
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- dann paper
- 딥러닝손실함수
- dcgan
- UnderstandingDeepLearning
- CycleGAN
- Entropy Minimization
- SSL
- 백준 알고리즘
- mme paper
- shrinkmatch paper
- cifar100-c
- BYOL
- simclrv2
- CoMatch
- mocov3
- ConMatch
- semi supervised learnin 가정
- Pseudo Label
- GAN
- 컴퓨터구조
- remixmatch paper
- Pix2Pix
- CGAN
- 최린컴퓨터구조
- shrinkmatch
- Meta Pseudo Labels
- adamatch paper
- tent paper
- conjugate pseudo label paper
- WGAN
- Today
- Total
Hello Computer Vision
LeNet(1998), AlexNet(2012) 구조 리뷰 본문
이번 동아리에서 GAN스터디에 들어갔는데 본격적으로 GAN모델들을 살펴보기 전에
CV에 관해 간략하게 스터디를 하기로 했는데 내가 담당하였다.
그래서 발표한 내용들을 중심으로 이미지 분류에서 획을 그은 모델들을 소개하려고한다.
먼저 1998년에 발표된 LeNet.
우리가 현재 쓰는 Convolutional Layer 들을 기본적으로 쌓은 모델이다.
기존에 이미지 분류를 할 때는 Convolutional Layer를 쌓는 것이 아니라 단순 Multi Linear Layer들을 쌓았다면 Lenet에서는 Conv Layer통해 이미지 분류를 하였다.
Convolutional Neural Network는 기본적으로 Linear Network 보다 파라미터 계산량에서 적으며 Locality, stationarity 라는 특징들이 있다.
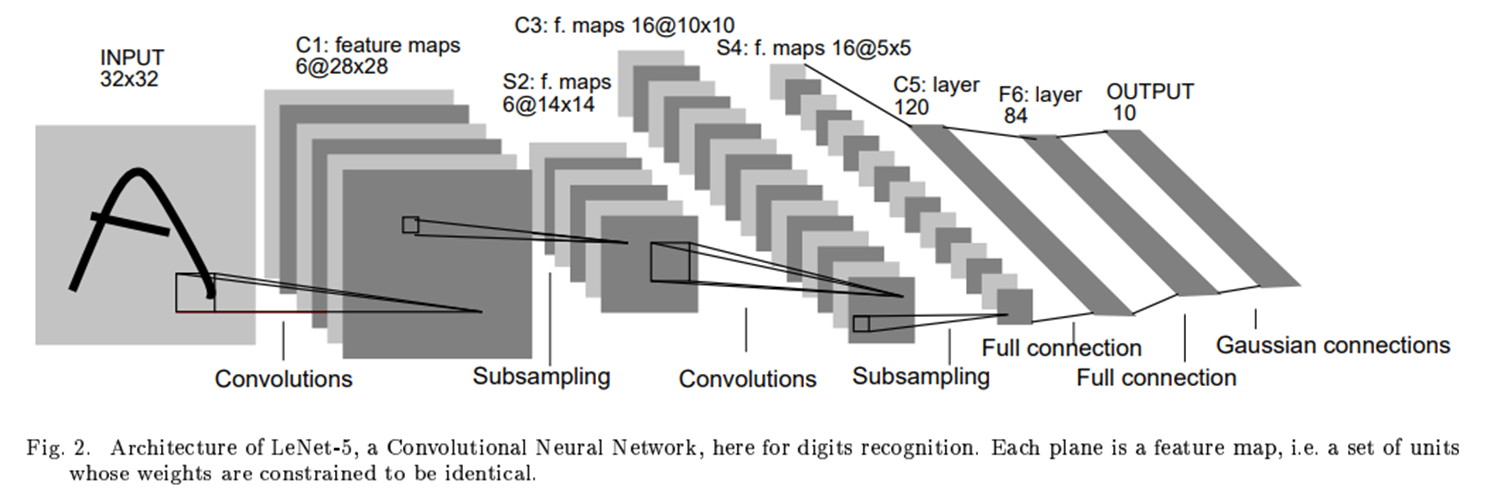
층을 깊게 쌓지 않았으며 각 Convolutional layer를 지날 때마다 Average Pooling 을 사용하였다.
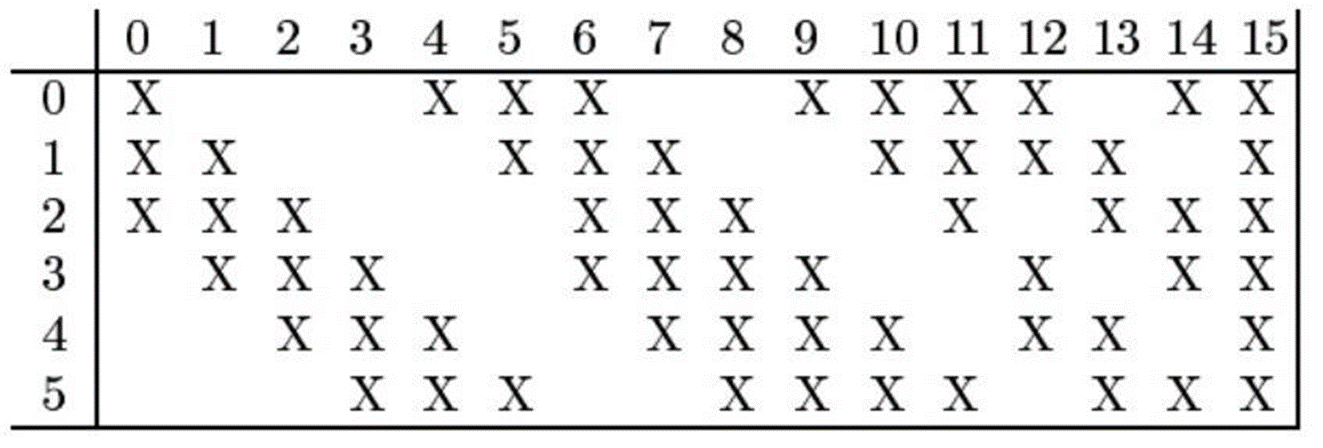
그리고 Lenet 모델만의 특별한 기법이 사용되었는데 사진이 이를 간단하게 설명해준다.
현재 Conv layer들을 쌓는다면 다음 층에 있는 피쳐맵들에게 연결이 되는데 LeNet에서는
다 연결하지 않고 첫번째 레이어의 피쳐맵은 두번째 레이어의(0,4,5,6,9,10,11,12,14,15) 번째 피쳐맵들과만 연결을 하였다. 첫번째 레이어의 두번째 피쳐맵은 첫번째 피쳐맵과는 다르게 연결을 한 모습을 알 수 있다.
이는 symmetry를 깨줌과 동시에 다양한 조합으로 섞이면서 global feature가 나타나기를 기대하면서 이러한 기법을 쓴다고 되어있다. 하지만 이러한 기법은 LeNet에서만 사용된다.
LeNet 구조를 작성해보았다.
Lenet5 = Sequential()
Lenet5.add(ZeroPadding2D(padding = 2))
Lenet5.add(Conv2D(filters = 6, kernel_size = 5, padding = 'valid', strides = 1, activation = 'tanh'))
Lenet5.add(AveragePooling2D(pool_size = 2, strides = 2))
Lenet5.add(Conv2D(filters = 16, kernel_size = 5, padding = 'valid', strides = 1, activation = 'tanh'))
Lenet5.add(AveragePooling2D(pool_size = 2, strides = 2))
Lenet5.add(Flatten())
Lenet5.add(Dense(units = 120, activation = 'tanh'))
Lenet5.add(Dense(units = 84, activation = 'tanh'))
Lenet5.add(Dense(units = 10, activation = 'softmax'))
Lenet5.build(input_shape = (None, 28, 28, 1))이것이 LeNet의 구조이며 keras 로 작성해보았다.
두번째 모델을 2012년에 발표된 AlexNet이다.
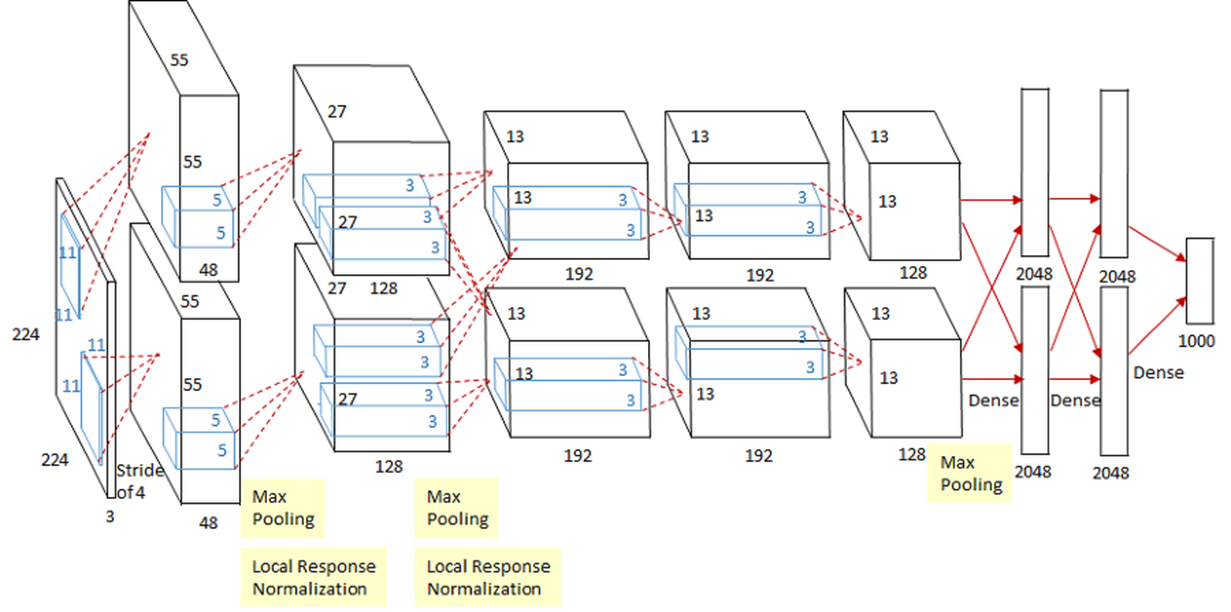
이것이 AlexNet의 구조이며 ImageNet 대회에서 84%의 성능을 기록하며 그 해 1위를 차지하였다.
구조적인 면에서는 기존에 소개하였던 LeNet 과 다르지 않으며 특징이라면 GPU를 사용해 훈련한 것이 특징이다.
또한 MaxPooling 을 사용하였으며 11x11, 5x5, 3x3 의 다양한 kernel을 사용한 것을 확인할 수 있는데 아마 이때는 커널 크기과 성능에 대해 정확한 상관관계나 인과관계를 몰라서 다양하게 사용한 것으로 생각해본다.
(2014년에 발표된 GoogleNet도 비슷한 맥락으로 inception Module을 사용한 것이 아닐까 생각한다.)
AlexNet을 훈련할 때는 데이터 증강, Momentum, 드롭아웃 등 다양한 기법들을 사용하였으며
gradient vanishing 문제를 해결하기 위해 이 전까지는 활용하지 않았던 ReLU 활성화 함수를 사용한다.
다음이 AlexNet 구조이다.
alexnet = Sequential()
alexnet.add(keras.Input(shape=(x_train.shape[1:]))) #x_train :shape : 32, 32, 3
alexnet.add(layers.Resizing(224,224, interpolation = 'bilinear'))
alexnet.add(Conv2D(96, (11,11), strides = (4,4), activation = 'relu', padding = 'same'))
alexnet.add(MaxPool2D((3,3),strides = 2))
alexnet.add(BatchNormalization())
alexnet.add(Conv2D(256, (5,5), strides = 1, activation = 'relu', padding = 'same'))
alexnet.add(MaxPool2D((2,2), strides = 2))
alexnet.add(BatchNormalization())
alexnet.add(Conv2D(384, (3,3), strides = 1, activation = 'relu', padding = 'same'))
alexnet.add(Conv2D(384, (3,3), strides = 1, activation = 'relu', padding = 'same'))
alexnet.add(Conv2D(256, (3,3), strides = 1, activation = 'relu', padding = 'same'))
alexnet.add(MaxPool2D((3,3), strides = 2))
alexnet.add(BatchNormalization())
###################################
alexnet.add(Flatten())
alexnet.add(Dense(4096, activation = 'relu'))
alexnet.add(Dropout(0.5))
alexnet.add(Dense(4096, activation = 'relu'))
alexnet.add(Dropout(0.5))
alexnet.add(Dense(10, activation = 'softmax'))마찬가지로 케라스로 작성해보았으며 구조적인 면에서는 LeNet 과는크게 다른 점이 없음을 확인할 수 있다.
정리
LeNet은 간단하지만 이미지 분류에 CNN을 사용하였다는 것으로 큰 의의가 있다.
AlexNet은 LeNet과 구조는 비슷하지만 다양한 기법, ReLU사용 등을 사용해 좋은 성능을 보였다.
'딥러닝' 카테고리의 다른 글
| 비전공생의 Backpropagation(역전파) 직접 손으로 해보기 (0) | 2022.11.09 |
|---|---|
| 비전공생의 Gradient Descent(경사 하강법)살펴보기 (0) | 2022.11.09 |
| ResNet(2015) 구조 리뷰 (0) | 2022.10.25 |
| GoogleNet(2014) 구조 리뷰 (0) | 2022.10.23 |
| VGGNet(2014) 구조 리뷰 (0) | 2022.10.22 |



