised learnin 가정
- CGAN
- shrinkmatch paper
- 최린컴퓨터구조
- CoMatch
- mocov3
- Entropy Minimization
- Meta Pseudo Labels
- dcgan
- ConMatch
- dann paper
- conjugate pseudo label paper
- shrinkmatch
- 백준 알고리즘
- simclrv2
- remixmatch paper
- Pseudo Label
- 딥러닝손실함수
- WGAN
- tent paper
- cifar100-c
- UnderstandingDeepLearning
- Pix2Pix
- SSL
- GAN
- mme paper
- 컴퓨터구조
- adamatch paper
- Today
- Total
Hello Computer Vision
비전공생의 Attention is All you Need(2017)논문 리뷰 본문
사실 Transformer 논문은 지난 번에도 본적이 있었고 그때 당시에는 이해를 했다고 넘어갔으나 Transformer에 대해 한동안 손을 놓았고 다시 보았을 때 알고리즘이 머리에 바로 떠오르지 않아 다시 한번 정리해보려고 한다.
https://arxiv.org/pdf/1706.03762.pdf
기존 RNN의 문제점
병렬화가 안된다.
문장이 길수록 메모리에 문제가 생긴다.
Transformer 구조

기존 번역 모델과 같은 Encoder - Decoder 구조를 띄고 있으며 여기서 RNN구조를 다 제외하고 Attention 기법만을 이용해 구조를 완성시켰다. 구조에 대한 설명은 Encoder, Decoder 부분을 분리시켜 설명을 한번 해보려고 한다.
그 전에 두 부분의 공통적으로 들어가는 Self-Attention 을 한번 알아보고자 한다.
Self-Attention
예를 들어 " I had a dog, it was cute " 라는 문장이 있고 이 문장에 대해 self-attention 을 수행한다고 생각해보자. embedding 차원수는 3이다.

it 이 어떤 단어와 연관성이 높은지 attention이 필요하다.

행렬 연산을 위해 key의 벡터를 transpose해주면 하나의 attention value 가 나타난다.
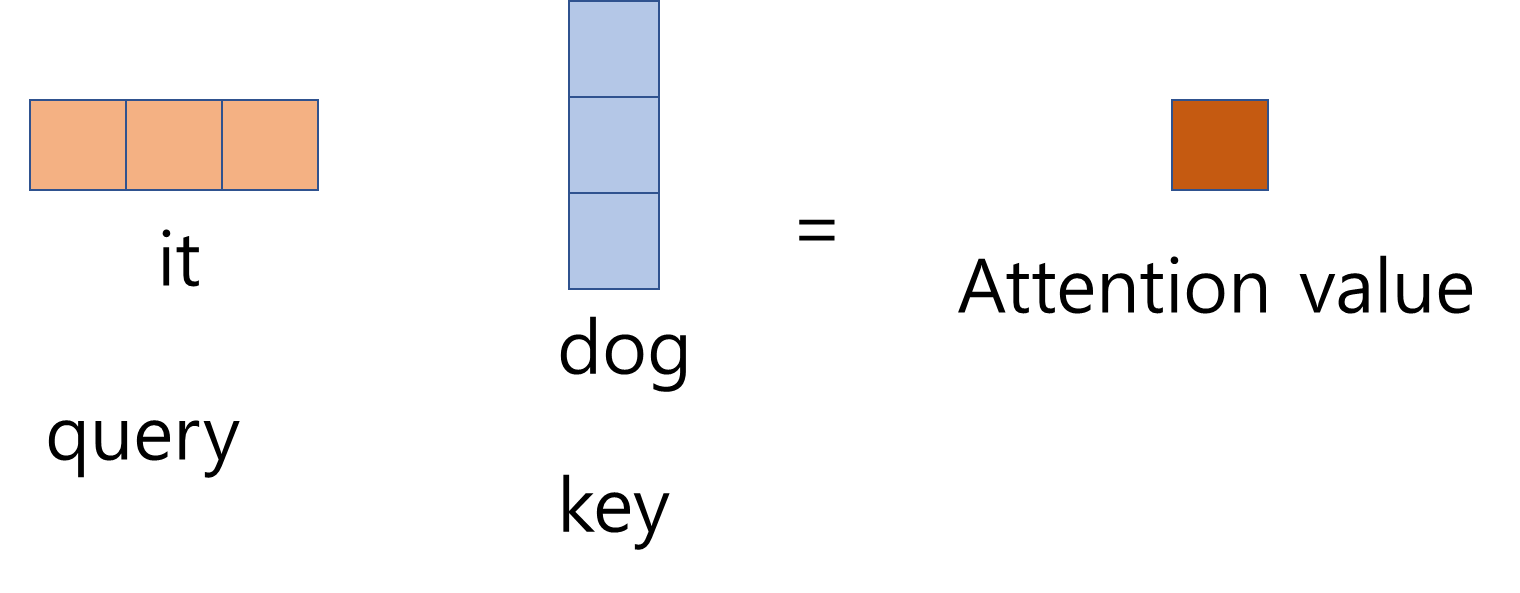
이것은 단지 it - dog에 대한 하나의 attention value 인 것이고 예시로는 총 7단어가 있으니 it을 query로 하는 7개의 attention value가 생기게 된다(1x7).

그리고 이러한 값들을 차원 수로 나눠주는 작업이 필요한데 이는 너무 높아진 값에 대해 정규화 해주는 과정이라고 할 수 있다. 그리고 이렇게 정규화된 값을 대상으로 softmax를 취해주는데, 결국 it과 어느 단어가 더 많은 연관성을 가지는지 확률로 나타낼 수 있다. 여기서 끝나는 것이 아니라 Value를 곱해주어 query의 attention을 구하게 되는데 이는 위에서 보았던 처음 it query의 크기와 같은 것을 확인할 수있다(해당 이미지에서는 attention value 와 value 가 곱하는 걸로 되어있지만 사실은 attention value에 softmax가 취해진 값이다).
'
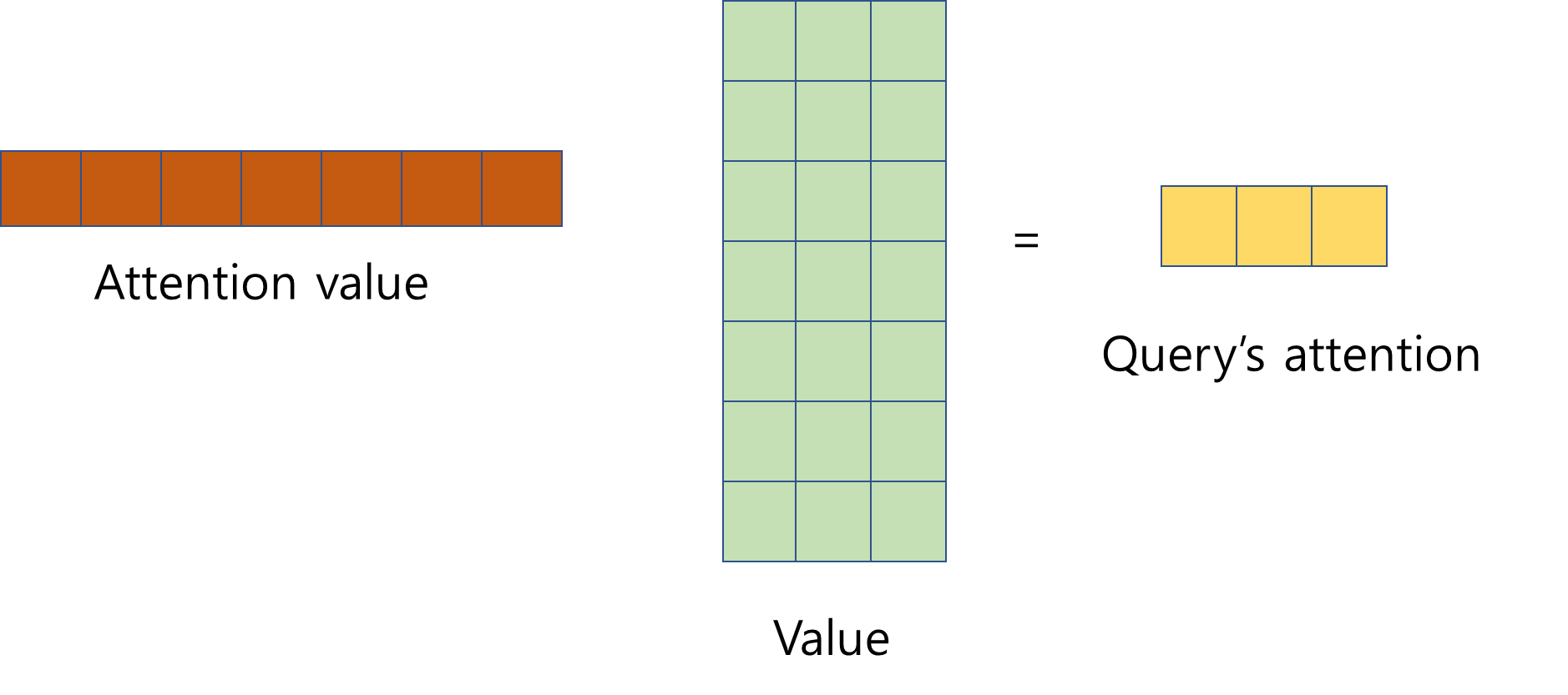
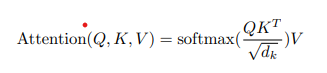
수식으로 나타내면 다음과 같으며 이러한 작업을 각 단어를 query를 하며 모두 수행되고 이는 병렬적으로 수행이 된다. 이러한 연산들을 통해 나온 결과가 기존의 벡터와 같은 것이 중요한데 왜냐하면 단순히 한번 수행하는 것이 아닌 여러의 Encoder block에서 수행되므로 Input과 output의 크기는 같아야 한다. 또한 이러한 과정을 여러번 거쳐 query와 알맞은 key와 value값을 학습하는 것이 목표인데 query, key, value값을 직접 학습 하는 것이 아닌 query weight, key weight, value weight을 학습하는 것이다. 이것에 대한 추가적인 내용은 이전에 쓴 포스팅이 있으므로 참고하면 될 것 같다.
https://keepgoingrunner.tistory.com/72
비전공생의 self-attention 코드 구현
Transformer 구조에서 이루고 있는 self-attention 코드를 구현해보려고 합니다. 자료 참고 : ratsgo님 블로그 나동빈님 유튜브위키독스 기존 RNN 구조를 제거하였지만 여전히 인코더/디코더 구조는 유지
keepgoingrunner.tistory.com
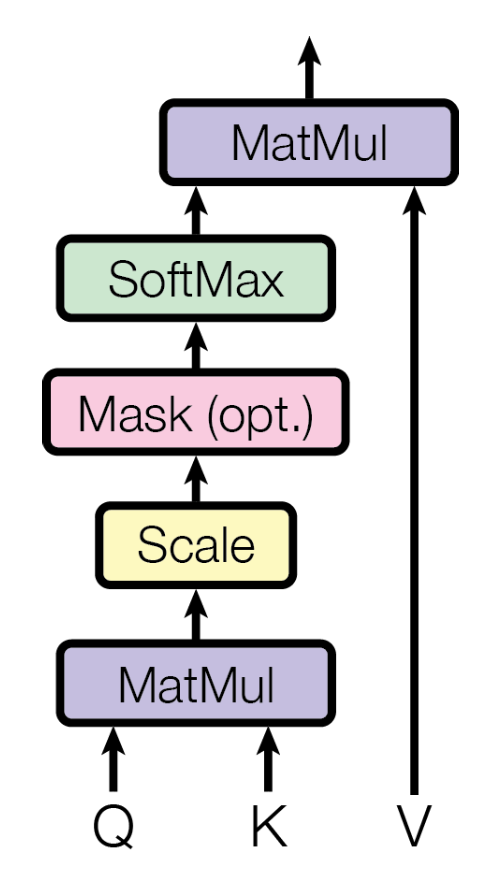
해당 논문에서의 self attention 과정은 다음과 같은데 여기서 mask가 무엇일까?
한 corpus내에서 해당 문장들은 모두 길이가 다르므로 그때마다 model에 들어가는 input의 shape이 다를 것이다. 그러나 학습 과정에서는 한문장씩 수행되는 것이 아니라 mini-batch로 여러개의 문장이 들어가는데 이 경우 각 문장의 길이가 다를 경우 batch를 만들 수 없다. 따라서 이러한 문제를 해결 위해 seq_len 을 설정하는데 mini-batch내 최대 길이 값을 설정하는 것이다. 만약 최대 길이가 10이라 한다면 위의 문장은 7개밖에 없으므로 3개는 빈 벡터가 만들어지는 것이다. 빈 값에 대해서 softmax가 수행되 연관관계를 나타내면 당연히 이상하므로 softmax를 취하기 전에 mask작업을 수행해준다.
Multi-head Attention
위에서는 Self-Attention을 설명했다면 지금 설명할 multi head attention은 여러개의 self attention이 병렬적으로 한번에 수행되는 것이다. 이렇게 하는 이유는 한개의 관점에서 생각하는 것이 아니라 여러개의 관점에서 생각해보는 것이라고 생각할 수 있다. 이를 이미지로 나타내면 다음과 같다.
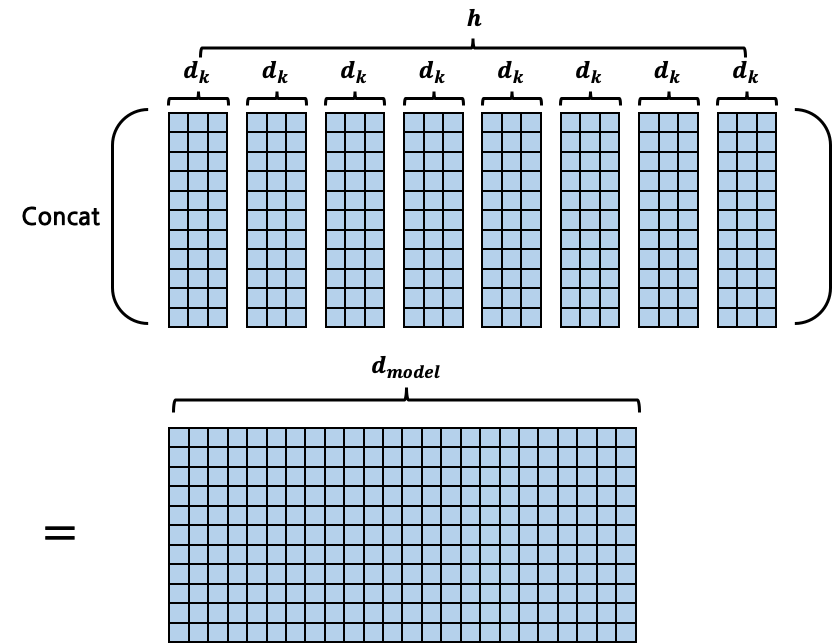
Encoder

Encoder의 구조를 단순화 해보자면 위 이미지와 같다. 영-한 번역을 한다고 했을 때 Input 은 영어 문장일 것이며 Context 는 Encoder를 통해 나온 Context vector가 될 것이다. 여기서 그림으로는 단순히 Encoder가 한개로만 되어있지만 논문에서는 6개의 인코더를 통해 나온 것이 Context Vector라고 할 수 있다. 이를 그림으로 나타내면 다음과 같다.

Input이 들어오면 embedding을 거친 후 추가적으로 Positional Encoding 을 거치는데 이는 코사인, 사인 함수를 이용한다.
각 block 내에서 self attention이 수행된 후 Layer Norm --> Feed Forward --> Layer Norm 이 수행된다. 또한 추가적으로 Residual connection 기법이 사용된다. 이렇게 6개의 Encoder Block을 거친 후 Decoder에 들어가게 된다.
Decoder
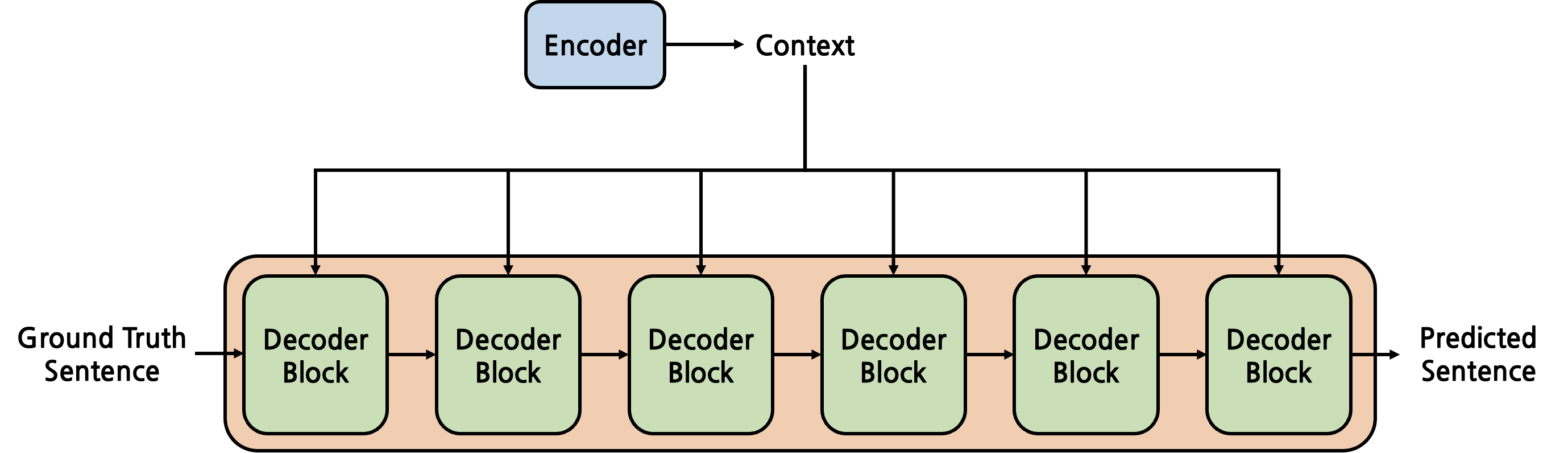
일단 Decoder 에 들어가는 input은 Encoder input에 대한 답이라고 할 수 있다(Ground truth). 그러나 한번에 모든 답을 보여주지 않는데 위에 예시로 든 "I had a dog, it was cute" 에 대해서 "나는 개를 가져었고 귀여웠었다." 라는 문장을 Decoder가 번역을 해야한다고 했을 때 Encoder의 context vector와 <s> 를 이용해, '나는' 이라는 단어를 예측하는 것이고, 다음에는 '<s>나는' 과 Encoder Context 를 활용해 '개를' 이라는 단어를 배우는 것이며 Decoder마지막 단에 위치한 softmax를 활용해 이를 학습하고 이러한 과정이 반복된다.
여기에 대한 궁금증이 '혹시 Decoder가 잘못 생성하면 어떡하지?' 였다. 예를 들어 '나는' 을 출력해야 하는데 '너는'을 학습하면 어떡하지 였다. 이에 대한 방법으로는 Teacher forcing 방법을 사용하는데, 이는 잘못된 출력을 내뿜더라도 다음 decoder input으로 정답으로 주어 잘 학습할 수 있도록 학습한다.
그리고 self attention을 거친 Decoder output 과 self attention을 거친 Encoder output과는 "Cross Attention"을 수행한다. 여기서는 영-한 번역이라고 한다면 한글로 최종 내뱉는 것이 목표이니 Deocder에서의 output이 query 가 될 것이며 Encoder의 output이 key, value가 될 것이다.
References
https://arxiv.org/pdf/1706.03762.pdf
https://cpm0722.github.io/pytorch-implementation/transformer



