
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- WGAN
- remixmatch paper
- GAN
- conjugate pseudo label paper
- CGAN
- 딥러닝손실함수
- ConMatch
- cifar100-c
- adamatch paper
- dcgan
- Entropy Minimization
- shrinkmatch paper
- mme paper
- tent paper
- SSL
- semi supervised learnin 가정
- Pseudo Label
- simclrv2
- dann paper
- CoMatch
- 컴퓨터구조
- Meta Pseudo Labels
- UnderstandingDeepLearning
- 백준 알고리즘
- CycleGAN
- BYOL
- 최린컴퓨터구조
- Pix2Pix
- shrinkmatch
- mocov3
- Today
- Total
Hello Data
비전공생의 TENT(Fully Test-Time Adaptation by entropy minimization) 논문리뷰 본문
비전공생의 TENT(Fully Test-Time Adaptation by entropy minimization) 논문리뷰
지웅쓰 2024. 2. 7. 17:02논문의 풀 제목은 글 제목에 있고 주로 TENT라고 불린다. 2021 ICLR에서 억셉된 논문이고 milestone 논문 같아 읽어보았고 코드도 함께 살펴보려고 한다
https://arxiv.org/pdf/2006.10726.pdf
Introduction
Deep neural network는 train, test data들이 same distribution이라는 setting하에 높은 성능을 보여줬다. 그러나 이러한 성능은 두 data의 분포가 다를 경우 하락을 보여주는데 이러한 것을 dataset shift라고 한다(distribution shift라고 이해해도 문제 없을 거 같다). 모델은 unexpected weather, sensor degradation등의 variation한 상황을 맞이할 가능성이 굉장히 높기 때문에 model은 다양한 data distribution에 적응할 필요가 있으며(it can be necessary to deploy a model on different data distribution) adation은 필수적이라고 할 수 있다.
저자는 Real world에 쓰이기 위해서는 Fully test-time adaption(모델이 적응하는데 source data 없이 target data 만 존재. 이 부분에 대해서는 저자가 강조하는 setting이기 때문에 나중에 자세히 말해보려고 한다)이 필수적이라고 말하는데 그 이유는 다음과 같다.
Availability: 모델은 privacy, profit 문제로 인해 source data에 대한 정보가 없을 수 있다.
Efficiency: source data가 있다하더라도 testing과정에서 이를 활용하기 쉽지 않다.
Accuracy: adaption없이는 모델은 inaccurate하다.
저자는 testing과정에서 adaption하기 위해 minimize the entropy of model prediction방법을 사용한다. 그 이유에 대해서는 entropy, error는 상관관계에 있으며 모델이 more confident 하다면 more accurate하다고 한다. 이미지에 more corruption이 들어갈수록 entropy가 있기 때문에 이러한 방법을 택했다고 말한다. 이러한 minimize entropy를 위해 논문에서는 test batch에 대해 정규화 및 transform을 가하는데 여기서 사용되는 affine parameter는 batch by batch별로 optimize된다.

다음은 논문의 contribution이다.
1. Setting of fully test-time adaptation with only target data and no source data.
2. Examine entropy as an adaptation objective and propose tent.
3. Reach the SOTA at ImageNet-C.
4. For domain adaptation, tent is capable of online and source free adaptation for digit classification and semantic segmentation.
Setting

저자가 강조하는 것은 source free adaption 이다. 그런데 한가지 의문인 점은 이 논문 역시 pre-trained model을 사용하는데 이러한 것은 source data를 사용하는 것이 아닌가? 라는 생각을 하게 된다. 아마 저자가 주장하는 점은 기존 TTT는 test time adaption을 위해 SSL방법도 사용하고 새로 훈련시켜야하는데 이 tent는 아무 모델에서나 적용할 수 있다는 점이 아닐까 싶다.
Method: Test entropy minimization via feature mudulation
tent에 사용하는 모델은 다음과 같다.

training과정에 사용되는 모델은 확률적인 모델이며 미분가능해야하는 것이 필수적이다.
Entropy objective
model이 줄일라고하는 entropy는 모델의 예측값으로 다음과 같이 정의할 수 있으며$H(\hat{y}) = -\sum p(\hat{y}) log p( \hat{y})$ 해당 값을 줄이는 것이 목적인 것이다. 이는 일반적인 cross entropy와 동일하며 단순히 hard label이 없다는것이 다른점이다. 이유에 대해서는 single prediction에 대해서만 optimizing 하는 것은 trivial solution 을 야기할 수 있다고 한다(미리 말하자면 여기서 entropy를 줄이기 위해서 우리는 training과정에서 w, 즉 파라미터 값을 변경해나간다. 그러나 여기서는 파라미터를 거의 변경하지 않고 affine transform에 사용되는 parameter만 update한다).
여기서 entropy를 줄이는 것은 완전한 unsupervised 방식이라고 말한다. 당연하게도 예측 값에 대해서만 loss값을 취하기 때문인데 이러한 방법은 supervised task와 직접적으로 연결된다고 한다. 그러나 proxy task, 즉 self supervised learning같은 경우 supervised task와 직접적으로 연결되지 않는다고 하는다. 이에 대한 설명은 크게 하지 않는데 언급하기를 Too much progress on a proxy task could interfere with performance on the supervised task라고 한다. 따라서 proxy task를 선정할 때 신중을 가해야하며 balance가 중요하다고 하는데 여기서는 SSL을 사용하지 않으니 신경안써도 된다고 한다.
Modulation parameters
기본적으로 모델에서 사용하는 파라미터를 $\theta$라고 했을 때 해당 파라미터를 바꾸는 것은 모델이 diverge할 수 있다고한다(여기서 저자들도 써놓기를 $\theta$ is the only representation of the training/source data in our setting 이라고 말하면서 source data라는 표현을 쓴다. 즉 모델에 사용된 데이터들이 있긴하지만 새로 훈련을 시키지 않아도 된다라는 것을 의미하는 거 같다).
모델의 파라미터를 업데이트 하는 것이 아니라 feature modulation만 업데이트 한다고 말한다.

normalization 에 사용되는 인자값들은 배치 데이터의 통계량이고 transformation에 사용되는 파라미터는 배치정규화 layer에서 사용되는 파라미터이다. 해당 파라미터 2개가 loss를 통해 update되는 것이다. 따라서 test과정에서는 모델에서 사용한 배치정규화 layer들에 대해서만 다시 학습하는 것이라고 볼 수 있다.
Algorithm
test에서의 최적화 과정에서 배치정규화에 사용되는 파라미터를 모으고(모은다는 것이 무슨의미인지는 잘 모르겠다) 기존의 파라미터인 $\theta$ 는 바뀌지 않으며 훈련 때 사용되었던 통계량값은 버려진다고 한다. 그리고 보통 이러한 최적화 과정은 1번만 적용되고 이렇게 최적화된 정규화 파라미터는 다음 배치에 대해서만 적용이 된다고 한다
--> 즉 한번 요약해보자면, TTT를 한번 공부했던 사람이라면 약간 혼란이 올 수 있다. Test 데이터에 대해 훈련을 하고, 이에 대한 정확도를 산출하는 것이 아니라, 여기서는 Test 데이터에 대해서 최적화 과정만 거치고 이에 대한 영향은 다음 배치에 미치는 것이다. 물론 정확도를 산출하기는 한다.
Result

논문에서는 결과에 대한 figure가 많기는 한데 성능이 다 좋다고 한다.
아래는 공식 github에서 사용된 코드이다
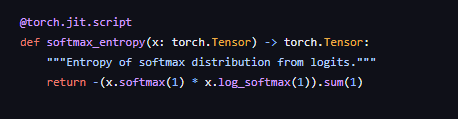
loss에 대해서는 데이터의 모든 확률값에 대해 loss를 산출하는 것을 확인할 수 있다.

모델 안에 있는 배치정규화에 대해서 만져주는 코드이다.

위 본문에서 affine 파라미터에 대해서 모은다는 표현이 코드에 이렇게 구현이 된 거 같다.

모은 파라미터를 활용해 다음 배치에서 최적화를 위해 사용한다. 코드가 조금 많아 직접보는 걸 추천한다.


